基于自动机器学习的自适应文本分类方法及装置与流程
本发明主要涉及机器学习的,具体为基于自动机器学习的自适应文本分类方法及装置。
背景技术:
1、随着人工智能领域的发展,人们对于文本分类的技术要求愈发提高,不论是作为ocr识别技术的后续处理程序,还是新闻分类,虚假新闻识别,垃圾邮件识别等需求,文本分类的精确性和对特定领域的适应性需求愈发的急迫。
2、在现有技术中,想要进行文本分类的识别任务,要考虑数据的预处理,模型的选择与搭建,实体信息的识别。目前主流做法是使用bert等大规模预训练模型来做,但是这种方法模型过大,对算力要求很高,简易模型又在精确度和适用性上有所欠缺,并且发明人认为分类效率和效果较差,无法适应目前人工智能的发展。
技术实现思路
1、为了改善上述背景技术的问题,本发明提供一种基于自动机器学习的自适应文本分类方法及装置。
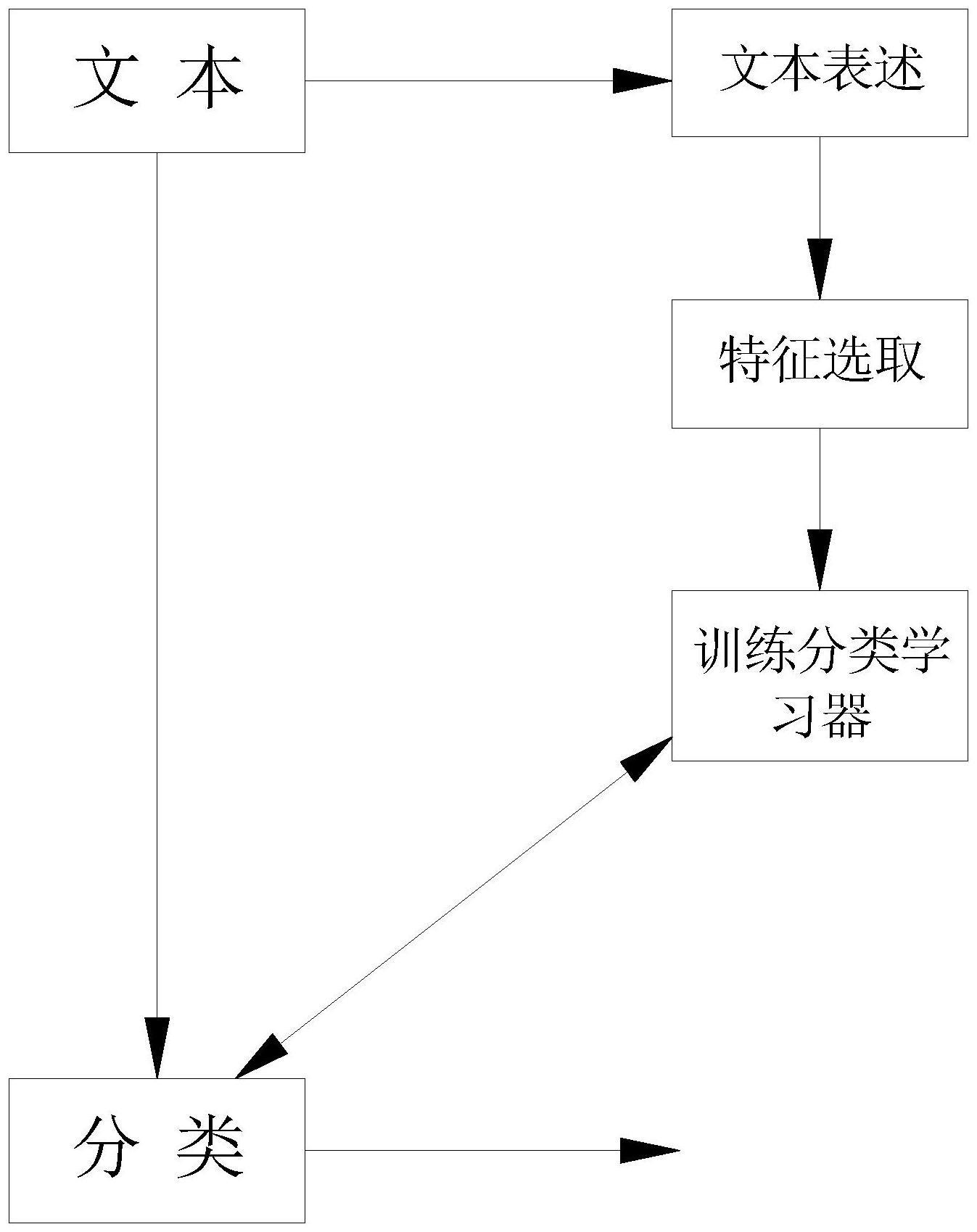
2、本发明采用如下的技术方案:一种基于自动机器学习的自适应文本分类方法:所述方法包括以下步骤:
3、s1:文本表达,将非结构化的文本文档表示为机器易于处理的形式,文本表达包括文本预处理和分词技术;
4、s2:特征抽取;
5、d、根据文本预处理和分词技术在在初始全特征集基础上变成一个特征子集;
6、e、根据特征提取算法对特征的重要性进行评估;
7、f、然后进行重要排序,最好根据提取阈值或提取比率完成提取,提取的特征集用于之后的训练和分类过程;
8、s3:学习器训练和分类:
9、a、获取分类任务对应的训练用提取特征集;
10、b、根据特征集进行神经架构搜索,构建用于分类的神经网络模型;
11、c、对构建好的神经网络模型进行训练;
12、d、将待检测文本数据输入所述神经网络模型;
13、s4:输出分类结果。
14、进一步的,其中所述步骤s1中,还包括以下步骤:
15、s1—1:文本预处理:
16、c、文档建模:能够高效地处理真实文本,一种理想的形式化表示方法,通用模型如布尔模型、布尔模型性、向量空间模型(vsm);
17、d、向量模型:d为一个包含m个文档的文档集合di为第i个文档的特征向量,则有d={d1,d2,…,dm},di=(dildi2…dij),i=12,…,mj=1,2,…,n。其中dij(i=1,2,…,m;j=1,2,……,n);为文档di中第j个词条tj的权值它一般被定义为tj在di中出现的频率tij的函数,例如采用tf一idf函数,即dij=tij*log(n/nj)。其中n是文档数据库中文总数,nj是文档数据库含有词条tj的文档数目。假设用户给定的文档向量为d2,未知的文档向量为q,两者的相似程度可用两向量的夹角余弦来度量,夹角越小说明相似度越高;通过上述向量空间模型,文本数据转换成机器可以处理的结构化数据。
18、s1—2:分词技术:
19、d、去掉一部分低频词,只在一两个文本中出现过;
20、e、去掉停止词,不携带任何信息;
21、f、去掉一部分标记信息,主要针对网页文本或其他标记语言文本。
22、根据本发明还提供一种基于自动机器学习的自适应文本分类装置,其特征在于,包括:
