一种面向不平衡数据集的数据处理方法
本发明涉及机器学习领域,特别是数据挖掘领域,尤其涉及不平衡数据集的特征选择和数据生成。
背景技术:
1、在实际的机器学习任务中,数据集通常是不平衡的,即某些类别的样本数量远远少于其他类别。这种情况会对分类器的性能产生负面影响,尤其是对于少数类类别的识别效果。
2、目前,研究人员主要从数据层面和算法层面入手解决不平衡数据分类问题。在数据层面上,主要采用人为干预的方法,通过调整不平衡数据的分布来获得相对平衡的数据集。而在算法层面上,旨在调整传统的分类算法或提出对现有分类思想进行优化和改进,使其适应不平衡数据集的内在特征,从而提高对少数类样本的识别能力。
3、针对不平衡的数据集,传统的特征选择方法只以精度为优化目标,无法充分考虑数据的分布情况。这种方法容易导致对多数类有利的特征被偏重考虑,从而无法有效解决少数类的识别问题。因此,需要设计适用于不平衡数据集的特征选择方案,以获取适用于不平衡数据集的最佳特征。
技术实现思路
1、技术问题:本发明提供了一种面向不平衡数据集的特征选择与数据生成方法,旨在提高学习算法对少数类的识别能力。
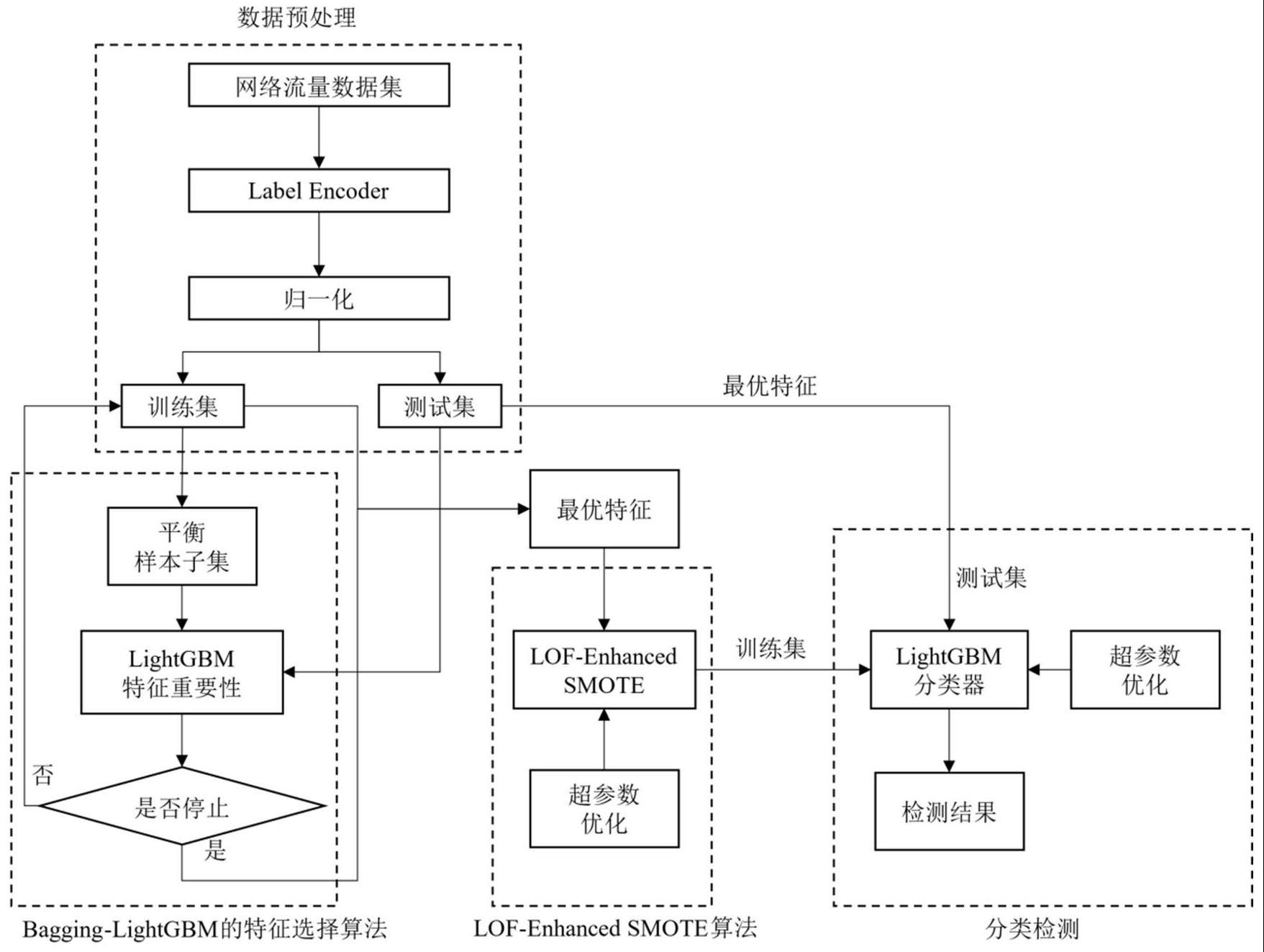
2、针对传统特征选择方法只以精度为优化目标而忽略数据分布情况的问题,本发明提供一种基于bagging-lightgbm的特征选择算法。该算法通过对每个类别的样本进行有放回抽样,形成多个样本子集,从而使样本子集中每个类别的样本个数大致均衡,提高学习算法对少数类样本的识别能力。
3、同时,本发明还提供一种不平衡数据集的数据生成方法lof-enhanced smote算法。该算法结合lof(局部异常因子,local outlier factor)算法和不同的概率分布函数,通过启发式选择的参数生成人工样本,使得生成的人工样本不受边界噪声的影响,同时能够更多地保证生成样本的多样性。相较于传统的borderlinesmote算法,lof-enhancedsmote算法在生成人工样本时使用局部异常因子算法剔除边界噪声,并引入不同的概率分布函数以保证生成样本的多样性,从而提高分类器的性能。
4、因此,本发明提供的特征选择和数据生成方法可以有效地应对不平衡数据集的问题,提高学习算法对少数类的识别能力,具有实用性和先进性,适用于机器学习、数据挖掘等领域。
5、技术方案:本发明提供了一种面向不平衡数据集的数据处理方法,包括:
6、bagging-lightgbm的不平衡数据集特征选择算法:面向不平衡数据集的特征选择算法;
7、lof-enhanced smote算法:面向不平衡数据集的数据生成算法。
