基于双流注意力机制和循环自编码器的半监督故障诊断方法
本发明属于工业过程领域,涉及一种基于双流注意力机制和循环自编码器的半监督故障诊断方法。
背景技术:
1、在现代工业中,对工业设备可靠性要求越来越高,工业设备的失效其不仅直接影响生产效率,而且严重故障甚至会导致经济损失甚至人员伤亡。而有效的故障诊断方法能够及时发现故障,避免不必要的损失并提高生产效率。近年来的故障诊断方法包括基于机理的方法,基于专家经验的方法以及基于数据驱动的方法,而随着传感器技术和智能制造技术的快速发展,源于设备的数据量大大增加,这使得基于数据驱动的方法快速发展,其中以卷积神经网络模型为代表的深度学习方法最为广泛。
2、深度学习方法是在监督学习条件下进行模型训练的,这要求存在大量的有标签数据,不足的标签数据会导致诊断效果的大大下降。然而在工业过程中,获取的大量数据往往是无标签的,人为标注数据耗时耗力,甚至在某些情况下无法标注。因此,结合少量有标签数据,并充分利用无标签数据提高故障诊断精度尤为重要,而半监督学习方法能够实现这点。
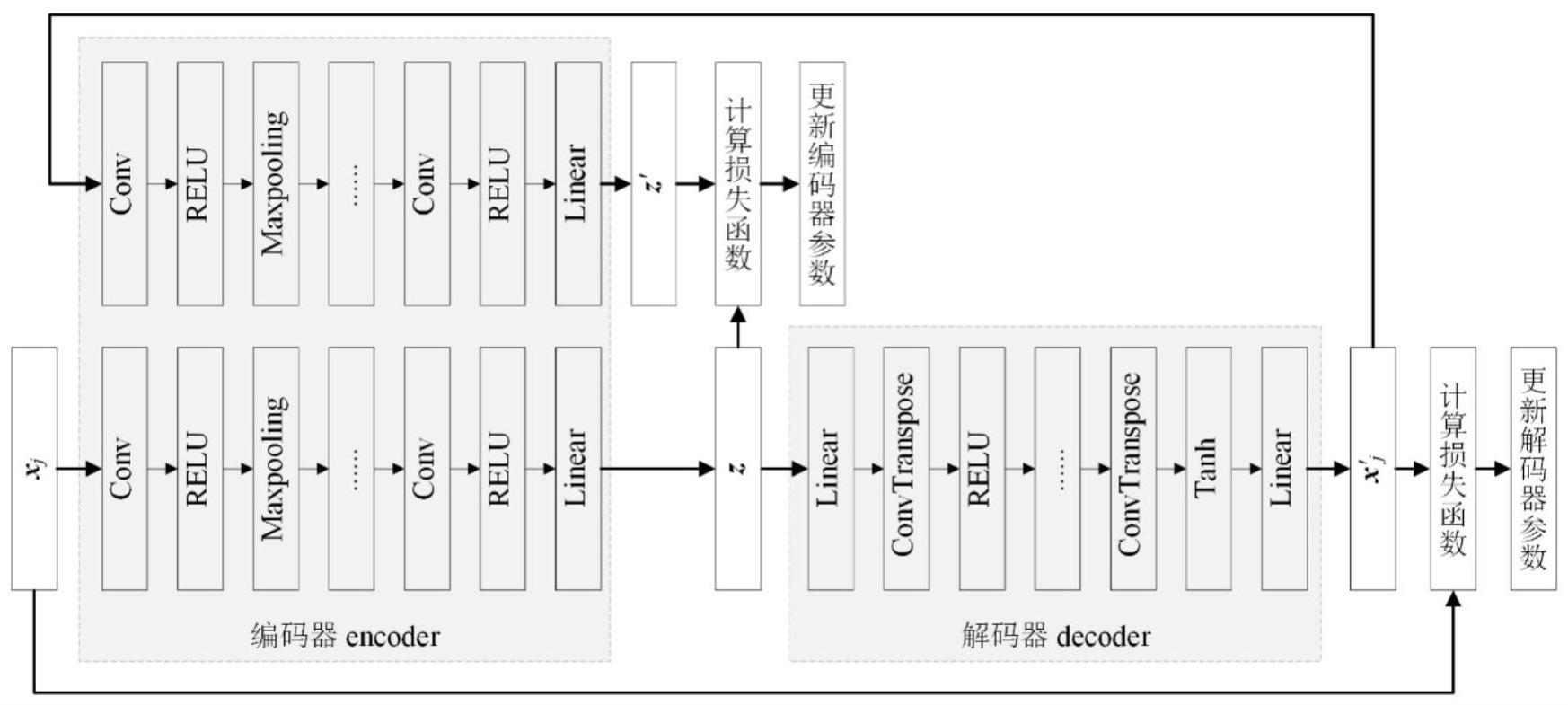
3、自编码器(ae,auto encoder)作为典型的无监督学习模型,包含编码器和解码器两个部分,编码器将输入样本降维到潜空间中提取特征,解码器将编码器提取的特征升维重构样本,并最小化重构样本和样本两者间的误差,使网络结构学习到样本特征,具有训练简单、泛化能力强的特点,因此被广泛用于半监督学习方法中的预训练模型步骤。半监督学习方法需要在预训练完成后,在编码器部分后接全连接层构造分类器,并通过少量有标签样本微调该分类器得到最终模型。然而自编码器提取的样本特征常常会与期望样本特征存在偏差,其重构样本亦与样本间存在特征层面的差异。导致基于自编码器的半监督故障诊断方法在有标签样本数量有限时准确率低。因此,需要一种能够更优的半监督故障诊断方法,能够提取到更具代表性的特征,提高低标签率下的分类精度。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于双流注意力机制和循环自编码器的半监督故障诊断方法,该方法改进了自编码器的优化过程,在编码器中加入了针对重构样本和样本两者特征差异的损失函数,最终提高了半监督故障诊断方法的诊断精度及泛化能力。针对基于自编码器的半监督学习方法中重构样本与样本存在特征差异,使得该方法在有标签样本数量较少时准确率低的问题。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于双流注意力机制和循环自编码器的半监督故障诊断方法,包括以下步骤:
4、s1:收集工业过程的故障数据及正常运行数据,经预处理后建立训练数据集;
5、s2:构建插入双流注意力机制的循环自编码器模型cae,利用故障样本x训练cae模型,以自动提取故障数据的特征,并得到经过充分预训练的模型caep;
6、s3:取出步骤s2预训练得到的循环自编码器中的编码器部分enet,向其后添加一层全连接层输出分类类别,随机初始化该全连接层中参数,构成新分类器enetp;
