一种数据模型抽取方法及系统、终端、介质与流程
本发明涉及大数据领域,具体地,涉及一种数据模型抽取方法及系统、终端、介质。
背景技术:
1、etl是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
2、在现有技术中,复杂的数据处理都要借助上述etl完成,同时为了提升查询性能,会把数据模型的数据抽取到缓存库,但必须是etl任务完成之后,才执行数据模型的抽取。
3、技术人员在指标模型中建好维表或事实表,需要绑定etl进行灌数;而生成的指标模式默认是直连,由于是模型表,数据量太多直连性能出现问题,所以改成“抽取模式”,而现有技术中数据模型抽取模式下会自动生成计划任务,作业流调度etl也会设一个计划任务把业务库数据抽取到指定数据库,数据模型的抽取和etl的调度是分开执行的,会有一个先后顺序或时间差,如果etl中具体任务执行不成功即没有把最新数据更新到表中,会导致数据模型在定好的时间抽取就没有意义或者说数据不准确。
4、经检索,申请号为cn104732310a的中国发明公开了一种基于统一数据模型的数据集成方法,该方法通过统一数据模型和数据抽取机制建立起各外部数据源所存储的实体数据对象与虚拟数据对象之间的一一对应关系,通过数据关联关系建立起不同虚拟数据对象之间的联系,并通过统一虚拟数据中心实现所有虚拟数据对象的统一管理;由于实体数据对象与虚拟数据对象之间的一一对应关系,从而实现对实体数据对象的统一管理。其只涉及固有数据读取,无法在虚拟数据中心对“脏数据”进行管理,并且不能适应数字经济时代背景下大级别数据量读写性能的需求。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种数据模型抽取方法及系统、终端、介质,能够有效保证数据的准确性和一致性。
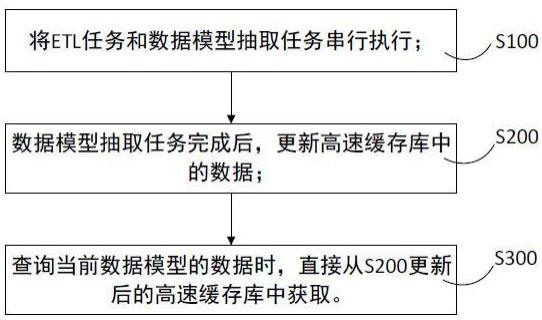
2、根据本发明的一个方面,提供一种数据模型抽取方法,包括一种数据模型抽取方法,包括:
3、将etl任务和数据模型抽取任务串行执行;
4、所述数据模型抽取任务完成后,更新高速缓存库中的数据模型;
5、查询当前数据模型的数据时,直接从所述高速缓存库中获取。
6、优选地,所述将etl任务和数据模型抽取任务串行执行,包括:
7、建立若干etl任务;
8、建立作业流;
9、将所述作业流与所述etl任务串联;
10、将所述数据模型抽取任务与所述etl任务串联;
11、设置所述作业流的定时任务;
12、执行所述作业流的定时任务,若执行成功,执行所述etl任务,即etl灌输到指定数据库表,并进行所述数据模型抽取任务;若执行失败,根据重试机制,再次执行所述作业流。
13、优选地,所述作业流由多个任务组成,包括etl和数据模型抽取任务。
14、优选地,所述重试机制为通过监听作业流定时执行的状态,判断是否在给定的时间后自动重新运行当前运行失败的作业流。
15、优选地,若是所述作业流的定时任务执行失败,能够直接判断是所述etl任务还是所述数据模型抽取任务的执行失败。
16、优选地,所述从所述高速缓存库中获取数据时,能够秒级获取亿级数据结果。
17、优选地,一个数据模型执行同个作业流多次或者执行多个不同的作业流。
18、根据本发明的第二个方面,提供一种数据模型抽取系统,包括:
19、串行模块,该模块将etl任务和数据模型抽取任务串行执行;
20、更新模块,所述数据模型抽取任务完成后,更新高速缓存库中的数据模型;
21、查询模块,查询当前数据模型的数据时,直接从所述高速缓存库中获取。
22、根据本发明的第三方面,提供一种终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时用于执行所述的数据模型抽取方法,或,运行所述的数据模型抽取系统。
