基于中间表达的二进制代码开源成分识别方法及系统与流程
本发明涉及软件的开源成分检测,尤其涉及一种基于中间表达的二进制代码开源成分识别方法及系统。
背景技术:
1、开源运动推动了开源社区的发展,这些开源社区提供了大量的开源存储库,因此,基于开源组件的开发和代码重用大大提高了软件开发的效率,但是,由于开源组件的引入,这也会带来一些问题,如违反许可和安全漏洞等。
2、现如今大量的软件开发者出于各种原因的考虑,未公开其软件的源代码,这使得对软件中使用的第三方组件的识别工作带来不小的挑战。主要原因在于不同的软件的二进制文件可能通过各种不同的编译配置编译而来,包括不同的编译器、优化级别、指令架构等等。同一份源代码在通过不同的编译配置编译后产生的二进制文件往往存在较大的差异,难以很好的在二进制文件与源代码间进行匹配。
3、因此,需要对二进制代码开源成分检测技术进行改进。
技术实现思路
1、本发明的目的是提供一种基于中间表达的二进制代码开源成分识别方法及系统,以有效检测二进制软件代码与开源的源代码之间的相似性,并可消除因编译配置带来的影响。
2、为了实现上述目的,本发明公开了一种基于中间表达的二进制代码开源成分识别方法,其包括:
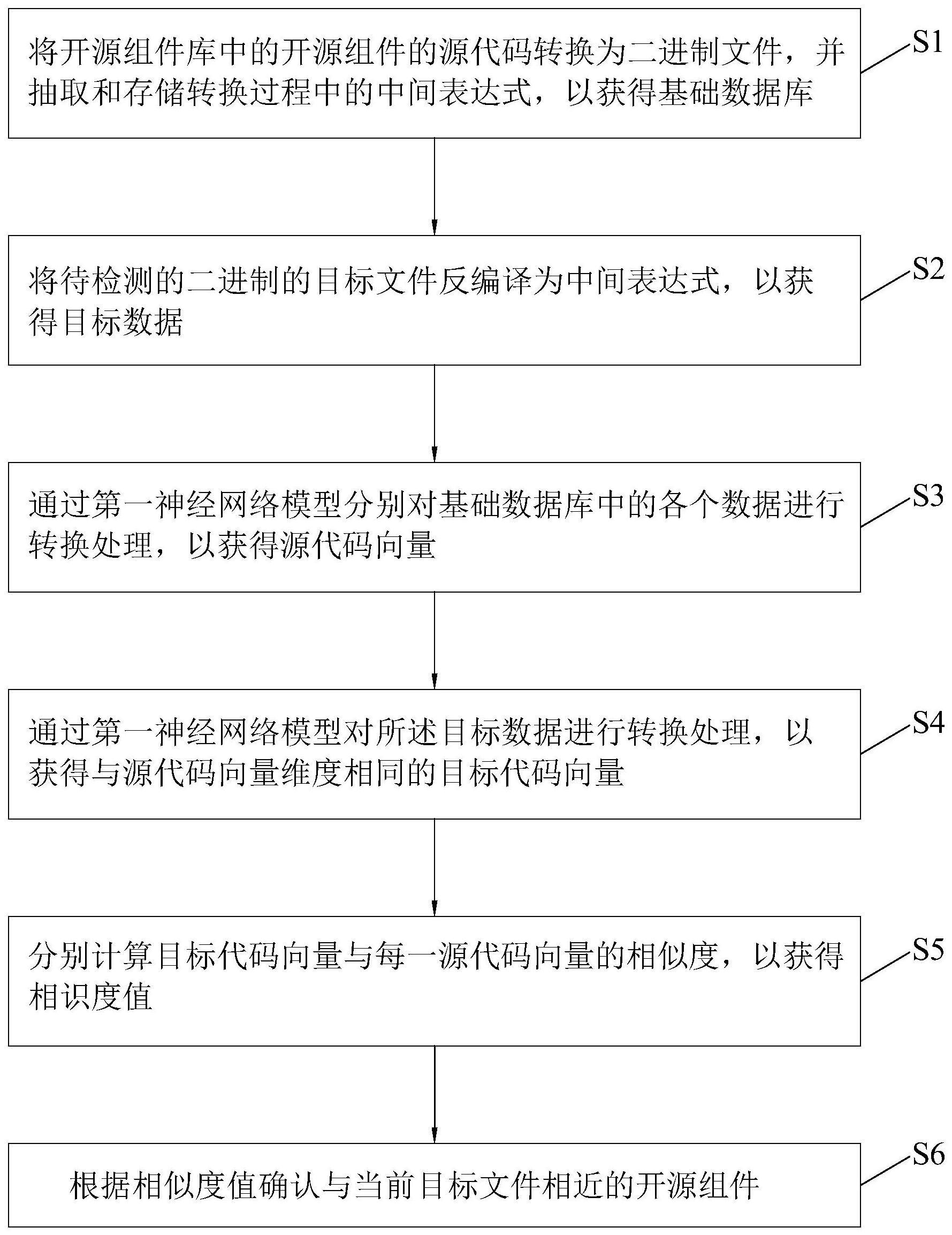
3、将开源组件库中的开源组件的源代码转换为二进制文件,并抽取和存储转换过程中的中间表达式,以获得基础数据库;
4、将待检测的二进制的目标文件反编译为中间表达式,以获得目标数据;
5、通过第一神经网络模型分别对所述基础数据库中的各个数据进行转换处理,以获得基于高维空间向量表达的源代码向量;同时,
6、通过所述第一神经网络模型对所述目标数据进行转换处理,以获得与所述源代码向量维度相同的目标代码向量;
7、分别计算所述目标代码向量与每一所述源代码向量的相似度,以获得相似度值。
8、较佳地,所述第一神经网络模型的生成方法包括:
9、提供一bert预训练模型;
10、通过所述基础数据库中的数据对bert预训练模型进行精调,以获得所述第一神经网络模型。
11、较佳地,采用第二神经网络模型计算目标代码向量与源代码向量的相似度。
12、较佳地,所述源代码向量的维度大于或等于1024。
13、本发明还公开一种基于中间表达的二进制代码开源成分识别系统,其包括:
14、第一转换模块,其用于将将开源组件库中的开源组件的源代码转换为二进制文件,并抽取和存储转换过程中的中间表达式,以获得基础数据库;
15、第二转换模块,其用于将待检测的二进制的目标文件反编译为中间表达式,以获得目标数据;
16、向量化表示模块,其用于通过第一神经网络模型分别对所述基础数据库中的各个数据和所述目标数据进行转换处理,以获得基于高维空间向量表达的源代码向量和目标代码向量;
17、相似度计算模块,其用于分别计算所述目标代码向量与每一所述源代码向量的相似度,以获得相似度值。
18、较佳地,还包括模型生成模块,所述模型生成模块用于通过所述基础数据库中的数据对bert预训练模型进行精调,以获得所述第一神经网络模型。
19、较佳地,还包括第二神经网络模型,所述相似度计算模块采用所述第二神经网络模型计算目标代码向量与源代码向量的相似度。
20、较佳地,所述源代码向量的维度大于或等于1024。
21、本发明还公开一种基于中间表达的二进制代码开源成分识别系统,其包括:
22、一个或多个处理器;
23、存储器;
