一种基于像素值波动的图书信息提取方法与流程
本发明属于图像处理,尤其涉及一种基于像素值波动的图书信息提取方法。
背景技术:
1、图书信息识别是一种依据图像的特征(如统计或几何特征等),从图像中提取出书名和作者信息。目前通用的解决方案是:首先检测图像中检测目标(如书名和作者的信息)的位置坐标,然后提取出目标的图像特征,最后从数据库中的找到最相似的内容。
2、图书信息识别属于ocr识别的一种,图书信息的目标特征通常分为视觉特征、像素统计特征、图像变换系数特征和图像代数特征等,特征提取就是针对目标的某些特征进行的,它是对目标进行特征建模的过程。特征提取过程包括:采集原始图像、目标检测(定位图书的在图像中的位置和大小)、图像预处理(图像矫正、噪声过滤等)以及特征提取(识别关键点并生成特征向量)。目前,特征提取主要有传统特征的提取算法(sift、lbp、hog等)和基于深度学习的提取方法等两大类。
3、目前,传统ocr识别的相关算法精度已经达到了很高的水准,在特定场景下,可以提取到高质量的特征数据并能相对准确识别出目标的内容。但图书信息的识别比传统的ocr识别更复杂,主要体现在以下两个方面:
4、1.因为传统的ocr识别主要识别英文字母和数字,而图书信息除了需要识别英文字母和数字外,还需要识别汉字和特殊符号。
5、2.图书封面各不相同,图像中干扰信息较多,很难提取到高质量的特征数据。
技术实现思路
1、本发明的目的是提供一种基于像素值波动的图书信息提取方法,解决了在图书信息提取时,得到稳定的特征的技术问题。
2、为实现上述目的,本发明采用如下技术方案:
3、一种基于像素值波动的图书信息提取方法,包括如下步骤:
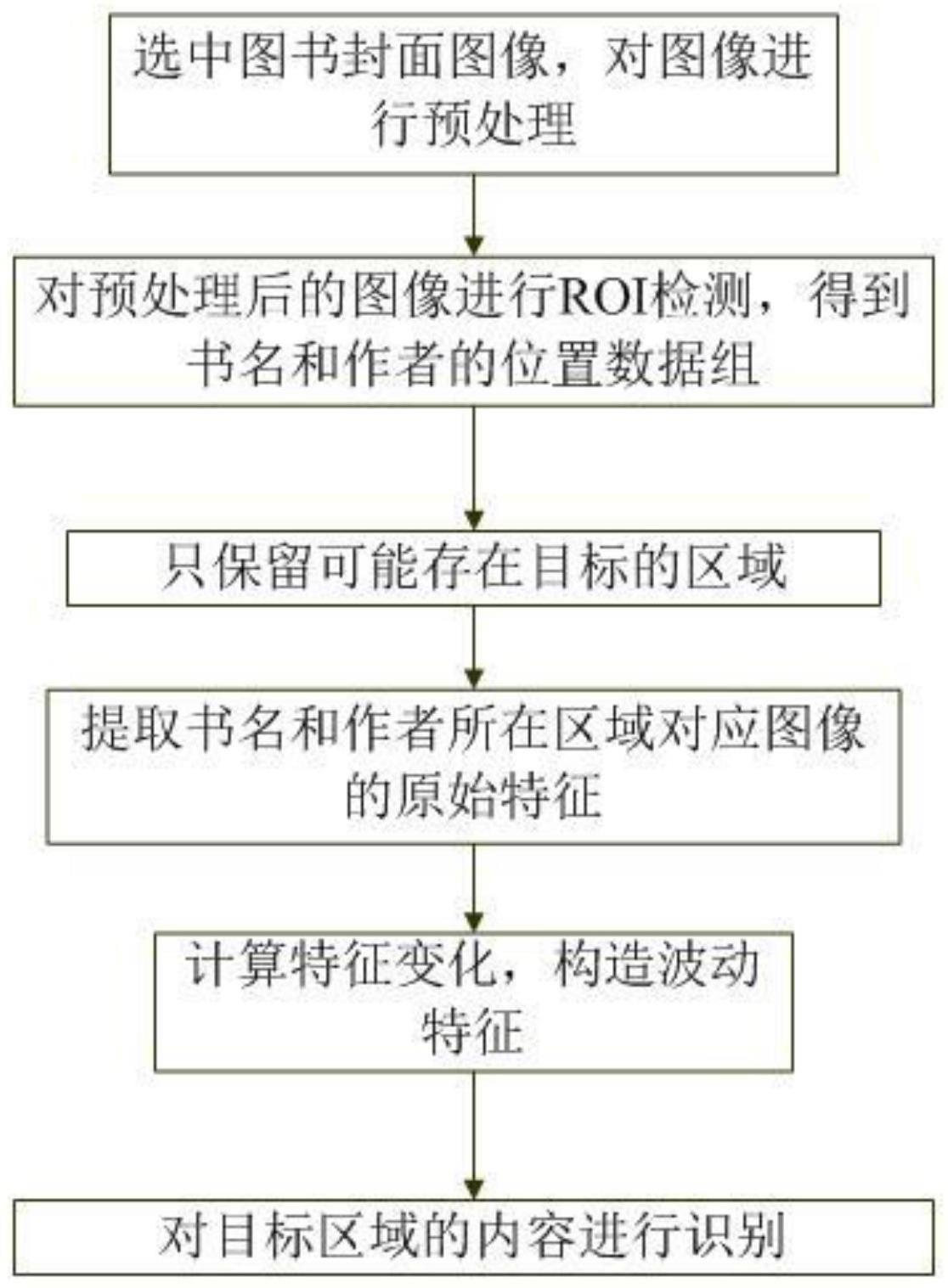
4、步骤1:建立图像处理服务器,在图像处理服务器中建立预处理模块、roi模块、区域识别模块、特征提取模块、特征构造模块和特征识别模块,图像处理服务器通过互联网获取图书封面的图像;
5、步骤2:预处理模块对图书封面的图像进行预处理,得到预处理后图像;
6、步骤3:roi模块对预处理后图像进行roi检测,得到图书基本信息数组,图书基本信息数组为二维数组,其内容包含书名信息和作者信息;
7、步骤4:区域识别模块遍历图书基本信息数组,检查每一个区域存在图书基本信息的概率p;
8、步骤5:选取任意一个区域a,对区域a的概率p作出判断:如果概率p值到达预设阈值,则,标记区域a为待处理区域,待处理区域为包含了署名信息和作者信息的区域;反之,不对区域a做任何处理;
