一种基于SPARK的大数据自动化稽核系统及方法与流程
本发明属于互联网架构领域,尤其是涉及一种基于spark的大数据自动化稽核系统及方法。
背景技术:
1、随着业务的发展,对综合账务系统的要求越来越高,系统在支撑业务过程中也逐渐显露出不足,主要为固费计算(账务系统一个模块,主要用于收费月租)端到端环节保障机制不完善、月末出账过程繁琐及出账风险高。
2、固费计算端到端环节保障机制不完善,存在数据丢失风险、客户投诉风险、收入流失风险、客诉难以追溯等问题。
3、数据同步和过滤规则复杂,业务处理规则及流程复杂,数据量的庞大等原因决定了无法通过简单稽核比对确定数据同步的完整性、固费计算的准确性,存在“跑、冒、滴、漏”的风险。
4、传统的技术或者方法是将数据入到oracle数据库,进行多级关联,生成层中间表进行比较。但由于数据量庞大,每天产生200gb左右的数据量,经过层层转换达到tb级别量级,造成oracle存储不足;此外大量的数据的关联计算,需要大量的算力,oracle的sql计算已经达到性能的瓶颈,无法支持此类大数据的稽核。
5、由此,亟需引入一种能够处理大数据的自动化稽核平台,来实现固费业务稽核保障。
技术实现思路
1、针对上述问题,本发明提出了一种基于spark的大数据自动化稽核系统及方法,在大数据场景下,快速进行配置化的、自动化的数据批量比对,为固费业务稽核提供保障。
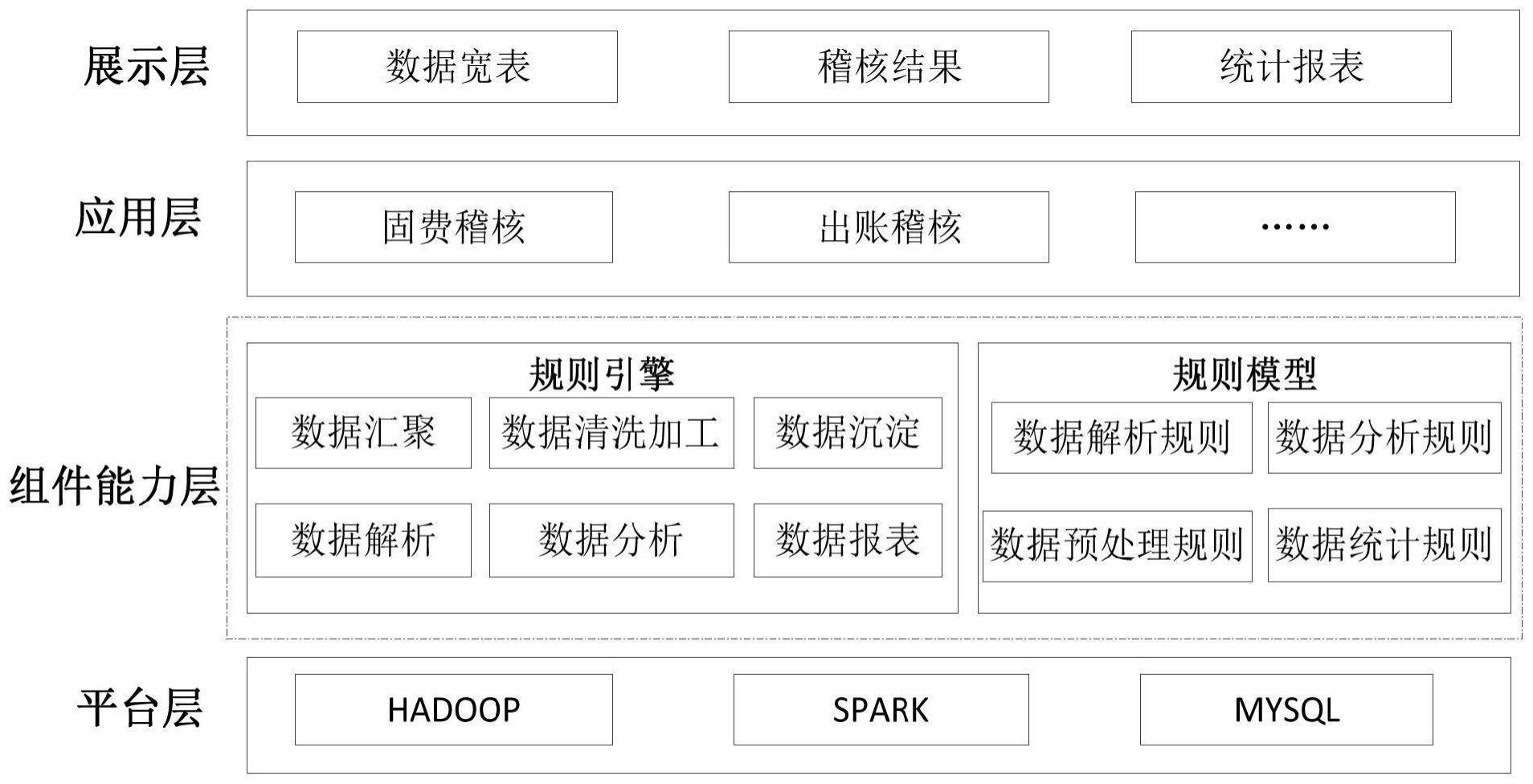
2、为实现上述目的,本发明公开了一种基于spark的大数据自动化稽核系统,包括:
3、平台层、组件能力层、应用层和展示层;
4、所述平台层,用于:
5、采用hadoop+spark生态体系,通过技术栈为所述组件能力层提供数据处理支撑;
6、所述组件能力层,用于:
7、设置多种规则模型和多种规则引擎,规则引擎依赖规则模型对待稽核的数据集进行解析、汇聚和清洗加工,得到包含所有计算因子的内存数据宽表;
8、根据所述应用层的稽核应用对包含所有计算因子的内存数据宽表进行数据稽核分析和数据统计,得到稽核分析结果和统计结果;
9、对所述稽核分析结果和统计结果进行沉淀,得到最终分析结果并输出;
10、所述应用层,用于:
11、根据应用场景构建各种稽核应用;
12、所述展示层,用于:
13、对所述组件能力层得到的稽核分析结果、统计结果及最终分析结果进行展示。
14、作为本发明的进一步改进,所述平台层设置mysql数据库;
15、所述组件能力层得到的稽核分析结果和统计结果沉淀归档至所述mysql数据库。
16、作为本发明的进一步改进,所述规则模型包括数据解析规则、数据分析规则、数据预处理规则和数据统计规则;
17、所述规则引擎包括数据汇聚规则引擎、数据清洗加工规则引擎、数据沉淀规则引擎、数据解析规则引擎、数据分析规则引擎和数据报表规则引擎。
18、作为本发明的进一步改进,规则引擎依赖规则模型对待稽核的数据集进行解析、汇聚和清洗加工,得到包含所有计算因子的内存数据宽表;包括:
