一种基于文本聚类和情感词典的情感分析方法
本发明涉及情感分析,具体涉及到一种基于文本聚类和情感词典的情感分析方法。
背景技术:
1、近年来随着微博使用人数越来越多,人们可以随时随地地在微博、twitter等社交平台上发表自己的想法、日常生活和评论,由此产生了大量带有情感倾向的主观性文本数据。通过对这些数据进行情感分析,可以更好地了解用户的对热点事件的关注和情感倾向,由此,情感分析技术应运而生。当前,文本情感分析的常用方法主要有基于情感词典方法和机器学习方法。基于情感词典的情感分析需要构建问题域的情感词典、计算情感得分从而判定情感极性,其算法的准确性取决于词典的丰富性。而如今网络中新兴词汇数量大且更新频繁,在很大程度上影响了此类方法的准确率。基于机器学习的方法是将情感分析当作文本聚类或分类任务,根据样本数据的不同,选择合适的分类算法或聚类算法训练模型。然而,基于分类算法训练分类器,需要人工标注的数据集,这既费时又费力,易形成标注瓶颈,且可能存在类别不平衡问题,从而限制了文本情感分类的准确性。而对于无监督学习的聚类算法,可以处理未标注样本数据集,有效避免有监督学习中算法模型对大量标注数据的依赖。在文本聚类领域,k-means因其算法思想简单、收敛速度快等特点应用最为广泛,但k-means算法在聚类过程中需要初始化类别数目k值,而文本聚类中数据通常会采取网络爬虫的方式获取,无法提前预知类别数量k值,人为设置的k值如果不合理,则会导致聚类结果误差大。
技术实现思路
1、技术问题:为解决上述技术问题,本发明提供一种基于文本聚类和情感词典的情感分析方法,有效避免了算法模型对大量标注数据的依赖,改进了k-means算法k值的选择问题,在文本聚类归堆方面进行改进并融合情感词典,情感分析更具健壮性和丰富性。
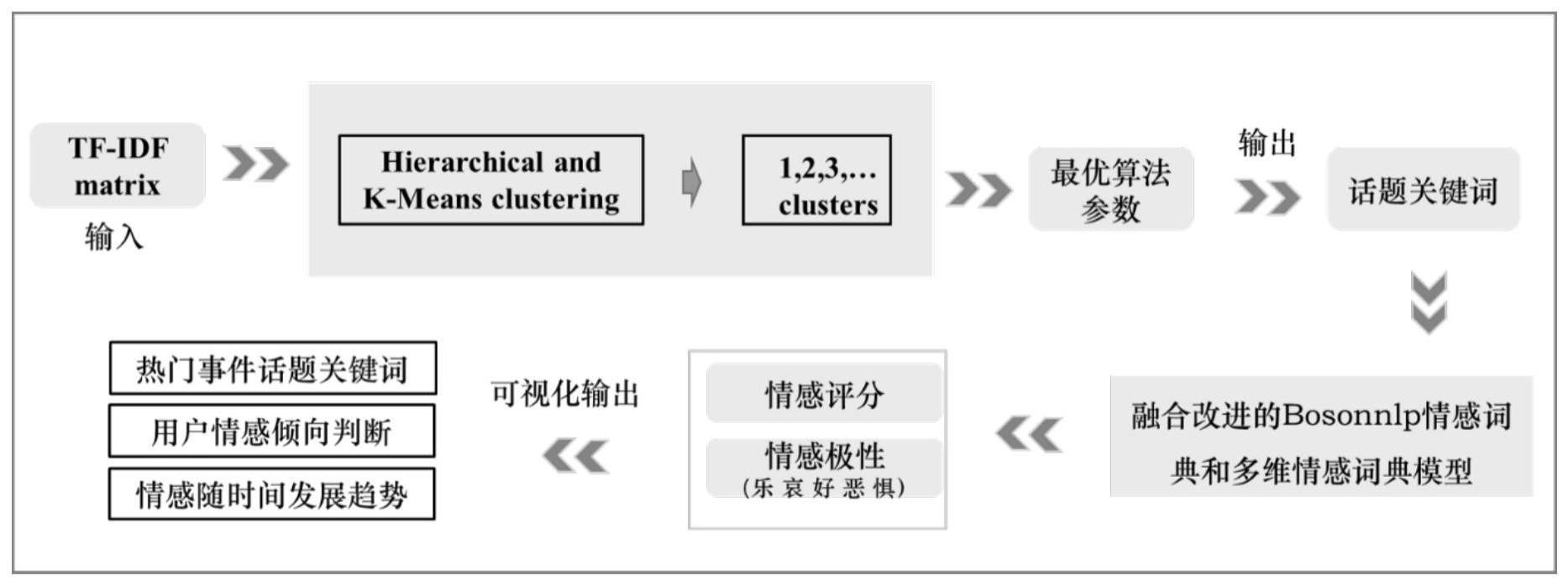
2、技术方案:本发明的一种基于文本聚类和情感词典的情感分析方法包括以下步骤:
3、s1:采用计算机爬虫技术抓取热门事件热门话题评论作为样本数据,生成样本评论数据csv文件;
4、s2:将样本评论数据csv文件作为输入,经数据预处理操作后生成tf-idf_matrix词向量数据;
5、s3:运用文本情感分析模型对所述tf-idf_matrix词向量数据进行情感分析,输出最优簇数、话题关键词、情感得分和情感极性;
6、s4:可视化展示热门事件话题关键词、用户情感倾向判断、情感随时间发展趋势。
7、其中,
8、所述的s1中计算机爬虫技术具体为基于python爬虫技术设计的两种数据抓取方案,第一种是复制电脑访问时的user-agent值,第二种是运用python的useragent包,伪装成用户爬取评论数据。
9、所述的s2中数据预处理操作指的是正则表达式数据清洗、jieba中文分词、textrank关键词提取、tf-idf特征提取、主成分分析pca降维和tsne降维。
10、所述的s3中的文本情感分析模型为基于层次聚类、k-means算法、聚类评估指标轮廓系数、bosonnlp情感词典和多维情感词典技术的融合改进模型。
11、所述的s4中的话题关键词指的是热门事件话题的高频词;用户情感倾向判断具体为针对热门事件的情感分析结果,可以是积极、消极或乐、哀、好、恶、惧;情感随时间发展趋势具体为热门事件的情感发展态势随时间的变化情况。
12、步骤s3中运用文本情感分析模型对所述tf-idf_matrix词向量数据进行情感分析具体包括以下步骤:
13、s3-1:基于层次聚类,生成层次聚类可视化树状图,输出最优层次簇数值区间;