9、重复执行步骤5直到对所有区域均判断完毕,执行步骤6;
10、步骤6:特征提取模块将待处理区域从预处理后图像中截取出来,并提取特征向量,特征向量表示为一个特征向量数组,特征向量数组包含根据图像像素值的变化,提取的预处理后图像中特定区域的hog特征;
11、将待处理区域的位置信息和特征向量分别表示为一组位置数组和一组特征向量数组;
12、步骤7:特征构造模块计算待处理区域的特征的变化,构造波动特征,具体包括如下步骤;
13、步骤7-1:在任意一个待处理区域b中,计算每个区域特征向量元素两两之间的距离,得到距离矩阵;
14、步骤7-2:将距离矩阵通过以下公式转换为一个向量,使用该向量作为待处理区域b的波动特征:
15、
16、其中,d(xi,xj)表示距离矩阵中的元素,具体表示为第i和第j个特征值之间的距离,i取值为1到n,j取值为1到n;
17、步骤8:特征识别模块提取波动特征,并进行识别,采用欧式距离算法进行相似度计算,从特征库中寻找出相似度最高的书名信息和作者信息,作为最终的结果进行输出。
18、优选的,在执行步骤2时,对图书封面的图像进行的预处理包括统一大小处理、降噪处理、灰度化处理和二值化处理。
19、优选的,在执行步骤3时,图书基本信息数组具体表示为[x0,y0,x1,y1,p],其中,其中x0,y0分别表示区域左上角x和y坐标,x1和y1分别表示区域右下角x和y坐标,p表示这个区域存在图书基本信息的概率。
20、优选的,在执行步骤6时,特征向量数组具体表示为[f1,f2,f3,f4,f5,f6,……,fn],其中,fi为特征向量数组中的一个特征值,i取值为1到n,位置数组具体表示为[x0,y0,x1,y1],其中,x0,y0,x1,y1均表示待处理区域的位置坐标。
21、优选的,在执行步骤7-1时,具体为:设定待处理区域b的特征向量为[x1,x2,x3,x4,x5,x6,……,xn],共有n个维度,根据以下公式计算每个区域特征向量元素两两之间的距离:
22、
23、
24、其中,d(xi,xj)表示距离矩阵中的元素,具体表示为第i和第j个特征值之间的距离,i取值为1到n,j取值为1到n,d表示使用欧式距离的度量方式。
25、优选的,在执行步骤8时,采用欧式距离方式进行相似度计算的具体公式如下:
26、
27、其中,di为相似度值,表示待处理区域的特征向量和特征库中第i个特征向量的相似度,fnn表示待处理区域的波动特征值(原始特征向量有n个特征值),nn表示有该区域nxn个波动特征值,fnn表示特征库中的某一个波动特征值,原始特征向量共有n个特征值,nn表示共有nxn个波动特征值。