24、以及一个或多个程序,其中一个或多个程序被存储在所述存储器中,并且被配置成由所述一个或多个处理器执行,所述程序包括用于执行如上所述的基于中间表达的二进制代码开源成分识别方法的指令。
25、本发明还公开一种计算机可读存储介质,其包括计算机程序,所述计算机程序可被处理器执行以完成如上所述的基于中间表达的二进制代码开源成分识别方法。
26、与现有技术相比,本发明上述技术方案,将开源组件和待检测的二进制的目标文件统一转换为相同的中间媒介,即中间表达式,然后通过第一神经网络模型分别对开源组件的中间表达式和待测的二目标文件的中间表达式进行处理,以获得基于高维空间向量表达的源代码向量和目标代码向量,最后通过计算目标代码向量和源代码向量之间的相似度即可找出与目标文件相近的开源组件;由此可知,通过上述方案,通过中间表达式的转换,有效消除了二进制代码文件在进行开源成分检测过程中因编译配置带来的影响,从而提升检测结果的准确性和效率。
技术特征:
1.一种基于中间表达的二进制代码开源成分识别方法,其特征在于,包括:
2.根据权利要求1所述的基于中间表达的二进制代码开源成分识别方法,其特征在于,所述第一神经网络模型的生成方法包括:
3.根据权利要求1所述的基于中间表达的二进制代码开源成分识别方法,其特征在于,采用第二神经网络模型计算目标代码向量与源代码向量的相似度。
4.根据权利要求1所述的基于中间表达的二进制代码开源成分识别方法,其特征在于,所述源代码向量的维度大于或等于1024。
5.一种基于中间表达的二进制代码开源成分识别系统,其特征在于,包括:
6.根据权利要求5所述的基于中间表达的二进制代码开源成分识别系统,其特征在于,还包括模型生成模块,所述模型生成模块用于通过所述基础数据库中的数据对bert预训练模型进行精调,以获得所述第一神经网络模型。
7.根据权利要求5所述的基于中间表达的二进制代码开源成分识别系统,其特征在于,还包括第二神经网络模型,所述相似度计算模块采用所述第二神经网络模型计算目标代码向量与源代码向量的相似度。
8.根据权利要求5所述的基于中间表达的二进制代码开源成分识别系统,其特征在于,所述源代码向量的维度大于或等于1024。
9.一种基于中间表达的二进制代码开源成分识别系统,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,包括计算机程序,所述计算机程序可被处理器执行以完成如权利要求1至4任一项所述的基于中间表达的二进制代码开源成分识别方法。
技术总结
本发明公开了一种基于中间表达的二进制代码开源成分识别方法及系统,其包括:将开源组件库中的开源组件的源代码转换为二进制文件,并抽取和存储转换过程中的中间表达式,以获得基础数据库;将待检测的二进制的目标文件反编译为中间表达式,以获得目标数据;通过第一神经网络模型分别对基础数据库中的各个数据以及目标数据进行转换处理,以获得基于高维空间向量表达的源代码向量和目标代码向量;分别计算目标代码向量与每一源代码向量的相似度,以获得相似度值;基于上述方法,通过中间表达式的转换,有效消除了二进制代码文件在进行开源成分检测过程中因编译配置带来的影响,从而提升检测结果的准确性和效率。
技术研发人员:万振华,胡佳豪,蒋建春,程泽凯
受保护的技术使用者:深圳开源互联网安全技术有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!