7、s4:将步骤s3中得到的新分类器enetp解冻,设置学习率并进行训练,得到期望分类器enetf;
8、s5:将新的工业过程故障数据以步骤s1中相同方法处理得到新的故障数据,输入所述期望分类器enetf,输出诊断结果。
9、进一步,步骤s1中的数据包括标注过故障类别的有标签数据集以及无故障标签的无标签数据集其中x代表故障样本,y代表样本标签,m表示有标签样本个数,n表示无标签样本个数。
10、进一步,所述循环自编码器模型cae包括编码器、解码器、循环结构及双流注意力机制;
11、所述编码器和解码器各自根据不同的损失进行优化,最终编码器输出样本降维后的特征,解码器输出重构样本;
12、所述循环结构根据不同的损失函数更新编码器、解码器参数;
13、所述双流注意力机制通过卷积的方式,同时捕捉通道之间的关系以及空间的位置信息,提高模型的特征提取能力。
14、进一步,所述编码器的编码过程如下:
15、z=fe(wex+be) (8)
16、式中:x为输入样本,z为潜空间样本特征,we为权值矩阵,be为偏置,fe为激活函数;
17、所述解码器的解码过程如下:
18、x'=fd(wdz+bd) (9)
19、式中:x’为重构样本,z为输入的潜空间样本特征,wd为权值矩阵,bd为偏置,fd为激活函数。
20、进一步,所述循环结构根据不同的损失函数更新编码器、解码器参数,具体包括:重构样本与样本间误差的损失函数更新解码器参数;重构样本通过编码器再次进行编码得到重构样本特征,原样本编码得到样本特征,计算两者误差作为更新编码器的损失函数;
21、对于编码器,采用均方误差函数作为训练损失函数,分别提取重构样本及样本的特征,并计算两者的误差,其整体优化过程及目标函数如下:
22、
23、
24、其中,x’为重构样本,z’为重构样本的特征,zi,z’i分别代表第i个样本的特征及第i个重构样本的特征,m表示有标签样本个数;
25、对于解码器,采用均方误差函数作为训练损失函数,计算样本及重构样本两者的误差,其优化过程及目标函数如下:
26、
27、其中xi,x’i分别代表第i个样本及第i个重构样本,n表示无标签样本个数。
28、进一步,所述双流注意力机制分别对样本的特征图的通道方向和水平空间方向进行平均池化得到两个1d向量c和w,再将利用局部跨道信息交互,使用1×k大小的卷积核对两向量进行卷积得到向量ck和wk,再通过sigmoid激活函数激活两向量,最后与原特征图相乘。k根据向量大小自适应调整,其计算如下:
29、c=φ(k)=2(γ*k-b) (13)
30、
31、其中,k表示卷积核大小,c表示向量大小,b,γ为改变向量大小c和卷积核大小k之间比例的参数。
32、进一步,步骤s3中所述构成新分类器enetp,具体包括:冻结所述编码器部分enet,利用步骤s1中的有标签数据集训练该全连接层得到新的分类器enetp。
