一种保证分布式文件系统数据同步一致性的方法及系统与流程
本发明属于大数据处理,具体涉及一种保证分布式文件系统数据同步一致性的方法及系统。
背景技术:
1、随着近年来数据爆炸式的增长,数据仓库的概念在数据治理领域越来越多的被提及,其中在绝大部分场景中用的是基于分布式文件系统hdfs存储的离线数据仓库,其采用hdfs+hive的技术架构,基于spark计算引擎进行数据处理,既能够解决大数据量存储的问题,又能进行类关系库式的查询分析,在t+1的场景中应用广泛。
2、在一些公司企业或单位中,特别注重业务数据的一致性,因为对于业务系统来讲,若不能保证数据一致性,下游业务必然会出现延时。
3、在数仓建设中,基于hdfs分布式文件系统存储,无法直接对文件内容进行更新,都是采用累加的方式进行数据同步,数仓中的数据在业务逻辑上会存在重复,或者采用分区的方式全量抽取,抽取完成后在hive建表时进行文件路径切换。
4、在hdfs+hive架构中,对于不断增长的日志类数据,hdfs通过分区方式可以很好的解决;对于业务类数据,由于存在更新的情况,若数据量小,可通过全量+分区切换方式解决,但数据量大时,定时任务全量抽取就很难保证数据及时性,甚至t+1也可能无法保证能够及时更新,并且定时任务全量抽取也会对源库造成较大压力;若采用增量分区的方式存储,又无法保证数据一致性,在hdfs中会存在同一个业务主键的多条数据,下游使用之前必须先去重取最新,才能继续进行数据流转,经常会出现数据分析部门诟病etl部门无法保证数据的一致性问题。
5、有鉴于此,提出一种保证分布式文件系统数据同步一致性的方法及系统是非常具有意义的。
技术实现思路
1、为了解决现有无法保证数据的一致性的问题,本发明提供一种保证分布式文件系统数据同步一致性的方法及系统,以解决上述存在的技术缺陷问题。
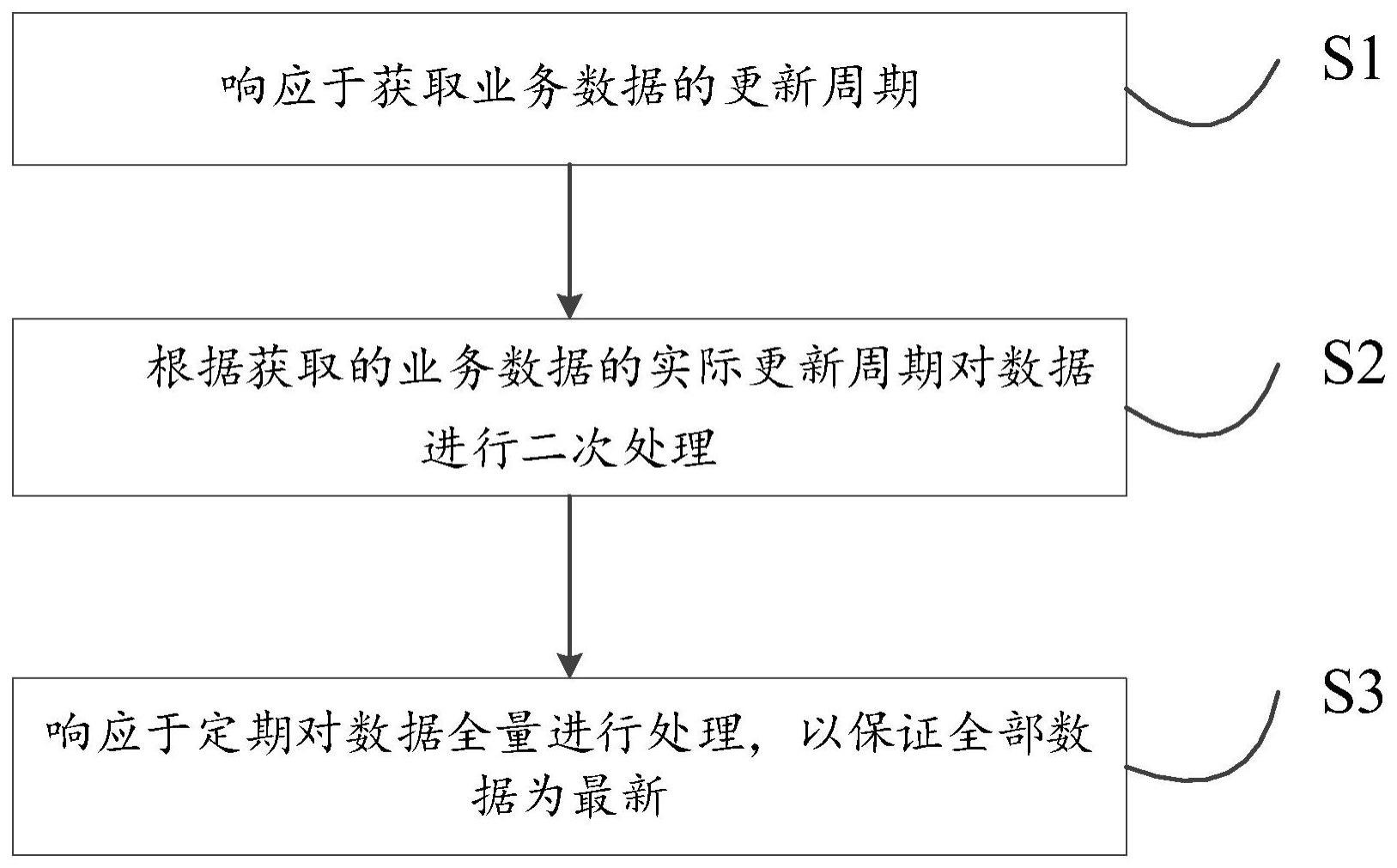
2、第一方面,本发明提出了一种保证分布式文件系统数据同步一致性的方法,该方法包括如下步骤:
3、响应于获取业务数据的更新周期;
4、根据获取的业务数据的实际更新周期对数据进行二次处理;
5、响应于定期对数据全量进行处理,以保证全部数据为最新。
6、优选的,具体包括:
7、根据当前任务时间在目标库内取更新周期内的数据文件;
8、利用利用spark计算引擎进行计算,并将数据写回原分区;
9、将计算后的数据文件移动到备份目录,并刷新hive表。
10、进一步优选的,还包括:在数据同步时,根据增量数据大小进行合适的分区选择,分区按年、月、天、小时来处理,通过控制数据同步的调度频率来保证数据及时性。
11、进一步优选的,二次处理具体包括:
12、利用spark计算引擎,将hdfs文件数据写入内存,借助spark-sql进行去重取最新;
13、将数据回写到hdfs对应分区中,以保证数据的一致性。
14、进一步优选的,二次处理具体还包括:
15、依据业务数据的实际更新周期来进行计算,每次任务只取最近一段时间的数据进行计算取最新。
16、第二方面,本发明实施例还提供一种保证分布式文件系统数据同步一致性的系统,包括:
17、获取模块,用于响应于获取业务数据的更新周期;
18、二次处理模块,用于根据获取的业务数据的实际更新周期对数据进行二次处理;
19、全量处理模块,用于响应于定期对数据全量进行处理,以保证全部数据为最新。