19、为待稽核的数据集匹配相应的数据预处理规则,所述数据解析规则引擎依赖匹配到的数据预处理规则对数据集进行数据预处理,生成结构化、可序列化的内存数据对象;
20、匹配相应的数据分析规则和数据解析规则,所述数据汇聚规则引擎依赖匹配到的数据分析规则、所述数据清洗加工规则引擎依赖匹配到的数据解析规则对所述内存数据对象进行层层汇聚和清洗加工,最终生成包含所有计算因子的内存数据宽表。
21、作为本发明的进一步改进,在所述平台层创建内存临时表,保存数据预处理后生成的内存数据对象。
22、作为本发明的进一步改进,所述应用层的稽核应用包括固费稽核、出账稽核。
23、作为本发明的进一步改进,根据所述应用层的稽核应用对包含所有计算因子的内存数据宽表进行数据稽核分析和数据统计,得到稽核分析结果和统计结果;包括:
24、匹配相应的数据分析规则,所述数据分析规则引擎依赖匹配到的所述数据分析规则对所述内存数据宽表中的数据进行稽核分析,得到稽核分析结果;
25、匹配相应的数据统计规则,所述数据报表规则引擎依赖匹配到的所述数据统计规则对所述内存数据宽表中的数据进行数据统计,得到统计报表,即为统计结果。
26、作为本发明的进一步改进,
27、对所述内存数据宽表中的数据进行数据统计,包括:根据数据统计规则中的不同规则标签分别对每条数据进行打标签,然后统计各规则标签的数量。
28、作为本发明的进一步改进,对所述稽核分析结果和统计结果进行沉淀,得到最终分析结果并输出;包括:
29、匹配相应的数据分析规则,所述数据沉淀规则引擎依赖匹配到的所述数据分析规则对稽核分析结果及统计结果进行数据分析,得到最终分析结果并输出。
30、本发明还提供了一种基于spark的大数据自动化稽核方法,包括:
31、对于待稽核的数据集及稽核应用,匹配相应的数据预处理规则;
32、数据解析规则引擎依赖所述预处理规则对所述数据集进行预处理,得到预处理后的数据;
33、匹配相应的数据分析规则和数据解析规则,数据汇聚规则引擎依赖匹配到的数据分析规则、数据清洗加工规则引擎依赖匹配到的数据解析规则对预处理后的数据进行多次汇聚和清洗加工,得到包含所有计算因子的内存数据宽表;
34、匹配相应的数据分析规则和数据统计规则,数据分析规则引擎依赖匹配到的数据分析规则、数据报表规则引擎依赖匹配到的数据统计规则,依次对所述内存数据宽表进行数据稽核分析和进行数据统计,得到待沉淀的数据集;
35、匹配相应的数据分析规则,数据沉淀规则引擎依赖匹配到的数据分析规则对所述待沉淀的数据集进行沉淀,得到最终分析结果并输出。
36、与现有技术相比,本发明的有益效果为:
37、本发明采用hadoop+spark生态体系,其中,hadoop分布式文件系统解决了解决大数据的存储问题,spark分布式计算框架,使用内存计算来解决大数据计算算力性能的问题,同时,本发明通过一套功能强大的规则模型以及适配的规则引擎,配合hadoop+spark来实现大数据的配置化、自动化的数据解析、数据预处理、加工汇聚、数据分析并最终沉淀出分析结果以及统计报表的功能;设置规则模型,解决了传统大数据分析人员针对各种业务数据需要频繁编写脚本或代码去实现数据对象的结构化、序列化的问题。
