一种基于随机森林改进的特征选择方法
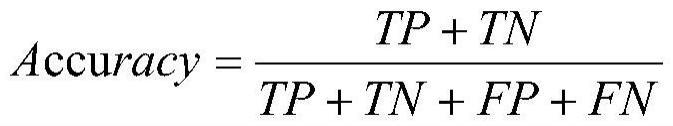
:本发明涉及数据分类的技术,尤其是涉及一种基于随机森林改进的特征选择方法,该方法在特征选择方面有着很好的应用。
背景技术
0、
背景技术:
1、特征选择(feature selection)也称特征子集选择,是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高学习算法性能的一个重要手段,目前主要有过滤器、包装器和嵌入式方法三类。
2、过滤器方法(filter methods)是最常用的特征选择方法,通常是针对单变量的,它会假定每个特征都独立于其他特征,最著名的过滤器方法包括卡方检验、相关系数和信息增益指标,但是,这种滤波方法会导致相关特征的丢失。与过滤式特征选择不考虑后续学习器不同,包裹式特征选择(包裹法,wrapper)直接把最终将要使用的学习器的性能作为特征子集的评价准则。换言之,包裹式特征选择的目的就是为了给定学习器选择最有利于其性能、“量身定做”的特征子集。因为包裹法是基于最终的学习器来进行特征选择的,所以一般而言,在最终学习器性能方面,包裹法要比过滤法特征选择更好;但另一方面,由于在特征选择过程中多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征选择大得多。
3、在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别;与此不同,嵌入式特征选择(嵌入法,embedded)是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。常见的嵌入式特征选择有基于l1正则项的嵌入式特征选择、基于树模型的嵌入式特征选择。然而,随机森林具有准确率高、鲁棒性好、易于使用等优点,这使得它成为了目前最流行的机器学习算法之一。
4、随着大数据时代的到来,数据的维度也在不断增加,数据集的高维性增加了计算和分析的复杂性,为了解决这一问题,本发明采用一种基于随机森林改进的特征选择方法来降低数据特征之间的冗余度和复杂性。
技术实现思路
0、
技术实现要素:
1、为了解决数据集特征选择的问题,本发明公开了一种基于随机森林改进的的特征选择方法。
2、为此,本发明提供了如下技术方案:
3、1.一种基于随机森林改进的特征选择方法,其特征在于,该方法包括以下步骤:
4、步骤1:数据预处理模块,对完整数据集进行缺失值处理、离散化处理。
5、步骤2:特征选择模块,采用基于随机森林改进的特征选择方法进行特征选择。
6、2.根据权利要求1所述的一种基于随机森林改进的特征选择方法,其特征在于,所述步骤1中,数据预处理模块,对完整数据集进行缺失值处理、离散化处理,具体步骤为:
7、步骤1-1删除数据中含有缺失值的样本;
8、步骤1-2采用自上而下的、有监督的caim离散算法对无缺失值的数据的连续型特征进行离散化处理,处理公式为:
9、
10、其中,qir(i=1,2,...,s;r=1,2,...,n)表示样本中属于i类且属于区间(dr-1,dr]的个数,maxr是所有qir中的最大值,mi+是属于第i类的样本个数总和,m+r是属于区间(dr-1,dr]的样本个数总和,n表示区间个数。
11、3.根据权利要求1所述的一种基于随机森林改进的的特征选择方法,其特征在于,所述步骤2中,特征选择模块,采用基于随机森林改进的的特征选择方法进行特征选择,具体步骤为:
12、步骤2-1将缺失值处理、离散化处理后的数据集设为数据集d;
13、步骤2-2将数据集d划分为训练集t和测试集s;
14、步骤2-3使用训练集t建立随机森林模型,通过bagging方式随机并有放回的抽取原始样本种的n个样本构成新的训练样本,当n足够大时,其中约有1/3的样本不在训练样本中,这类数据被称为袋外(out ofbag,oob)数据。并根据gini系数最小原则下通过随机选择n棵决策树内部分裂后的每个节点变量的子集来构建多个cart决策树并组成随机森林;其中gini系数定义如下:
15、
16、式中,t为给定数据集,ci为随机选择一个样本并认定为某一类别,为所选样本为ci类别的概率;
17、步骤2-4计算训练集t建立的传统随机森林模型在测试集s上的准确率,准确率计算公式为:
18、
19、其中,tp表示真正例,即实际为正预测为正,tn表示真反例,即实际为负预测为负,fp表示假正例,即实际为负但预测为正,fn表示假反例,即实际为正但预测为负;
20、步骤2-5计算设定树木颗数最佳树深度,以最佳深度重新生成随机森林。根据步骤2-4得到的传统随机森林的准确率以及传统随机森林,从而计算设定树木颗数最佳树深度,因此需要生成的传统随机森林对数据进行分类,对于精度估计,当每个样本属于oob样本时,每次都会统计其投票数,多数表决的投票将决定分类类别,oob样本由于未参与建立决策树,可用来估计预测误差,利用oob误差评估模型性能及量化变量的重要性。变量的重要性定义如下:
21、
22、式中,v(kj)为第j个特征变量的重要性,n为生成的决策树棵树ei为第i个决策树的袋外误差,为随机改变第j个特征变量值后计算的新的袋外误差;
23、步骤2-6计算训练集t建立的新生成的随机森林模型中的每棵树在测试集s上的准确率,选取准确率靠前的一定百分比的树;
24、步骤2-7计算各个树的数据相似度,相似度计算公式为:
25、
26、其中,a、b为2组特征向量,长度为n,ai、bi代表特征向量第i维的值,min(ai,bi)为ai、bi中较小的一个值,max(ai,bi)则相反;
27、步骤2-8排除相似度超过设定值且准确率较小的树,最后计算最终准确率,从而得到改进后的随机森林;
28、步骤2-9使用改进后的随机森林进行特征提取,得到特征子集。
29、有益效果:
30、1.本发明是一种基于随机森林改进的特征选择方法,可以有效进行数据降维,能够实现较高的准确率来达到选择最优子集的目的。
31、2.本发明结合了特征选择中改进的随机森林方法来进行数据的降维,使用改进的随机森林来提升准确率以得到选择最优子集的目的,同时采用树相似度算法,能够利用树的结构特征间接表示树的相似度,可有效应用于大规模数据集。基于随机森林改进的特征选择方法在寻找特征子集方面具有很高的识别能力,实现了特征选择的高效性。
技术特征:
1.一种基于随机森林改进的特征选择方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的一种基于随机森林改进的特征选择方法,其特征在于,所述步骤1中,数据预处理模块,对完整数据集进行缺失值处理、离散化处理,具体步骤为:
3.根据权利要求1所述的一种基于随机森林改进的的特征选择方法,其特征在于,所述步骤2中,特征选择模块,采用基于随机森林改进的的特征选择方法进行特征选择,具体步骤为:
技术总结
本发明公开了一种基于随机森林改进的的特征选择方法,包括以下步骤:先对完整数据集进行缺失值处理、离散化处理;其次建立传统随机森林模型,并计算传统模型准确率,然后计算设定树木颗数时最佳树深度,以最佳深度重新生成随机森林,并且计算新生成森林中每棵树的准确率,选取准确率靠前的一定百分比的树,然后通过计算各个树的数据相似度,排除相似度超过设定值且准确率较小的树,最后计算最终准确率,从而得到改进后的随机森林。导致分类器性能下降的原因往往是因为这些高维度特征中含有无关特征和冗余特征,本发明基于随机森林的改进特征选择方法可以有效进行数据降维,可以实现较高的准确率来达到选择最优子集的目的。
技术研发人员:周文进,安云飞,苗世迪
受保护的技术使用者:哈尔滨理工大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!