结构化敏感数据识别方法及装置与流程
本公开涉及信息安全领域,尤其涉及结构化敏感数据识别。
背景技术:
1、随着信息技术的飞速发展,信息安全问题逐渐备受关注,而且多起信息安全事故给个人和社会带来了非常严重的影响,尤其是敏感数据的泄露,甚至能直接影响国家安全。
2、目前,敏感数据防泄漏的关键技术包括:敏感数据识别、敏感数据标记、敏感数据阻断、销毁和策略管理等。其中敏感数据识别是敏感数据防泄漏方案的前提,也会其中最重要的环节,只有精准的识别出敏感数据才能防止这些敏感数据泄露。
3、早期的敏感数据识别技术通常采用关键词匹配的方法,首先需要数据分析师根据其主观意识筛选出敏感数据的关键词,作为词表和识别的依据,然后根据多模匹配算法将待测文本与词表进行比对,并根据事先设定的阈值来判断待测文本是否含有敏感数据,若大于阈值,则还有敏感数据,否则,没有敏感数据。多模匹配算法以ac(aho-corasick)算法为代表,该算法通过有限状态机将字符比较转化为状态转移,从而完成对字符串的匹配。但该方法识别精度低,在数据字典不完整或建立有误的情况下,容易造成敏感数据查找失败。
4、对于敏感数据的识别,目前主要是基于文本的识别。基于文本的识别算法主要有三种:第一种是基于概率和信息理论的分类算法,如朴素贝叶斯算法(naive bayes,nb),最大熵算法;第二种是基于标准的rocchio分类算法的tf-idf权值计算方法,如包括tf-idf算法,knn等;第三种是基于知识学习的算法,如支持向量机(support vector machine,vsm)算法,循环神经网络模型(recurrent neural network,rnn)的算法等。
5、其中,基于知识学习的算法,是随着机器学习理论、深度学习理论的进步逐步发展的一类识别方法。
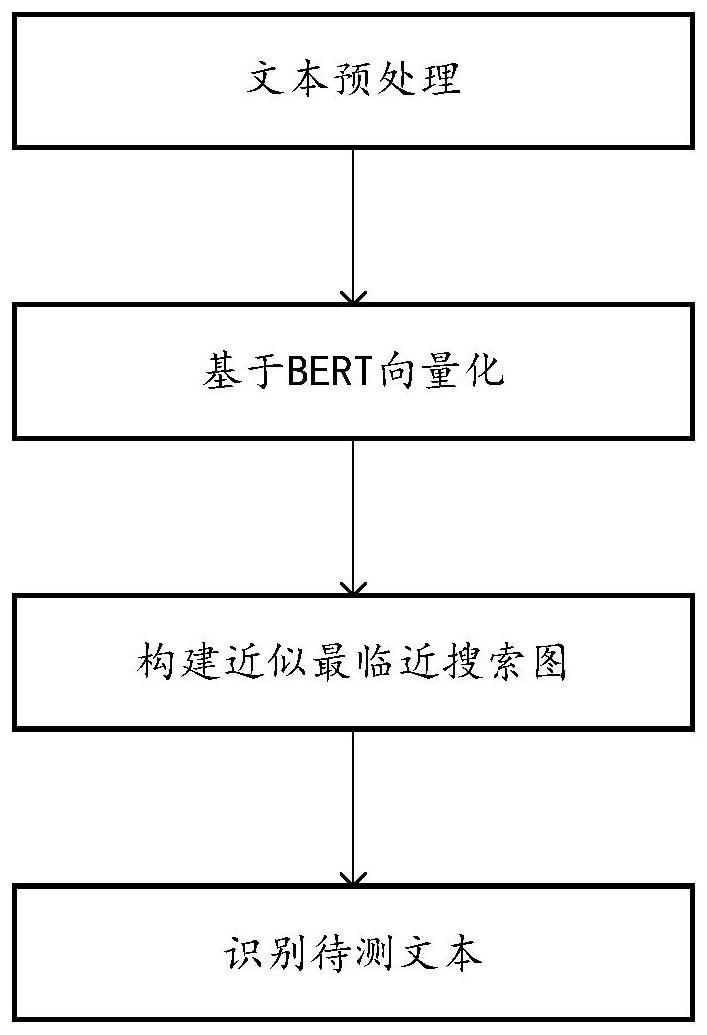
6、例如,基于bert模型和k近邻的敏感信息识别方法,如图1所示,主要包括文本预处理、基于bert向量化、构建近似最邻近搜索图、识别待测文本四部分。其中文本预处理即将每条文本进行去噪处理,并将文本标注为敏感信息、非敏感信息;基于bert向量化即将敏感信息的文本和非敏感信息的文本输入至经压缩的bert模型中,得到多条敏感信息的向量表征和多条非敏感信息的向量表征;构建近似最邻近搜索图即将敏感信息的向量表征为正类数据、以非敏感信息的向量表征为负类数据,构建基于近似最近邻搜索算法的近似最邻近搜索图并保存;识别待测文本即将待测文本的向量表征输入至近似最邻近搜索图,搜索得到近似最近邻的k个节点,判断节点属性及根据该条待测文本的敏感度权重,修正其敏感度值后,判断是否为敏感信息。
7、上述方法主要存在两个缺点:
8、1.由于现实样本数据中的敏感数据相对于非敏感数据而来属于极少数,因此存在样本不平衡问题,存在极小数据问题,从而容易导致模型容易过拟合,即模型不仅仅容易在训练集上出现过拟合的问题,而且也可能在验证集上出现过拟合问题,最终造成模型的稳定性降低。
9、2.构建近似最邻近搜索图的过程中需要进行大量的向量距离计算,从而导致极大的计算开销。除此之外,在需要向向量集合中增加新的向量时,通常需要对搜索图进行重新构建,从而严重影响了向量的插入效率。
技术实现思路
1、本公开提供了一种结构化敏感数据识别方法、设备以及存储介质。