38、本发明设置规则模型,还解决了后台测试人员对于密集计算型的业务应用的批量测试对账步骤多且杂,难以管理的问题。
技术特征:
1.一种基于spark的大数据自动化稽核系统,其特征在于,包括:平台层、组件能力层、应用层和展示层;
2.根据权利要求1所述的基于spark的大数据自动化稽核方法,其特征在于:所述平台层设置mysql数据库;
3.根据权利要求1所述的基于spark的大数据自动化稽核方法,其特征在于:所述规则模型包括数据解析规则、数据分析规则、数据预处理规则和数据统计规则;
4.根据权利要求3所述的基于spark的大数据自动化稽核方法,其特征在于:规则引擎依赖规则模型对待稽核的数据集进行解析、汇聚和清洗加工,得到包含所有计算因子的内存数据宽表;包括:
5.根据权利要求4所述的基于spark的大数据自动化稽核方法,其特征在于:在所述平台层创建内存临时表,保存数据预处理后生成的内存数据对象。
6.根据权利要求1所述的基于spark的大数据自动化稽核方法,其特征在于:所述应用层的稽核应用包括固费稽核、出账稽核。
7.根据权利要求3所述的基于spark的大数据自动化稽核方法,其特征在于:根据所述应用层的稽核应用对包含所有计算因子的内存数据宽表进行数据稽核分析和数据统计,得到稽核分析结果和统计结果;包括:
8.根据权利要求7所述的基于spark的大数据自动化稽核方法,其特征在于:
9.根据权利要求3所述的基于spark的大数据自动化稽核方法,其特征在于:对所述稽核分析结果和统计结果进行沉淀,得到最终分析结果并输出;包括:
10.一种基于spark的大数据自动化稽核方法,应用如权利要求1~9任一项所述的基于spark的大数据自动化稽核系统,其特征在于,包括:
技术总结
本发明提供了一种基于SPARK的大数据自动化稽核系统及方法,涉及互联网架构领域,包括:平台层,采用hadoop+Spark生态体系,为组件能力层提供数据处理支撑;组件能力层,设置规则模型和规则引擎,规则引擎依赖规则模型对待稽核的数据集进行解析、汇聚和清洗加工,得到包含所有计算因子的内存数据宽表;根据稽核应用对包含所有计算因子的内存数据宽表进行数据稽核分析和数据统计;对稽核分析结果和统计结果进行沉淀,得到最终分析结果并输出;展示层,对组件能力层得到的稽核分析结果、统计结果及最终分析结果进行展示。本发明实现了大数据场景下,数据的快速配置化、自动化批量比对,为固费业务稽核等大数据处理业务提供保障。
技术研发人员:蒋敏钟
受保护的技术使用者:北京思特奇信息技术股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!