23、输入模块:将非结构化的文本文档表示为机器易于处理的形式,
24、预处理模块:能够高效地处理真实文本,一种理想的形式化表示方法,应用向量空间模型,通过向量空间模型,将文本数据转换成机器可以处理的结构化数据;
25、分词模块:去掉一部分低频词,只在一两个文本中出现过;去掉停止词,不携带任何信息;去掉一部分标记信息,主要针对网页文本或其他标记语言文本;
26、提取模块:根据文本预处理和分词技术在在初始全特征集基础上变成一个特征子集;根据特征提取算法对特征的重要性进行评估;然后进行重要排序,最好根据提取阈值或提取比率完成提取,提取的特征集;
27、训练和分类模块:获取分类任务对应的训练用提取特征集;根据特征集进行神经架构搜索,构建用于分类的神经网络模型;对构建好的神经网络模型进行训练;将待检测文本数据输入所述神经网络模型。
28、本发明还提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如权利要求1至2任一项所述基于自动机器学习的自适应文本分类方法的步骤。
29、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至2任一项所述基于自动机器学习的自适应文本分类方法的步骤。
30、与现有技术相比,本发明的有益效果为:
31、本发明针对不同的分类任务,自适应的搭建出最合适的模型架构,同时本发明考虑了字词信息的结合,以及模型架构的压缩,大幅度的提升了模型的精确度,实现高效率高效果,操作工艺简单,适应人工智能的发展。
32、以下将结合附图与具体的实施例对本发明进行详细的解释说明。
技术特征:
1.一种基于自动机器学习的自适应文本分类方法,其特征在于:所述方法包括以下步骤:
2.根据权利要求1所述的基于自动机器学习的自适应文本分类方法,其特征在于:其中所述步骤s1中,还包括以下步骤:
3.一种基于自动机器学习的自适应文本分类装置,其特征在于,包括:
4.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至2任一项所述基于自动机器学习的自适应文本分类方法的步骤。
5.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至2任一项所述基于自动机器学习的自适应文本分类方法的步骤。
技术总结
本发明提供一种基于自动机器学习的自适应文本分类方法及装置,其特征在于:所述方法包括以下步骤:S1:文本表达;S2:特征抽取;S3:学习器训练和分类;S4:输出分类结果,所述装置包括输入模块、预处理模块、分词模块、提取模块、训练和分类模块,本发明针对不同的分类任务,自适应的搭建出最合适的模型架构,同时本发明考虑了字词信息的结合,以及模型架构的压缩,大幅度的提升了模型的精确度,实现高效率高效果,操作工艺简单,适应人工智能的发展。
技术研发人员:张晓荣,李岩,薛鹏程
受保护的技术使用者:国网甘肃省电力公司天水供电公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!