内容自适应的行人重识别数据集生成方法及系统
本发明涉及行人重识别,尤其涉及内容自适应的行人重识别数据集生成方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、行人重识别是智能监控系统中一个重要的研究课题,适用于安防以及公共场所寻人等技术领域。其目的主要是在跨区域的非重叠摄像机视角下识别出同一个行人,即对于摄像头中给定的某个待查寻行人,判断其是否出现在其他摄像头下。它是一种自动的目标识别技术,能在监控网络中快速定位到感兴趣的行人目标,是智能视频监控中的重要步骤。
3、目前,常利用卷积神经网络并结合监督学习的方式获得具有判别力的模型,进行行人重识别。监督学习的方式需要大量的训练数据集,即用当前的训练数据来对将来的数据进行估计与模拟。
4、然而,目前用于行人重识别的数据集中的样本数量有限,且样本存在图像质量差、模糊遮挡、半身人、相似度较高等问题。当利用现有的数据集进行行人重识别模型训练时,使得训练好的行人重识别模型的精度较低,且容易出现过拟合现象。
5、为解决数据集中样本数量有限且样本质量较差的问题,常采用人工方式制作并扩充数据集,需要大量的人工介入,代价较大。
6、针对上述数据集制作及扩充问题,现有的方法有三种,一是获取更多的视频或图片数据,结合人工和机器标注来对数据集进行扩充,人工标注需要大量的人工介入代价较大,且机器标注工作的可靠性也不高;二是通过无监督学习,加入非标注数据,智能提高识别性能,这种方法引入的数据通常不满足数据的独立同分布准则,从而导致数据存在误差,使得提升效果有限;三是在已有数据基础上进行线性变换,从而可得到更多数据,这种方法无法得到多样性数据,且鲁棒性较差,计算复杂度较高。
7、故发明人认为,现有的用于行人重识别的数据集中样本数量有限样本质量较差,且并不能对数据集进行有效扩充。
技术实现思路
1、本发明为了解决上述问题,提出了内容自适应的行人重识别数据集生成方法及系统,通过对行人框图进行无遮挡、无运动模糊、无相似图像和高质量得分筛选,并根据不同域的特点进行相应的域内数据增强和域间数据扩充,获得了高质量、多样性的行人重识别数据集。
2、为实现上述目的,本发明采用如下技术方案:
3、第一方面,提出了内容自适应的行人重识别数据集生成方法,包括:
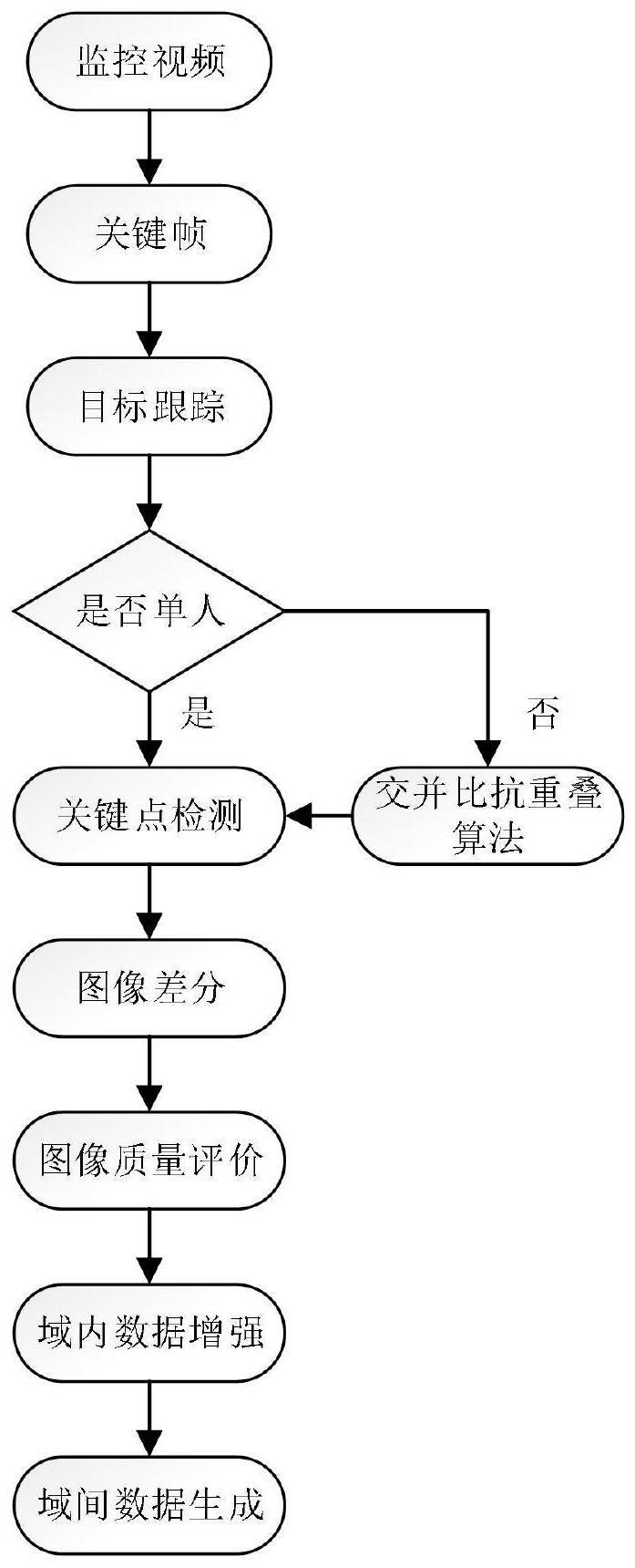
4、获取监控视频,并从监控视频中提取关键帧;
5、对监控视频进行行人目标轨迹跟踪,并获取每个关键帧的行人框图像及对应的身份信息;
6、从获取的行人框图像中,筛选出无遮挡和无运动模糊的行人框图,且筛选出的全身行人框图在相邻帧内无相似图片;
7、对筛选出的各全身行人框图进行质量评价,获得筛选出的各行人框图的质量得分;
8、对质量得分高于设定分数阈值的行人框图进行域内数据增强,获得数据增强后框图;
9、根据数据增强后框图进行域间数据生成,获取各行人的跨相机特征图;
10、通过数据增强后框图与各行人的跨相机特征图构建行人重识别数据集。
11、第二方面,提出了内容自适应的行人重识别数据集生成系统,包括:
12、关键帧获取模块,用于获取监控视频,并从监控视频中提取关键帧;
13、行人框图获取模块,用于对监控视频进行行人目标轨迹跟踪,并获取每个关键帧的行人框图像及对应的身份信息;
14、行人框图筛选模块,用于从获取的行人框图像中,筛选出无遮挡和无运动模糊的全身行人框图,且筛选出的全身行人框图在相邻帧内无相似图片;
15、质量评价模块,用于对筛选出的各全身行人框图进行质量评价,获得筛选出的各行人框图的质量得分;
16、域内数据增强模块,用于对质量得分高于设定分数阈值的行人框图进行域内数据增强,获得数据增强后框图;
17、域间数据生成模块,用于根据数据增强后框图进行域间数据生成,获取各行人的跨相机特征图;