20、进一步优选的,还包括:
21、计算引擎模块,用于利用利用spark计算引擎进行计算,并将数据写回原分区;
22、数据备份模块,用于将计算后的数据文件移动到备份目录,并刷新hive表。
23、第三方面,本发明实施例提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如第一方面中任一实现方式描述的方法。
24、第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面中任一实现方式描述的方法。
25、与现有技术相比,本发明的有益成果在于:
26、(1)本发明在基于hdfs存储+hive分析的离线数仓中使用,在各行各业保证业务数据一致性问题中都适用,特别针对同步的数据量规模大、数据实际更新周期短的场景;通过对大数据量的业务数据采用根据业务数据实际更新周期进行二次处理,结合定期全量处理的方式保证数据一致性,由于读源头库的数据量减少,降低了源头库的读压力。
27、(2)每次任务拉取业务数据的实际更新周期内的数据进行二次处理,计算的数据体量整体降低,节约了计算资源;处理过程可以选择利用客户端服务器内存进行计算,也可以利用spark集群的内存进行计算,灵活便捷。
28、(3)下游数据使用方不需要再执行去重取最新的操作,提高了数据生产效率,也可以让数据使用方不在因为数据不一致对etl方进行诟病。
技术特征:
1.一种保证分布式文件系统数据同步一致性的方法,其特征在于,该方法包括如下步骤:
2.根据权利要求1所述的保证分布式文件系统数据同步一致性的方法,其特征在于,具体包括:
3.根据权利要求2所述的保证分布式文件系统数据同步一致性的方法,其特征在于,还包括:在数据同步时,根据增量数据大小进行合适的分区选择,分区按年、月、天、小时来处理,通过控制数据同步的调度频率来保证数据及时性。
4.根据权利要求3所述的保证分布式文件系统数据同步一致性的方法,其特征在于,二次处理具体包括:
5.根据权利要求4所述的保证分布式文件系统数据同步一致性的方法,其特征在于,二次处理具体还包括:
6.一种保证分布式文件系统数据同步一致性的系统,其特征在于,包括:
7.根据权利要求6所述的保证分布式文件系统数据同步一致性的系统,其特征在于,还包括:
8.一种电子设备,包括:
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1至5中任一所述的方法。
技术总结
本发明提出了一种保证分布式文件系统数据同步一致性的方法及系统。该方法包括如下步骤:响应于获取业务数据的更新周期;根据获取的业务数据的实际更新周期对数据进行二次处理;响应于定期对数据全量进行处理,以保证全部数据为最新。在基于HDFS存储+HIVE分析的离线数仓中使用,在各行各业保证业务数据一致性问题中都适用,特别针对同步的数据量规模大、数据实际更新周期短的场景;通过对大数据量的业务数据采用根据业务数据实际更新周期进行二次处理,结合定期全量处理的方式保证数据一致性,由于读源头库的数据量减少,降低了源头库的读压力。
技术研发人员:沈洋,赵文霞,徐璐,刘襄雄,霍伟波,利嘉明
受保护的技术使用者:厦门市美亚柏科信息股份有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!