一种基于提示学习的事件因果关系判别方法及装置
本申请涉及事件因果领域,尤其涉及一种基于提示学习的事件因果关系判别方法及装置。
背景技术:
1、目前用于分析事件因果关系的技术大概分为两种方向,一是通过语言模型进行文本因果特征进行提取,用于事件因果关系分类,二是通过外部知识库进行数据增强,增加训练数据的多样性,从而提高训练模型的在事件因果关系分析中的判别能力。
2、然而,通过语言模型进行文本因果关系特征提取需要依靠模型有较强的因果推理能力,然而目前常见参数量在几百万的模型捕捉因果特征的能力较差,并且由于下游任务和语言模型预训练任务的不一致性,导致使用语言模型加微调的迁移学习方法在迁移过程中有信息损失,使得语言模型的语言能力没有得到充分的挖掘。
3、通过利用外部知识库进行数据增强的方法,这类方法通常通过一些文本规则来检测文本中因果事件对的位置然后再进行相关同义词的替换等方式,增大了语料的数量。但是因果关系是一种复杂的关系,并且由于自然语言表达的多样性的特征,导致通过知识库进行简单数据增强,只是增加了具备相同文本特征的语料多样性,相当于让模型在一定数量具备相同语言文法特征下进行不断学习,并没有提高模型对自然语言文本中因果知识的泛化能力。
技术实现思路
1、针对上述问题,提出了一种基于提示学习的事件因果关系判别方法及装置。
2、本申请第一方面提出一种基于提示学习的事件因果关系判别方法,包括:
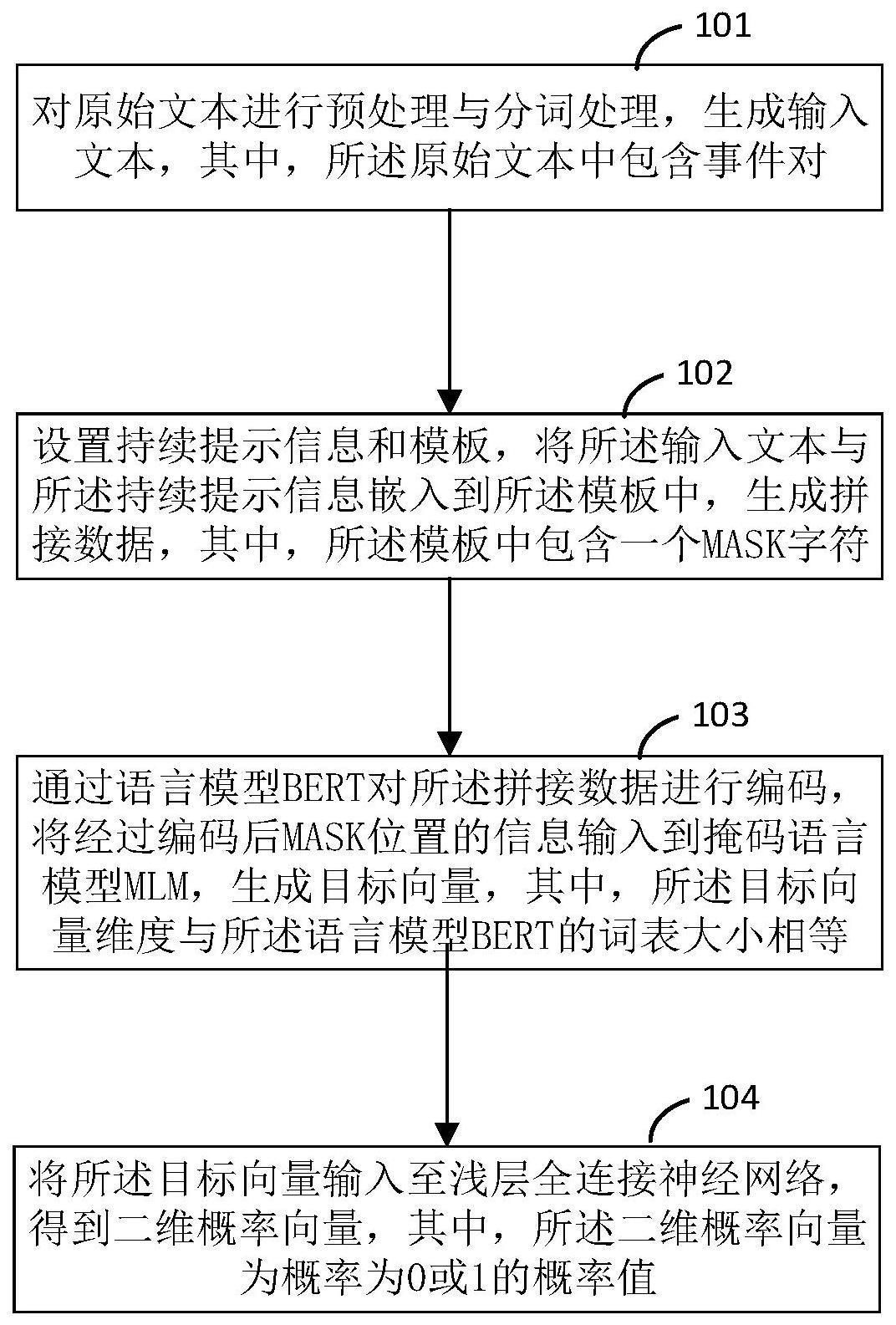
3、对原始文本进行预处理与分词处理,生成输入文本,其中,所述原始文本中包含事件对;
4、设置持续提示信息和模板,将所述输入文本与所述持续提示信息嵌入到所述模板中,生成拼接数据,其中,所述模板中包含一个mask字符;
5、通过语言模型bert对所述拼接数据进行编码,将经过编码后mask位置的信息输入到掩码语言模型mlm,生成目标向量,其中,所述目标向量维度与所述语言模型bert的词表大小相等;
6、将所述目标向量输入至浅层全连接神经网络,得到二维概率向量,其中,所述二维概率向量为概率为0或1的概率值。
7、可选的,所述对原始文本进行预处理与分词处理,生成输入文本,包括:
8、去除所述原始文本中的噪音信息,其中,所述噪音信息包括多余的标点符号与感叹词;
9、将经过去除处理后的所述原始文本转化为适用于所述语言模型bert的输入格式。
10、可选的,所述设置持续提示信息和模板,包括:
11、完全随机初始化q个向量充当基础提示信息,其中,每个向量的维度等于语言模型词向量的维度,公式化为:
12、θp=[p0,…,pq];
13、其中,θp为所述基础提示信息,q为所述基础提示信息的末位;
14、选取lstm网络和浅层全连接神经网络mlp充当提示信息生成器,对所述基础提示信息进行优化,以生成持续提示信息,其中,所述持续提示信息可表示为:
15、
16、当所述持续提示信息为[pi,…,pq],输入文本xcomtext={x0,...,xm},所述事件对中原因事件e1={xi,...,xj},结果事件e2={xk,...,xn}时,所述模板可表示为:
17、t={[po,…,pk],xcomtext,[pi+1,…,m],[mask],e1,[pm+1,…,pq],e2},
18、其中,m为所述输入文本的文本长度,i表示所述原因事件从所述输入文本的第i个位置开始,j表示所述原因事件从所述输入文本的第j个位置结束,k表示所述结果事件从所述输入文本的第k个位置开始,n表示所述结果事件从所述输入文本的第n个位置结束。
19、可选的,所述将所述输入文本与所述持续提示信息嵌入到所述模板中,生成拼接数据,包括:
20、将所述输入文本xcomtext、所述原因事件e1与所述结果事件e2转换为对应的向量表示,其中,所述输入文本xcomtext的向量表示为ecomtext={e0,...,em},所述原因事件e1的向量表示为e1={ei,...,ej},所述结果事件e2的向量表示为e2={ek,...,en};