23、根据本发明的第四方面,提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行可用于执行所述的数据模型抽取方法,或,运行所述的数据模型抽取系统。
24、与现有技术相比,本发明实施例具有如下至少一种有益效果:
25、本发明实施例中提供的数据模型抽取方法和系统,将业务库数据抽取到指定数据库以及数据模型抽取任务串行执行,能够有效保证数据的准确性和一致性。
26、本发明实施例中提供的数据模型抽取方法和系统,在产品的作业流里面,可以很清晰地看到是etl任务过程失败,还是数据模型抽取过程失败。相比之前两个定时任务错开执行的方式,提高故障排查效率,简化运维成本。
27、本发明实施例中提供的数据模型抽取方法和系统,数据模型抽取到高速缓存库后,再次查询当前数据集或分析的数据时,能够直接从高速缓存库获取数据,保证秒级获取大级别量的数据结果,提高系统性能。
28、本发明实施例中提供的数据模型抽取方法和系统,其所进行的是不同于现有技术中的数据模型之间的抽取,即在数据产生之后,不会立即对数据进行清洗,而是在固定的周期进行etl(数据清洗、处理和加工),对完成了etl的数据库数据进行抽取并进行建模,抽取的数据存储到本地的数据仓库,以获得更快的分析速度和性能表现。现有技术中的直连数据模型主要依赖数据库服务器本身的性能,自助式分析性能差于数据模型之间的抽取。
技术特征:
1.一种数据模型抽取方法,其特征在于,包括:
2.根据权利要求1所述的一种数据模型抽取方法,其特征在于,所述将etl任务和数据模型抽取任务串行执行,包括:
3.根据权利要求2所述的一种数据模型抽取方法,其特征在于,所述作业流由多个任务组成,包括所述etl任务和所述数据模型抽取任务。
4.根据权利要求2所述的一种数据模型抽取方法,其特征在于,所述重试机制为通过监听所述作业流定时执行的状态,判断是否在给定的时间后自动重新运行当前运行失败的作业流。
5.根据权利要求2所述的一种数据模型抽取方法,其特征在于,若是所述作业流的定时任务执行失败,能够直接判断是所述etl任务还是所述数据模型抽取任务的执行失败。
6.根据权利要求1所述的一种数据模型抽取方法,其特征在于,从所述高速缓存库中获取数据时,能够秒级获取亿级数据结果。
7.根据权利要求1所述的一种数据模型抽取方法,其特征在于,一个数据模型执行同个作业流多次或者执行多个不同的作业流。
8.一种数据模型抽取系统,其特征在于,包括:
9.一种终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时用于执行权利要求1-7中任一项所述的数据模型抽取方法,或,运行权利要求8所述的数据模型抽取系统。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行用于执行权利要求1-7中任一项所述的数据模型抽取方法,或,运行权利要求8所述的数据模型抽取系统。
技术总结
本发明提供一种数据模型抽取方法和系统、终端和介质,包括:将ETL任务和数据模型抽取任务串行执行;数据模型抽取任务完成后,更新高速缓存库中的数据模型;查询当前数据模型的数据时,直接从高速缓存库中获取。本发明将业务库数据抽取到指定数据库以及数据模型抽取任务串行执行,有效保证数据的准确性和一致性;在产品的作业流里面,可以很清晰地看到是ETL抽取过程失败,还是数据模型抽取过程失败。相比之前两个定时任务错开执行的方式,比较清晰,提高故障排查效率,简化运维成本;本发明数据模型抽取到高速缓存库后,再次查询当前数据集或分析的数据时,能够直接从高速缓存库获取数据,保证秒级获取大级别量的数据结果,提高系统性能。
技术研发人员:吴华夫,黄浩,黄潮勇,张亿仙,刘芳
受保护的技术使用者:广州思迈特软件有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!