基于多模态交互信息的虚拟人表情个性化生成方法与流程
本发明涉及人工智能领域,特别涉及基于多模态交互信息的虚拟人表情个性化生成方法。
背景技术:
1、在人工智能、虚拟现实等新技术浪潮的带动下,虚拟数字人制作过程得到有效简化,各方面性能获得飞跃式提升,开始从角色形象的数字化逐渐向行为交互化、思想智能化深入。以虚拟主播、虚拟员工等为代表的数字人成功进入大众视野,并以多元的姿态在影视、游戏、传媒、文旅、金融等众多领域大放异彩。以数字人为主角来制作图片、视频已能达到以假乱真的效果,但在交互场景中,考虑到硬件算力与用户体验,如何让数字人在实时交互时也拥有逼真的表现力成为很多应用场景的刚性需求。本文从合成人面部表现的角度入手,主要介绍融合多模态数据特征分析、个性化驱动的3d数字人唇部动作与面部表情的技术方案。
2、视觉表征在人类的言语感知中起着重要作用,例如在看电影时,如果角色的口型与声音不对应,会给观众带来“出戏”感。现有技术中,主流音频驱动的三维唇动算法主要针对通用模型,通过驱动面部的表情基或嘴唇部位相关的模型顶点来模拟说话时的口型,在这个过程中,会丢失包括韵律与情感在内的很多信息,数字人只能机械地展现音素对应的口型。面部表情也主要通过制作表情基动画,随机或按照固定顺序播放动画来驱动。上述方案中,缺乏对内容与情感的理解是数字人在对话时表现呆滞、僵硬的一个重要原因,导致数字人容易陷入恐怖谷效应。
技术实现思路
1、本发明的目的在于提供基于多模态交互信息的虚拟人表情个性化生成方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:基于多模态交互信息的虚拟人表情个性化生成方法,包括以下步骤:
3、步骤一:当用户与数字人对话,提出问题或聊天时,将用户语音发送到asr服务,提取音频特征后转化为文字信息;
4、步骤二:利用nlp对语音转文字的结果进行分析,通过深度学习模型解析出句子的逻辑结构和内容含义,抽取事件元素,在配置好的知识库中查找匹配,命中问题后给出回答文本;
5、步骤三:nlp的回答文本首先送到tts服务,经过语言学分析,由tacotron2语音合成模型生成文字对应的波形并拼接成完整的音频片段;
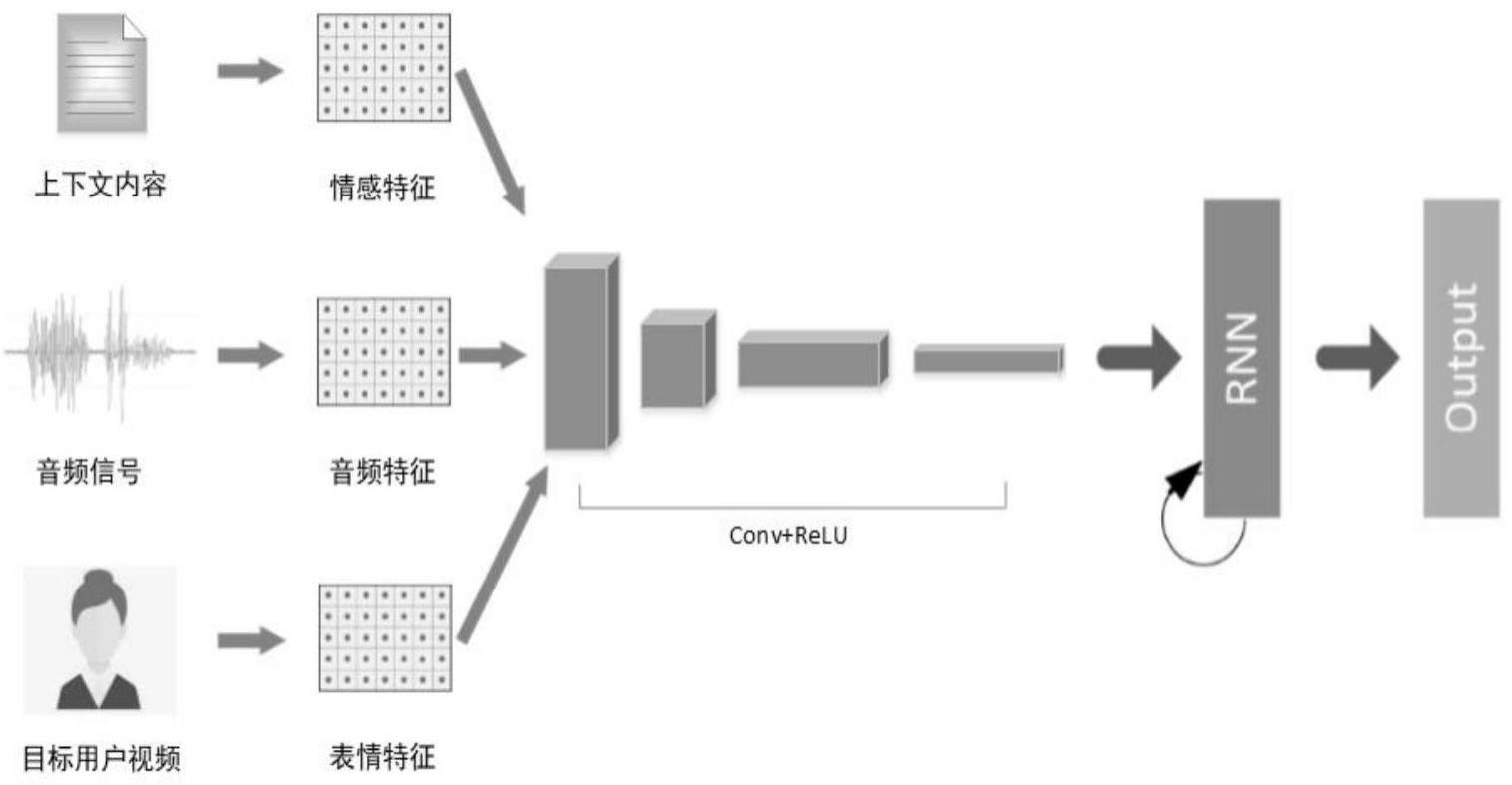
6、步骤四:对于每一句音频片段,结合该句的上下文,由textrcnn情感特征模型分析该段对体现什么情绪,同时用crnn音频特征提取模型处理音频,得到音频特征,通过预训练好的唇动与面部表情生成模型计算出一组基础唇部顶点位移和表情基数据;