21、将ecomtext、e1、e2与嵌入到所述模板t中,生成所述拼接数据,其中,所述拼接数据可表示为:
22、l={p0:i,ecomtext,pi+1:q,emask,e1,e2},
23、其中,emask为所述mask字符的向量表示。
24、可选的,所述通过语言模型bert对所述拼接数据进行编码,将经过编码后mask位置的信息输入到mlm,生成目标向量,包括:
25、在所述语言模型bert输出层出处,将所述拼接数据mask位置的向量emask提取并输入到所述mlm网络,生成目标向量,其中,所述目标向量每一个维度的值对应预测对应词汇的概率值。
26、可选的,所述方法,还包括:
27、若所述二维概率向量为概率为0的概率值,则所述输入文本中不存在因果关系;
28、若所述二维概率向量为概率为1的概率值,则所述输入文本中存在因果关系。
29、本申请第二方面提出一种基于提示学习的事件因果关系判别装置,包括:
30、去噪模块,用于对原始文本进行预处理与分词处理,生成输入文本,其中,所述原始文本中包含事件对;
31、嵌入模块,用于设置持续提示信息和模板,将所述输入文本与所述持续提示信息嵌入到所述模板中,生成拼接数据,其中,所述模板中包含一个mask字符;
32、处理模块,用于通过语言模型bert对所述拼接数据进行编码,将经过编码后mask位置的信息输入到mlm,生成目标向量,其中,所述目标向量维度与所述语言模型bert的词表大小相等;
33、输出模块,用于将所述目标向量输入至浅层全连接神经网络,得到二维概率向量,其中,所述二维概率向量为概率为0或1的概率值。
34、本申请的实施例提供的技术方案至少带来以下有益效果:
35、将提示学习方法应用于事件因果判别任务,并对提示学习方法进行改进,使用浅层全连接神经网络对包含类似语义的词的概率进行加权处理,完成自然语言文本中的二分类任务,具有实用性。
36、本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
技术特征:
1.一种基于提示学习的事件因果关系判别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述对原始文本进行预处理与分词处理,生成输入文本,包括:
3.根据权利要求2所述的方法,其特征在于,所述设置持续提示信息和模板,包括:
4.根据权利3所述的方法,其特征在于,所述将所述输入文本与所述持续提示信息嵌入到所述模板中,生成拼接数据,包括:
5.根据权利要求4所述的方法,其特征在于,所述通过语言模型bert对所述拼接数据进行编码,将经过编码后mask位置的信息输入到mlm,生成目标向量,包括:
6.根据权利要求5所述的方法,其特征在于,所述方法,还包括:
7.一种基于提示学习的事件因果关系判别装置,其特征在于,包括:
技术总结
本申请提出了一种基于提示学习的事件因果关系判别方法及装置,涉及事件因果领域,该方法包括:对原始文本进行预处理与分词处理,生成输入文本;设置持续提示信息和模板,将输入文本与持续提示信息嵌入到模板中,生成拼接数据,其中,模板中包含一个MASK字符;通过语言模型BERT对拼接数据进行编码,将经过编码后MASK位置的信息输入到掩码语言模型MLM,生成目标向量;将目标向量输入至浅层全连接神经网络,得到二维概率向量,其中,二维概率向量为概率为0或1的概率值。本申请将提示学习方法应用于事件因果判别任务,并对提示学习方法进行改进,使用浅层全连接神经网络对包含类似语义的词的概率进行加权处理,完成自然语言文本中的二分类任务,具有实用性。
技术研发人员:张威威,吴斌,胡琳梅
受保护的技术使用者:北京邮电大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!