一种基于级联解码的表格结构识别方法
本发明涉及一种基于级联解码的表格结构识别方法,属于半结构化文本生成。
背景技术:
1、表格作为一种常用的数据载体,具备易比较分析、信息密度大等特点,常被用来展示重要实验数据、生产数据;在如今的智能化时代,能够快速准确的识别、分析这些数据会给社会企业、研究机构带来强大的竞争力;表格结构识别任务旨在从表格图像中得到单元格的行列信息,准确的识别出表格结构是分析表格内容的重要基础。
2、当前,基于表格图像恢复出表格对应的html序列的表格结构识别方法中,都是使用一级解码器解码得到表格中的所有元素对应的html标签,此类方法在推理过程中会随着表格复杂度的提高生成更长的html序列,生成更长的html序列意味着容易产生更多的错误。因此,研究一种避免生成较长html序列,准确识别表格结构信息的方法具有重要意义。
技术实现思路
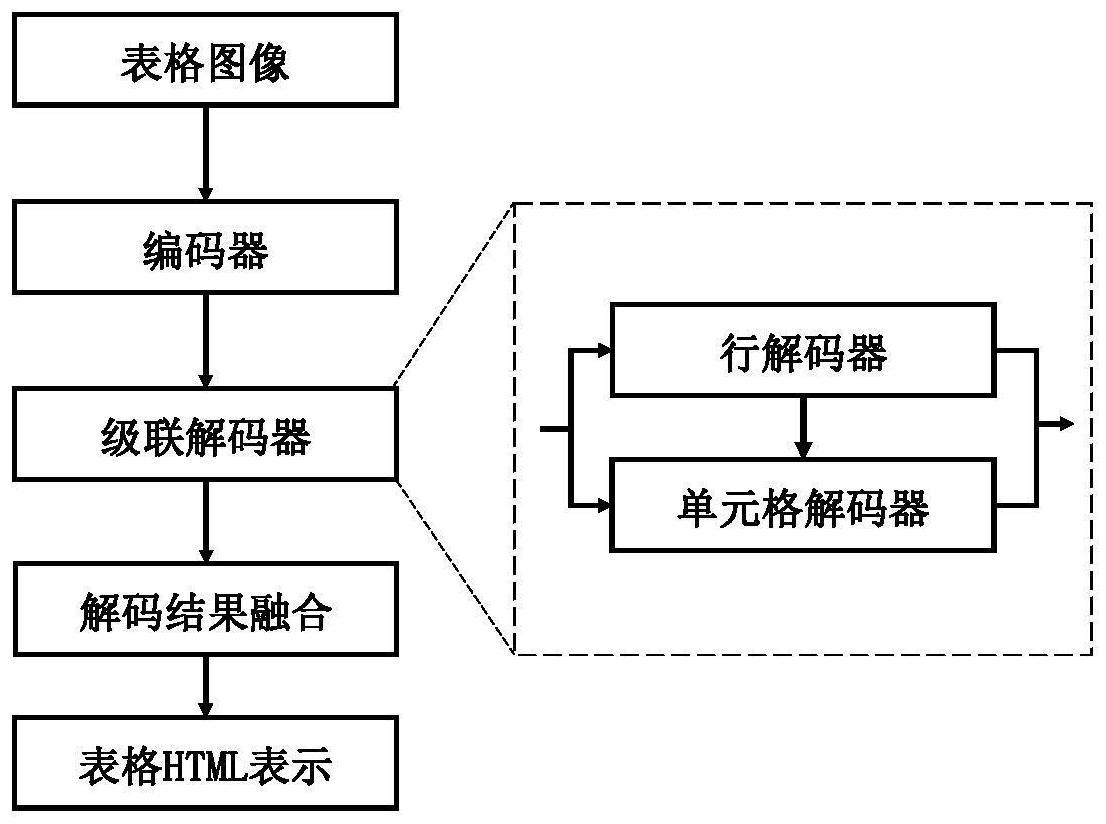
1、本发明要解决的技术问题是针对现有技术的不足,提供一种基于级联解码的表格结构识别方法,分两阶段对编码结果进行解码,第一阶段根据编码结果对表头、表体、行进行解码,第二阶段根据第一阶段解码结果与编码结果对单元格标签和单元格属性进行解码;级联解码结构的设计缩短了每级解码器解码时生成的标签长度,一定程度上解决了在生成较长html序列时准确率低的问题。
2、本发明的技术方案是:一种基于级联解码的表格结构识别方法,首先将表格图像输入到编码器进行编码,用以捕获所输入表格图像的视觉特征;然后将编码结果分别输入到行解码器和单元格解码器中;其中,首先将编码结果单独输入到行解码器解码得到表头、表体、行等标记;再将编码结果与行解码器解码结果输入单元格解码器解码得到单元格标记以及单元格行列跨度属性;最后将两种解码器解码结果融合得到相应表格图像的结构化html序列表示。
3、具体步骤为:
4、step1:利用编码器从表格图像中提取视觉特征。
5、step2:对编码器提取的视觉特征,单独输入行解码器进行解码,行解码器的训练过程如下:
6、训练数据:对公开数据集注释文件进行处理,只保留表头标签、表体标签、行标签。
7、训练模型及模型推理:在模型训练过程中,使用融合注意力机制的循环单元模块从编码器提取的视觉特征中学习表格行特征;在推理过程中只生成表头标签、标题标签和行标签。
8、step3:对行解码器解码结果,与编码器提取的视觉特征一同输入单元格解码器,用于对每一行中所有单元格对应的单元格标签和单元格属性进行解码。
9、训练模型:在模型训练过程中,使用融合注意力机制的循环单元模块从编码器所提取的视觉特征和行解码器隐藏层特征中学习单元格特征。
10、模型推理:在模型推理过程中,根据行解码器解码结果决定单元格解码器是否生成单元格标签、单元格行列跨度属性。
11、step4:融合行解码器解码结果和单元格解码器解码结果以得到该表格图像对应的完整html序列。
12、所述step1中,编码器采用resnet18作为主干网络提取视觉特征,并利用fpn增强视觉特征。