8、所述bagging-lightgbm的不平衡数据集特征选择算法包括:
9、(1)对于每一轮采样,从训练集d中随机选取m个样本,得到一个平衡的数据集di,其中每个类别的样本个数大致相等。重复这个过程k次。
10、(2)在每个平衡的数据集di中,使用lightgbm模型对子集样本进行训练,并得到每个特征的重要性值。这个过程得到k个特征重要性向量,分别为i(1),i(2),...,i(k),其中每个向量的长度为p,p为特征数目。
11、(3)将k个特征重要性向量合并为一个特征重要性矩阵i=[i(1),i(2),...,i(k)],其中i的大小为p×k,p为特征数目。
12、(4)计算每个特征的平均重要性值即对于每个特征i,将其在矩阵i中的k个值进行平均:
13、
14、(5)对特征按照平均重要性值进行排序,选取前q个特征作为最终的特征集合,其中q是需要选择的特征数目。
15、所述lof-enhanced smote算法包括:
16、(1)对于每个少数类样本xi∈minoritysamples,使用nneighbors计算其局部密度lof得分。
17、(2)根据设定的阈值threshold,将lof得分小于等于threshold的样本划分为边界样本(boundarysamples),大于threshold的样本划分为噪声样本(noisesamples)。
18、(3)对于每个边界样本xi∈boundarysamples,使用kneighbors找到其kneighbor个最近邻样本点x1,x2,...,xkneighbors。
19、(4)对于每个边界样本xi∈boundarysamples,对于其每个最近邻样本点xj∈xi的kneighbors个最近邻样本点,执行以下步骤:
20、a.计算diff=xj-x;
21、b.基于设定的不同的概率分布函数distributionkind,生成一个随机向量r;
22、c.生成合成样本x′=x+r·diff;
23、d.将x′添加到合成样本集syntheticsamples中。
24、(5)重复执行步骤(4),直到生成新样本数达到设定的n。
25、有益效果:从以上技术方案可以看出,本发明具有以下优点:
26、本发明提供了一种面向不平衡数据集的特征选择与数据生成方法,解决了传统的特征选择方法只以精度为优化目标,无法充分考虑数据的分布情况以及传统的数据生成方法对噪声数据敏感的问题,并引入不同的概率分布函数以保证生成样本的多样性。
27、本发明的基于bagging-lightgbm的特征选择算法,采用多次有放回抽样来构建样本子集,从而使得每个样本子集中每个类别的样本个数大致均衡,以弥补数据集不平衡的影响。通过多次随机抽样,可以使样本子集的有偏分布得到有效地平衡,同时可以让不同类别区分能力的特征互补,提高模型对少数类样本的识别能力。