33、本发明的有益效果在于:本发明方法在自编码器重构样本与样本误差减少的基础上,通过改进自编码器的优化过程,使重构样本特征贴近原始样本特征,并以此具有代表性的特征作为潜空间特征,增强了自编码器提取特征的能力。最终提高了半监督故障诊断方法的同分布及跨工况诊断精度。
34、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
技术特征:
1.一种基于双流注意力机制和循环自编码器的半监督故障诊断方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的基于双流注意力机制和循环自编码器的半监督故障诊断方法,其特征在于:步骤s1中的数据包括标注过故障类别的有标签数据集以及无故障标签的无标签数据集其中x代表故障样本,y代表样本标签,m表示有标签样本个数,n表示无标签样本个数。
3.根据权利要求1所述的基于双流注意力机制和循环自编码器的半监督故障诊断方法,其特征在于:所述循环自编码器模型cae包括编码器、解码器、循环结构及双流注意力机制;
4.根据权利要求1所述的基于双流注意力机制和循环自编码器的半监督故障诊断方法,其特征在于:所述编码器的编码过程如下:
5.根据权利要求1所述的基于双流注意力机制和循环自编码器的半监督故障诊断方法,其特征在于:所述循环结构根据不同的损失函数更新编码器、解码器参数,具体包括:重构样本与样本间误差的损失函数更新解码器参数;重构样本通过编码器再次进行编码得到重构样本特征,原样本编码得到样本特征,计算两者误差作为更新编码器的损失函数;
6.根据权利要求1所述的基于双流注意力机制和循环自编码器的半监督故障诊断方法,其特征在于:所述双流注意力机制分别对样本的特征图的通道方向和水平空间方向进行平均池化得到两个1d向量c和w,再将利用局部跨道信息交互,使用1×k大小的卷积核对两向量进行卷积得到向量ck和wk,再通过sigmoid激活函数激活两向量,最后与原特征图相乘。k根据向量大小自适应调整,其计算如下:
7.根据权利要求1所述的基于双流注意力机制和循环自编码器的半监督故障诊断方法,其特征在于:步骤s3中所述构成新分类器enetp,具体包括:冻结所述编码器部分enet,利用步骤s1中的有标签数据集训练该全连接层得到新的分类器enetp。
技术总结
本发明涉及一种基于双流注意力机制和循环自编码器的半监督故障诊断方法,属于工业过程领域,将故障数据预处理后,利用插入了双流注意力机制的循环自编码器无监督提取无标签、有标签样本特征,并在充分训练后的循环自编码器的编码器后,接入了一层全连接分类层构成分类器,使用有标签样本对该分类器进行微调,最终得到期望分类器,避免了在标注数据不足的情况下训练故障分类器时的过拟合问题。双流注意力机制能够提高模型的特征提取能力,循环自编码器能够提高半监督故障诊断方法的分类精度,且拥有更强的泛化性,训练的模型在跨工况上准确率也更高。
技术研发人员:邓聪颖,李茂银,苗建国,孙惠娟,禄盛,罗久飞,邓子豪
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!