13、所述step2中的处理训练数据过程中,对公开数据集pubtabnet注释文件进行处理,只保留注释文件中的表头标签(‘<thead>’、‘</thead>’)、表体标签(‘<tbody>’、‘</tbody>’)、行标签(‘<tr>’、‘</tr>’)。
14、所述step2中的行解码器由基于注意力机制的gru模块和gru隐藏层特征解码器模块组成;训练过程中gru从表格图像视觉特征和上一层隐藏层特征中学习表头、表体、行对应特征;模型推理时通过gru隐藏层特征解码器生成表头标签(‘<thead>’、‘</thead>’)、表体标签(‘<tbody>’、‘</tbody>’)、行标签(‘<tr>’、‘</tr>’)。
15、所述step2中生成表头标签、表体标签、行标签的行解码器的损失函数lrd采用交叉熵损失函数:
16、
17、其中,n表示生成标签总数,i表示生成的第i个标签,6种类别是指表头、表体、行对应的开始标签和结束标签,yic表示每个样本的类别标签,pic表示第i个标签属于类别c的概率。
18、所述step3中的单元格解码器由基于注意力机制的gru模块和gru隐藏层特征解码器模块组成;在训练模型过程中,gru从表格图像视觉特征和行解码器隐藏层特征中学习单元格标签(‘<td>’、‘</td>’)特征和单元格属性(‘colspan’、‘rowspan’)特征。
19、所述step3中生成单元格标签与单元格属性的单元格解码器的损失函数lcd采用交叉熵损失函数:
20、
21、其中,n表示生成标签总数,i表示生成的第i个标签,4种类别是指单元格对应的开始标签和结束标签和行列跨度属性,yic表示每个样本的类别标签,pic表示第i个标签属于类别c的概率。
22、所述step3中单元格解码器中除了对单元格标签和单元格属性标签进行解码,还使用单元格坐标解码器以回归出单元格坐标,回归得到单元格边界框的损失函数lb-box采用smooth l1 loss:
23、
24、其中,x=|yi-f(xi)|,yi表示真实边界框值,f(xi)表示预测边界框值。
25、最终,网络整体损失lall计算方法如下:
26、lall=λ1lrd+λ2lcd+λ3lb-box
27、其中,λ1,λ2,λ3∈[0,1]为超参数。
28、所述step3中的模型推理过程中,若某个切片在行解码器中解码结果是以‘<tr>’标签开头的序列,则单元格解码器将此序列对应的行解码器隐藏层特征与表格图像视觉特征相结合,推理生成该序列中的单元格标签与单元格属性,若是不以‘<tr>’标签开头的序列,则将该序列中开头标签和与之对应的结束标签之外的标签全部删除。
29、本发明的有益效果是:本发明在已有表格图像到半结构化文本生成模型基础上,采用级联解码器对表格图像视觉特征分别进行行解码和单元格解码;其中,行解码器只针对表头、表体、行区域进行解码,单元格解码器只针对单元格区域进行解码,不同区域采用不同解码器解码,能够有效解决复杂表格解码时生成的较长html序列中准确率低的问题。