2、根据本公开的第一方面,提供了一种结构化敏感数据识别模型的训练方法。该方法包括:获取结构化数据集,对所述结构化数据集进行预处理;对预处理后的结构化数据集进行属性简单匹配,分别生成属性简单匹配成功的结构化数据的词向量和属性简单匹配失败的结构化数据的词向量;将所述属性简单匹配成功的结构化数据的词向量投入基于imp_gan的敏感数据生成模块进行敏感数据生成;利用生成的所述敏感数据与所述结构化数据集的词向量进行混合,作为tabnet敏感识别模型的训练样本,对所述tabnet敏感数据识别模型进行训练。
3、根据本公开的第二方面,提供了一种结构化敏感数据识别方法,所述方法包括对待识别词进行属性简单匹配;生成属性简单匹配失败的结构化数据集的词向量;将所述词向量投入根据上述方法预先训练得到的tabnet敏感数据识别模型,输出词汇对应的敏感度。
4、根据本公开的第三方面,提供了一种结构化敏感数据识别装置,包括:属性简单匹配模块410,用于对待识别词进行属性简单匹配;向量生成模块420,用于生成属性简单匹配失败的结构化数据集的词向量;敏感度识别模块430,用于将所述词向量投入根据上述方法预先训练得到的tabnet敏感数据识别模型,输出词汇对应的敏感度。
5、根据本公开的第四方面,提供了一种电子设备。该电子设备包括:存储器和处理器,所述存储器上存储有计算机程序,所述处理器执行所述程序时实现如以上所述的方法。
6、根据本公开的第五方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如根据本公开的第一方面和/或第二方面的方法。
7、应当理解,
技术实现要素:
部分中所描述的内容并非旨在限定本公开的实施例的关键或重要特征,亦非用于限制本公开的范围。本公开的其它特征将通过以下的描述变得容易理解。
技术特征:
1.一种结构化敏感数据识别模型的训练方法,包括:
2.根据权利要求1所述的方法,其中,所述预处理包括:
3.根据权利要求2所述的方法,其中,所述对预处理后的结构化数据集进行属性简单匹配包括:
4.根据权利要求3所述的方法,其中,所述基于imp_gan的敏感数据生成模块为基于imp_gan的生成式对抗网络的生成模型。
5.根据权利要求1所述的方法,其中,所述生成模型为多个,采用皮尔逊相关系数来迫使不同的生成模型学习不一样的流形。
6.根据权利要求1所述的方法,其中,利用生成的所述敏感数据与所述结构化数据集的词向量进行混合,作为tabnet敏感识别模型的训练样本,包括:
7.一种结构化敏感数据识别方法,所述方法包括:
8.一种结构化敏感数据识别装置,包括:
9.一种电子设备,包括:
10.一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行根据权利要求1-7中任一项所述的方法。
技术总结
本公开的实施例提供了一种结构化敏感数据识别方法及装置。所述方法包括对待识别词进行属性简单匹配;生成属性简单匹配失败的结构化数据集的词向量;将所述词向量投入预先训练得到的TabNet敏感数据识别模型,输出词汇对应的敏感度。以此方式,解决了当前敏感数据识别方法中,样本数据不平衡导致过拟合的问题以及GAN只学习一种或几种数据流形导致的模型崩溃问题。
技术研发人员:孙燕杰,孔维玉,袁开国,付海涛,司大鹏,石明磊,陆毅远
受保护的技术使用者:上海速丰通联科技集团有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!