28、本发明所述的一种基于像素值波动的图书信息提取方法,解决了在图书信息提取时,得到稳定的特征的技术问题,本发明可得到更可靠的波动特征,可以清除掉异常的特征数据,即使在图书封面图像噪音较多、部分被遮挡、图像扭曲、图像较小等情况下,亦可提取出书名和作者等基本信息。
技术特征:
1.一种基于像素值波动的图书信息提取方法,其特征在于:包括如下步骤:
2.如权利要求1所述的一种基于像素值波动的图书信息提取方法,其特征在于:在执行步骤2时,对图书封面的图像进行的预处理包括统一大小处理、降噪处理、灰度化处理和二值化处理。
3.如权利要求1所述的一种基于像素值波动的图书信息提取方法,其特征在于:在执行步骤3时,图书基本信息数组具体表示为[x0,y0,x1,y1,p],其中,其中x0,y0分别表示区域左上角x和y坐标,x1和y1分别表示区域右下角x和y坐标,p表示这个区域存在图书基本信息的概率。
4.如权利要求1所述的一种基于像素值波动的图书信息提取方法,其特征在于:在执行步骤6时,特征向量数组具体表示为[f1,f2,f3,f4,f5,f6,……,fn],其中,fi为特征向量数组中的一个特征值,i取值为1到n,位置数组具体表示为[x0,y0,x1,y1],其中,x0,y0,x1,y1均表示待处理区域的位置坐标。
5.如权利要求1所述的一种基于像素值波动的图书信息提取方法,其特征在于:在执行步骤7-1时,具体为:设定待处理区域b的特征向量为[x1,x2,x3,x4,x5,x6,……,xn],共有n个维度,根据以下公式计算每个区域特征向量元素两两之间的距离:
6.如权利要求1所述的一种基于像素值波动的图书信息提取方法,其特征在于:在执行步骤8时,采用欧式距离方式进行相似度计算的具体公式如下:
技术总结
本发明公开了一种基于像素值波动的图书信息提取方法,属于图像处理技术领域,包括获取图书封面的图像,预处理,ROI检测得到图书基本信息数组,检查每一个区域存在图书基本信息的概率P,只保留可能存在目标的区域,提取书名和作者所在区域的原始特征,计算特征变化和狗仔波动特征,对目标区域内容进行识别,解决了在图书信息提取时,得到稳定的特征的技术问题,本发明可得到更可靠的波动特征,可以清除掉异常的特征数据,即使在图书封面图像噪音较多、部分被遮挡、图像扭曲、图像较小等情况下,亦可提取出书名和作者等基本信息。
技术研发人员:谢文伟,孙贤军
受保护的技术使用者:南京少昊网络科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!