技术特征:
1.一种基于级联解码的表格结构识别方法,其特征在于:
2.根据权利要求1所述的基于级联解码的表格结构识别方法,其特征在于:所述step1中,编码器采用残差网络作为主干网络提取视觉特征,并利用特征金字塔网络增强视觉特征。
3.根据权利要求1所述的基于级联解码的表格结构识别方法,其特征在于:所述step2中的处理训练数据过程中,对公开数据集pubtabnet注释文件进行处理,只保留注释文件中的表头标签(‘<thead>’、‘</thead>’)、表体标签(‘<tbody>’、‘</tbody>’)、行标签(‘<tr>’、‘</tr>’)。
4.根据权利要求3所述的基于级联解码的表格结构识别方法,其特征在于:所述step2中的行解码器由基于注意力机制的循环单元模块和隐藏层特征解码模块组成;训练过程中循环单元根据所述处理后的注释文件从表格图像视觉特征中学习表头、表体、行对应视觉特征;模型推理时生成表头标签(‘<thead>’、‘</thead>’)、表体标签(‘<tbody>’、‘</tbody>’)、行标签(‘<tr>’、‘</tr>’)。
5.根据权利要求1所述的基于级联解码的表格结构识别方法,其特征在于:所述step3中的单元格解码器由基于注意力机制的循环单元模块和隐藏层特征解码器模块组成;在训练模型过程中,循环单元从表格图像视觉特征和行解码器隐藏层特征中学习单元格标签(‘<td>’、‘</td>’)特征和单元格属性(‘colspan’、‘rowspan’)特征。
6.根据权利要求1所述的基于级联解码的表格结构识别方法,其特征在于:所述step3中的模型推理过程中,若某个切片在行解码器中解码结果是以‘<tr>’标签开头的序列,则单元格解码器将此序列对应的行解码器隐藏层特征与表格图像视觉特征相结合,然后推理生成该序列中所有单元格对应的单元格标签与单元格属性,若是不以‘<tr>’标签开头的序列,则将该序列中开头标签和与之对应的结束标签之外的标签全部删除。
技术总结
本发明涉及一种基于级联解码的表格结构识别方法,属于半结构化文本生成技术领域。首先将表格图像输入到编码器进行编码,用以捕获所输入表格图像的视觉特征;然后将编码结果分别输入到行解码器和单元格解码器中;其中,首先将编码结果单独输入到行解码器解码得到表头、表体、行等标记;再将编码结果与行解码器解码结果输入单元格解码器解码得到单元格标记以及单元格行列跨度属性;最后将两种解码器解码结果融合得到相应表格图像的结构化HTML序列表示。本发明将编码结果分别在行、单元格两个层面上进行解码,分级解码结构保证每个解码器不会生成较长的HTML序列,解决了生成较长序列时的错误累计问题,能够更准确的识别表格结构信息。
技术研发人员:刘英莉,张广涛,郑剑锋,沈韬
受保护的技术使用者:昆明理工大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!