7、步骤五:取一段目标用户朗读的视频,由cnn+fc表情特征模型提取出目标用户的表情特征,表情特征与上一步计算得到的基础唇部顶点位移和表情基数据进行融合,得到具有目标用户表情特征的个性化唇部顶点位移与表情基数据;
8、步骤六:用个性化的唇部顶点位移和表情基数据驱动数字人,使数字人能够一边说话一边做出对应的口型和表情,给予用户反馈。
9、优选的,在步骤一中,提取音频特征时,由dnn-ctc声学模型解析出字词,语言模型调整声学模型得到的不合逻辑的结果,转为一段通顺的文字后继续发送给nlp服务。
10、优选的,在步骤五中,通过目标用户的朗读视频提取表情特征可以预先操作,将提取好的表情特征作为参数配置记录下来,节约个性化表情迁移的时间,更快与基础唇部顶点位移与表情基融合。
11、优选的,当用户与数字人对话还可以提取情感特征和表情特征。
12、优选的,在输入情感特征、表情特征和音频特征时,训练数据集由成对的面部运动3d顶点数据和与之对齐的音频片段、以及对应的情感特征和表情特征组成;训练数据的采集与处理过程如下:需要准备内容涵盖多种情绪的文本,文本情绪识别网络提取不同情感特征,邀请多位被摄对象,请被摄对象有感情地朗读这些文本,用摄像头同时记录被摄对象朗读时的视频与音频,采集到的音视频数据通过上述情感特征提取网络、表情特征提取网络与音频特征提取网络分别提取出情感特征、表情特征与音频特征,再将视频图像通过2d跟踪与3d映射,将视频中被摄对象的面部肌肉运动对应到头部3d标准模型上,得到面部3d顶点位置数据,经过上述一系列处理后,将原始数据转化为训练数据集。
13、优选的,模型训练的位置损失函数定义为:
14、
15、速度损失函数定义为:
16、
17、其中x代表视频帧中头部3d模型的顶点位置,k是数据集中视频帧数量,t为无表情头部3d标准模型顶点位置,d代表模型输出,由一组唇部顶点位移数据和面部表情基数据组成。为了更精准地展现口型,唇部动作由模型嘴部区域每个顶点的位移来控制;对于面部表情来说,表情基比顶点驱动更具有通用性,且多个表情基结合足以展现某种情绪下对应的表情,因此本技术方案采用了唇部顶点位移与面部表情基数据结合的方式。
18、本发明的技术效果和优点:
19、本发明提出新的多模融合网络,能够融合情感特征、表情特征、音频特征等多模态数据,使网络在学习音频与唇部顶点关系的同时能够学习面部顶点如何适当变化来展现细腻的表情,模型输出由唇部顶点位置变化与面部表情基组合,既能保证口型的准确性,又能使表情丰富生动的同时节约性能,提高通用性,根据目标用户朗读视频提取目标用户的表情神态特征,输出带有目标用户个人表情特征的数据来驱动数字人,对于不同目标用户,数字人可以展现出不同的、个性化的表现。