28、smote是针对不平衡数据集的一种常用的算法,但是smote算法有内在缺陷。首先它可能对噪声数据进行生成,从而生成新的噪声数据。其次,smote使用线性插值生成数据,没有考虑到原始数据的分布。本发明的lof-enhanced smote算法,通过引入lof异常值检测算法,用于检测噪声,并基于设定的概率分布函数生成随机向量r,替换掉smote算法中的随机值r。smote算法的r是随机数,这里的r使用概率分布函数生成。lof-enhanced smote算法通过引入lof算法,可以更加准确地计算每个数据点的密度,从而有效地剔除噪声样本的影响。其次lof-enhanced smote使用设定的概率分布函数合成新的样本点。这种方法可以增加对少数类样本的关注程度,并在生成新样本时更加准确地反映原始数据集中的数据分布。
技术特征:
1.一种面向不平衡数据集的数据处理方法,其特征在于,该方法包括:采用bagging-lightgbm算法提取不平衡数据集的特征,进而生成采样数据;
2.根据权利要求1所述的一种面向不平衡数据集的数据处理方法,其特征在于,采用lof-enhanced smote算法生成采样数据,具体步骤包括:
3.根据权利要求2所述的一种面向不平衡数据集的数据处理方法,其特征在于,所述概率分布函数distributionkind为高斯分布函数、伽马分布函数、拉普拉斯分布函数中的一种或几种。
4.权利要求1-3任一所述面向不平衡数据集的数据处理方法在入侵检测领域的应用。
技术总结
本发明提供一种面向不平衡数据集的数据处理方法,通过对每个类别的样本进行有放回抽样,形成多个样本子集,从而使样本子集中每个类别的样本个数大致均衡,提高学习算法对少数类样本的识别能力。本发明结合LOF算法和不同的概率分布函数,通过启发式选择的参数生成人工样本,使得生成的人工样本不受边界噪声的影响,同时能够更多地保证生成样本的多样性。相较于传统的BorderlineSMOTE算法,本发明在生成人工样本时使用局部异常因子算法剔除边界噪声,并引入不同的概率分布函数以保证生成样本的多样性,从而提高分类器的性能。本发明可以有效地应对不平衡数据集的问题,提高学习算法对少数类的识别能力,适用于机器学习、数据挖掘等领域。
技术研发人员:胡静,宋铁成,张状状,陈然,夏玮玮,燕锋,沈连丰
受保护的技术使用者:东南大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!