18、数据集构建模块,用于通过数据增强后框图与各行人的跨相机特征图构建行人重识别数据集。
19、第三方面,提出了一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成内容自适应的行人重识别数据集生成方法所述的步骤。
20、第四方面,提出了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成内容自适应的行人重识别数据集生成方法所述的步骤。
21、与现有技术相比,本发明的有益效果为:
22、1、本发明通过对行人框图进行无遮挡、无运动模糊、无相似图像和高质量得分筛选,并根据不同域的特点进行相应的域内数据增强和域间数据扩充,获得了高质量、多样性的行人重识别数据集。
23、2、本发明的域内数据增强策略,从不同的数据增强策略中,筛选出了使行人重识别损失最小的最优数据增强策略,利用该最优数据增强策略能够对域内数据进行有效增强。
24、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.内容自适应的行人重识别数据集生成方法,其特征在于,包括:
2.如权利要求1所述的内容自适应的行人重识别数据集生成方法,其特征在于,获取筛选出的全身行人框图的过程为:
3.如权利要求2所述的内容自适应的行人重识别数据集生成方法,其特征在于,对于每个关键帧,当存在多个行人框图像时,对于每个行人框图像,计算与其余行人框图像的交并比,从所有的行人框图像中,筛选出与其余行人框图像的交并比均小于等于设定阈值的行人框图像,为无遮挡的行人框图;当仅存在单个行人框图像时,直接将该行人框图像作为无遮挡的行人框图;
4.如权利要求2所述的内容自适应的行人重识别数据集生成方法,其特征在于,根据行人框图的时序,对筛选出的无遮挡和无运动模糊的全身行人框图进行段划分,在每一段中,均包括多帧的无遮挡和无运动模糊的全身行人框图;
5.如权利要求1所述的内容自适应的行人重识别数据集生成方法,其特征在于,通过图像质量评价网络对筛选出的各全身行人框图进行质量评价,获得筛选出的各行人框图的质量得分。
6.如权利要求1所述的内容自适应的行人重识别数据集生成方法,其特征在于,进行域内数据增强的过程为:
7.如权利要求1所述的内容自适应的行人重识别数据集生成方法,其特征在于,获取各行人的跨相机特征图的过程为:
8.内容自适应的行人重识别数据集生成系统,其特征在于,包括:
9.一种电子设备,其特征在于,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成权利要求1-7任一项所述的内容自适应的行人重识别数据集生成方法的步骤。
10.一种计算机可读存储介质,其特征在于,用于存储计算机指令,所述计算机指令被处理器执行时,完成权利要求1-7任一项所述的内容自适应的行人重识别数据集生成方法的步骤。
技术总结
本发明公开的内容自适应的行人重识别数据集生成方法及系统,包括:获取监控视频,并从监控视频中提取关键帧;对监控视频进行行人目标轨迹跟踪,并获取每个关键帧的行人框图像及对应的身份信息;从获取的行人框图像中,筛选出无遮挡和无运动模糊的全身行人框图,且筛选出的全身行人框图在相邻帧内无相似图片;对筛选出的各全身行人框图进行质量评价,获得筛选出的各行人框图的质量得分;对质量得分高于设定分数阈值的行人框图进行域内数据增强,获得数据增强后框图;根据数据增强后框图进行域间数据生成,获取各行人的跨相机特征图;通过数据增强后框图与各行人的跨相机特征图构建行人重识别数据集。获得了高质量、多样性的行人重识别数据集。
技术研发人员:杨阳,李雪,刘云霞,张南南,孙齐悦,李玉军,翟超,彭朝祥
受保护的技术使用者:山东大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!