技术特征:
1.基于多模态交互信息的虚拟人表情个性化生成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于多模态交互信息的虚拟人表情个性化生成方法,其特征在于,在步骤一中,提取音频特征时,由dnn-ctc声学模型解析出字词,语言模型调整声学模型得到的不合逻辑的结果,转为一段通顺的文字后继续发送给nlp服务。
3.根据权利要求1所述的基于多模态交互信息的虚拟人表情个性化生成方法,其特征在于,在步骤五中,通过目标用户的朗读视频提取表情特征可以预先操作,将提取好的表情特征作为参数配置记录下来,节约个性化表情迁移的时间,更快与基础唇部顶点位移与表情基融合。
4.根据权利要求1所述的基于多模态交互信息的虚拟人表情个性化生成方法,其特征在于,当用户与数字人对话还可以提取情感特征和表情特征。
5.根据权利要求1所述的基于多模态交互信息的虚拟人表情个性化生成方法,其特征在于,在输入情感特征、表情特征和音频特征时,训练数据集由成对的面部运动3d顶点数据和与之对齐的音频片段、以及对应的情感特征和表情特征组成;训练数据的采集与处理过程如下:需要准备内容涵盖多种情绪的文本,文本情绪识别网络提取不同情感特征,邀请多位被摄对象,请被摄对象有感情地朗读这些文本,用摄像头同时记录被摄对象朗读时的视频与音频,采集到的音视频数据通过上述情感特征提取网络、表情特征提取网络与音频特征提取网络分别提取出情感特征、表情特征与音频特征,再将视频图像通过2d跟踪与3d映射,将视频中被摄对象的面部肌肉运动对应到头部3d标准模型上,得到面部3d顶点位置数据,经过上述一系列处理后,将原始数据转化为训练数据集。
6.根据权利要求5所述的基于多模态交互信息的虚拟人表情个性化生成方法,其特征在于,模型训练的位置损失函数定义为:
技术总结
本发明公开了基于多模态交互信息的虚拟人表情个性化生成方法,包括当用户与数字人对话,提出问题或聊天时,将用户语音发送到ASR服务,提取音频特征后转化为文字信息,利用NLP对语音转文字的结果进行分析,通过深度学习模型解析出句子的逻辑结构和内容含义,抽取事件元素,在配置好的知识库中查找匹配,命中问题后给出回答文本。本发明提出新的多模融合网络,根据目标用户朗读视频提取目标用户的表情神态特征,输出带有目标用户个人表情特征的数据来驱动数字人,对于不同目标用户,数字人可以展现出不同的、个性化的表现。
技术研发人员:王欣艳,房玉东,魏永锋,孙宁
受保护的技术使用者:应急管理部大数据中心
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!