一种基于域适应的漫画视频生成方法
本发明涉及漫画视频生成技术,特别涉及基于域适应的人脸视频驱动的漫画视频生成技术。
背景技术:
1、随着深度学习的发展,人脸风格化的工作受到了人们的广泛关注。现如今,直播、短视频成为人们娱乐生活的主流,视频风格转换也有着巨大的市场和商业应用价值。将风格迁移算法由图像拓展到视频的最自然的方式就是利用图像风格迁移的技术,逐帧完成视频的转换,但是这样很难保证视频帧间风格的一致性,并且通常会出现抖动和不连续的问题。这主要是由于单张图片风格转换的不稳定性所造成的。
2、目前人脸漫画视频的生成方法主要包含三类。第一类是基于关键帧提取的方法,这类方法首先选出最具有代表性的一帧作为关键帧,对其进行风格迁移后,通过提取其他帧的特征,来对风格迁移后的关键帧进行插值。这种方法需要针对每个人的对应视频进行优化迭代学习,效率较低,并且难以约束关键帧的选择标准。第二类通过提取和传播短时的时序信息来保证风格化视频的连续性和稳定性,但这种方法需要在结果的稳定性和清晰度上进行权衡。第三类基于漫画建模,使用参数来表征表情,将人脸视频中的表情动作运动提取出来并进行量化,将对应的漫画也按照相同的运动参数形成视频。此类方法实现起来非常复杂,计算量很大,对漫画进行建模和参数量化也存在一定的误差。
3、2019年发表在neurips的图像动态化方法为图像到视频的生成提供了一种新的思路。图像动态化会根据驱动视频的运动对源图像中的对象进行动态化来生成视频序列。但针对漫画数据集数量较少,并且没有对应的视频数据的问题,需要先在人脸视频数据集中完成图像动态化的任务,再将其迁移到漫画域中。
技术实现思路
1、本发明所要解决的技术问题是,针对漫画数据集数量不足,以及漫画视频生成网络优化迭代时间过长,连续性,稳定性和生成质量有待提升的问题,提供一种有效的高质量的漫画视频的生成方法。
2、本发明为解决上述技术问题所采用的技术方案是,一种基于域适应的漫画视频生成方法,包括以下步骤:
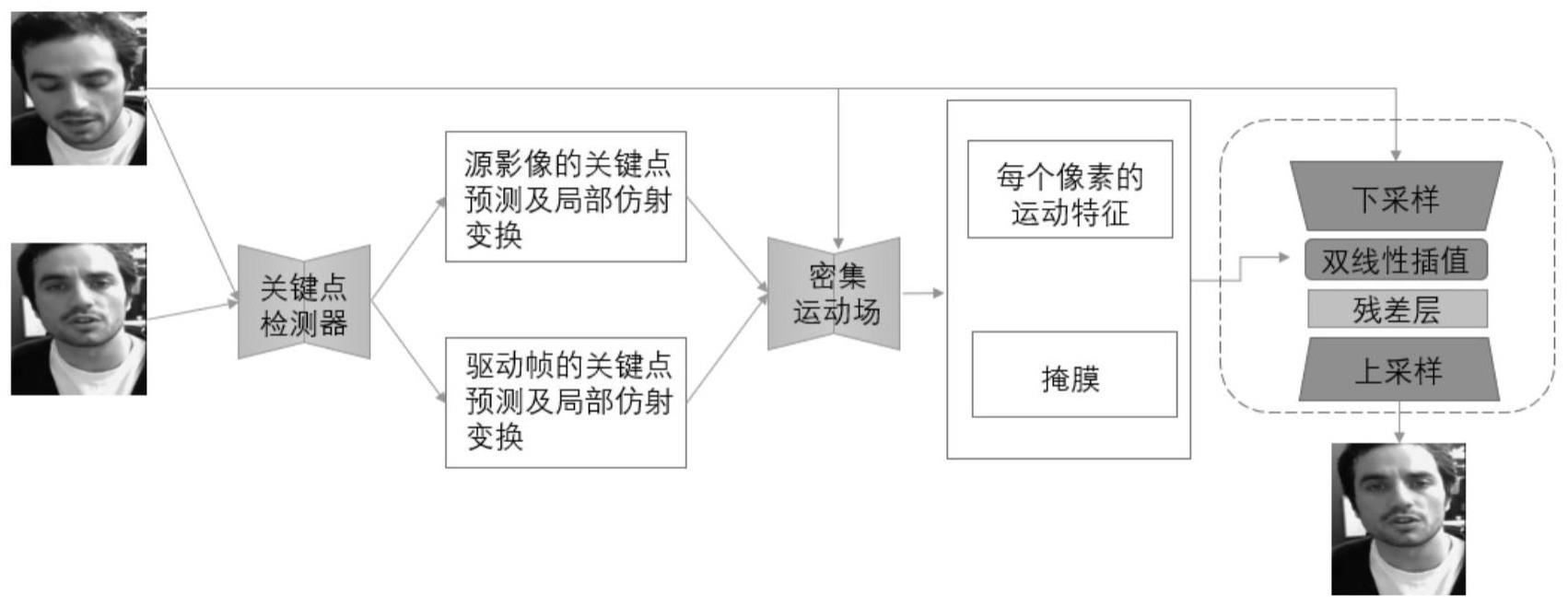
3、步骤1:使用人脸视频数据集对运动驱动网络进行训练;运动驱动网络包括关键点检测器、密集运动场模块和生成模块;具体包括以下步骤:
4、1-1对人脸视频数据集进行人脸对齐并统一尺寸;
5、1-2使用关键点检测器对人脸视频数据集中的源影像和驱动帧分别学习一组关键点的位置和其局部的仿射变换;
6、1-3密集运动场模块通过关键点的位置和其局部的仿射变换学习每一个像素的运动,并输出掩膜指示图像,该掩膜指示图像用于指示需要通过图像变形得到的部分和可以通过图像修补得到的部分;
7、1-4生成模块提取源影像的运动特征并结合掩膜指示图像对源影像进行渲染得到目标图像,将所有目标图像整合为目标视频;
8、步骤2:使用人脸视频数据集与漫画数据集对跨域网络进行训练;跨域网络包括关键点检测器、域判别器、梯度反转层、密集运动场模块和生成模块,梯度反转层设置在关键点检测器和域判别器之间;跨域网络的初始网络参数使用训练完成的运动驱动网络的网络参数,选取比漫画数据集数量多的人脸视频和漫画数据集作为训练数据集;具体包括以下步骤:
9、2-1对人脸视频数据集和漫画数据集进行人脸对齐并统一尺寸;
10、2-2人脸视频数据集进入关键点检测器,关键点检测器对人脸视频数据集中的源影像和驱动帧分别学习一组关键点的位置和其局部的仿射变换;关键点检测器输出检测关键点的位置以及其局部的仿射变换分别至密集运动场模块和域判别器;域判别器用于判断关键点检测器生成的结果是否真实;
11、漫画数据集进入关键点检测器,关键点检测器对漫画数据集中的源影像和驱动帧分别学习一组关键点的位置和其局部的仿射变换;关键点检测器一边将检测关键点的位置以及其局部的仿射变换输出至密集运动场模块,另一边经过梯度反转层送至域判别器;
12、2-3密集运动场模块通过关键点的位置和其局部的仿射变换学习每一个像素的运动,并输出掩膜指示图像,该掩膜指示图像用于指示需要通过图像变形得到的部分和可以通过图像修补得到的部分;
13、2-4生成模块提取源影像的运动特征并结合掩膜指示图像对源影像进行渲染得到目标图像,将所有目标图像整合为目标视频;
14、步骤3:跨域网络训练完成之后,将漫画图像输入至跨域网络,通过训练好的关键点检测器、密集运动场模块和生成模块既能得到生成的漫画视频。
15、本发明的有益效果是,首先使用人脸视频数据集进行图像动态化任务的训练,再将其使用域适应的方法适应到漫画域,解决了漫画数据集数量少而直接使用其进行训练容易导致的过拟合,泛化能力差等问题。此方法不需要进行逐视频优化,使用人脸视频数据集预训练的方式也使得生成视频的质量和稳定性得以保证。
技术特征:
1.一种基于域适应的漫画视频生成方法,其特征在于,包括以下步骤:
2.如权利要求1所述方法,其特征在于,步骤2中训练数据集的选取方法为:随机选取漫画数据集10倍数量的人脸视频和漫画数据集作为训练数据集。
3.如权利要求1所述方法,其特征在于,域判别器对输入数据的处理具体为:输入数据先经过一个全连接层将通道数转化为100,然后经归一化操作后输入至relu激活函数,再经过一个全连接层变为2个通道,最后通过softmax激活函数得到域判别的结果。
技术总结
本发明提供一种基于域适应的漫画视频生成方法,包括以下步骤:先使用人脸视频数据集对运动驱动网络进行训练;完成预训练的运动驱动网络对于输入的一张给定的源影像和驱动帧,就能根据驱动帧的运动生成并输出给定源影像的目标视频;再使用人脸视频数据集与漫画数据集对跨域网络进行训练;引入域判别器,利用梯度翻转层混淆人脸视频数据集和漫画数据集实现域分类误差的最大化。本发明首先使用人脸视频数据集进行图像动态化任务的训练,再将其使用域适应的方法适应到漫画域,解决了漫画数据集数量少而直接使用其进行训练容易导致的过拟合,泛化能力差等问题,不需要进行逐视频优化,使得生成视频的质量和稳定性得以保证。
技术研发人员:梁悦,李宏亮,刘黛瑶,万金鹏,崔建华,王世森,孟凡满,吴庆波,许林峰,潘力立
受保护的技术使用者:电子科技大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!