14、s3-2:k-means算法进行tf-idf_matrix文本聚类分析,k值基于s3-1的最优层次簇数值区间,结合评价指标轮廓系数度量最佳分类簇数k的取值;
15、s3-3:提取热门事件评论话题关键词,输出聚类分析结果;
16、s3-4:tf-idf_matrix词向量数据送入融合改进的bosonnlp情感词典和多维情感词典模型,输出情感得分和情感极性。
17、所述的步骤s3-1的具体如下:
18、输入tf-idf_matrix词向量数据和最大迭代次数n,将tf-idf_matrix词向量中的每条样本数据看作单个集群,重复计算任意两条样本数据之间的间距,运用距离公式求出两类群中最短距离的样本点,另其为ci、cj,将ci和cj归堆至一个簇集群,重复以上工作,直到样本数据都合并到一个集群或者达到迭代次数n,可视化层次聚类树,输出最优层次簇数值区间。
19、所述的步骤s3-2具体如下:
20、从tf-idf_matrix词向量矩阵中选择k个样本作为初始簇中心{a1,a2,…,ak},k取值为s3-1最优层次簇数值区间。循环如下操作:对于n=1,…,n,样本集中任何数据,计算每个样本xi到各簇中心aj的距离xi标记为最小的dij所对应的类别λi,此时更新cλi=cλi∪{xi},对于j=1,2,…,k,对cj重新计算新的簇中心如果k个簇中心没有改变,循环停止,轮廓系数评估k-means文本聚类结果的好坏,输出最佳分类簇数k的取值。
21、根据权利要求6所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的步骤s3-1和步骤s3-2是一种文本聚类参数k评优方法,解决k-means算法初始k值的选择问题,最佳分类簇数k的值由层次聚类、k-means算法、聚类评估指标轮廓系数经所述的文本情感分析模型计算得出并可视化输出。
22、根据权利要求6所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的步骤s3-4中融合改进的bosonnlp情感词典和多维情感词典模型具体为:以bosonnlp情感词典为基础,设计程度副词和与热点事件有关的话题词及情感评分,进一步的,设计乐、衰、好、恶、惧多维情感词典,每个类中设计与当前热点事件相关的词语,基于以上设计生成的融合改进的bosonnlp情感词典和多维情感词典模型运用于评估热门事件的综合情感评分、情感极性。
23、有益效果:本发明的优点是:
24、(1)设计了一种文本聚类关键词提取和参数评优方法,基于层次聚类和轮廓系数解决k-means算法k值的选择问题。对于热门事件用户评论聚类分析,计算最优簇数、话题关键词,了解舆论导向。
25、(2)此外,在文本聚类算法的基础上,融合改进的bosonnlp情感词典和多维情感词典,在文本聚类归堆方面进行改进并融合情感词典,情感分析更具健壮性和丰富性。
26、(3)此外,本发明可以对热门事件的用户评论情感分析,输出话题关键词,用户情感倾向、情感随时间发展趋势,为有关部门更加精准、全面地掌握公众情感倾向提供参考意见。
技术特征:
1.一种基于文本聚类和情感词典的情感分析方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的s1中计算机爬虫技术具体为基于python爬虫技术设计的两种数据抓取方案,第一种是复制电脑访问时的user-agent值,第二种是运用python的useragent包,伪装成用户爬取评论数据。
3.根据权利要求1所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的s2中数据预处理操作指的是正则表达式数据清洗、jieba中文分词、textrank关键词提取、tf-idf特征提取、主成分分析pca降维和tsne降维。
4.根据权利要求1所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的s3中的文本情感分析模型为基于层次聚类、k-means算法、聚类评估指标轮廓系数、bosonnlp情感词典和多维情感词典技术的融合改进模型。
5.根据权利要求1所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的s4中的话题关键词指的是热门事件话题的高频词;用户情感倾向判断具体为针对热门事件的情感分析结果,可以是积极、消极或乐、哀、好、恶、惧;情感随时间发展趋势具体为热门事件的情感发展态势随时间的变化情况。
6.根据权利要求1所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,步骤s3中运用文本情感分析模型对所述tf-idf_matrix词向量数据进行情感分析具体包括以下步骤:
7.根据权利要求6所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的步骤s3-1具体如下:
8.根据权利要求6所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的步骤s3-2具体如下:
9.根据权利要求6所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的步骤s3-1和步骤s3-2是一种文本聚类参数k评优方法,解决k-means算法初始k值的选择问题,最佳分类簇数k的值由层次聚类、k-means算法、聚类评估指标轮廓系数经所述的文本情感分析模型计算得出并可视化输出。
10.根据权利要求6所述的一种基于文本聚类和情感词典的情感分析方法,其特征在于,所述的步骤s3-4中融合改进的bosonnlp情感词典和多维情感词典模型具体为:以bosonnlp情感词典为基础,设计程度副词和与热点事件有关的话题词及情感评分,进一步的,设计乐、衰、好、恶、惧多维情感词典,每个类中设计与当前热点事件相关的词语,基于以上设计生成的融合改进的bosonnlp情感词典和多维情感词典模型运用于评估热门事件的综合情感评分、情感极性。
技术总结
本发明公开了一种基于文本聚类和情感词典的情感分析方法,该方法包括:Python爬取热门事件评论话题数据,预处理为TF‑IDF_matrix词向量矩阵,运用文本情感分析模型对TF‑IDF_matrix词向量矩阵数据进行情感分析,输出最优簇数、话题关键词、情感得分和情感极性,展示话题关键词、用户情感倾向、情感随时间发展趋势。文本情感分析模型具体包括:基于层次聚类和K‑Means算法、轮廓系数的融合算法度量最佳分类簇数K值;提取热门事件评论话题关键词,输出聚类分析结果,情感倾向判断;TF‑IDF_matrix词向量矩阵数据送入融合改进的Bosonnlp情感词典和多维情感词典模型,可视化情感评分和情感极性值。本发明在文本聚类归堆方面进行改进并融合情感词典,情感分析更具健壮性和丰富性。
技术研发人员:朱艳,舒益新,李香菊
受保护的技术使用者:东南大学成贤学院
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!