一种基于ViT的无人机跨视角地理定位方法
本发明涉及计算机视觉图像检索与匹配领域,尤其涉及基于深度学习的无人机跨视角地理定位。
背景技术:
1、基于图像的跨视角地理定位涉及到对描述同一地理空间位置但从不同视角或平台拍摄的图像进行匹配。随着无人设备技术的发展和卫星成像技术的成熟,基于图像的跨视角地理定位变得越来越重要。例如,在gps信号被削弱或因干扰而丢失的情况下,无人设备需要一种替代的独立定位方法,如将周围环境的图像与带有地理标记的图像相匹配以确定其位置。基于图像的地理定位已被应用于当今多个领域,如自动驾驶、机器人定位、无人机导航和精确交付等。虽然基于图像的地理定位通常不作为设备的主要定位方法,但它可以在复杂的室内场景中协助并准确调整定位,实时监测相对位置的变化,并提高gps的准确性。与基于传感器的定位方法相比,基于图像的方法具有成本低、抗电磁干扰能力强和环境适应性好等优点。
2、深度学习发展迅速,深度神经网络在基于图像的跨视点地理定位方面已经取得了有竞争力的成果。研究人员通常使用一个双分支的网络架构来解决跨视角地理定位任务,分别处理来自不同视图或平台的输入图像。然后采用一个度量学习损失来最小化具有相同标签的图像之间的距离,最大化具有不同标签的图像之间的距离。识别来自不同视图或平台的图像之间的相似性是解决这个问题的关键。目前基于图像的跨视角地理定位的研究主要集中在地面和卫星之间的图像匹配,无人机视角的图像和卫星视角的图像之间的匹配却受到关注相对较少。
3、近年来,基于transformer的vit凭借其强大的全局建模能力和自我关注机制,在各种视觉任务中都表现出了优异的性能。在处理无人机跨视角地理定位问题中,具有以下三个优点: 1)vit明确编码了位置信息,使其能够更好地提取无人机视角和卫星视角图像之间的几何对应关系。2)每个补丁都有一个明确的可学习的位置嵌入,能够更好地实现跨视角图像之间的空间对齐,提高模型性能。3)多头注意力模块可以从第一层开始对所有斑块之间的全局远程关联进行建模,而cnn由于其有限的感受野,只能在顶层学习全局信息。vit为更好地应对无人机跨视角地理定位问题提供了新的可能。
技术实现思路
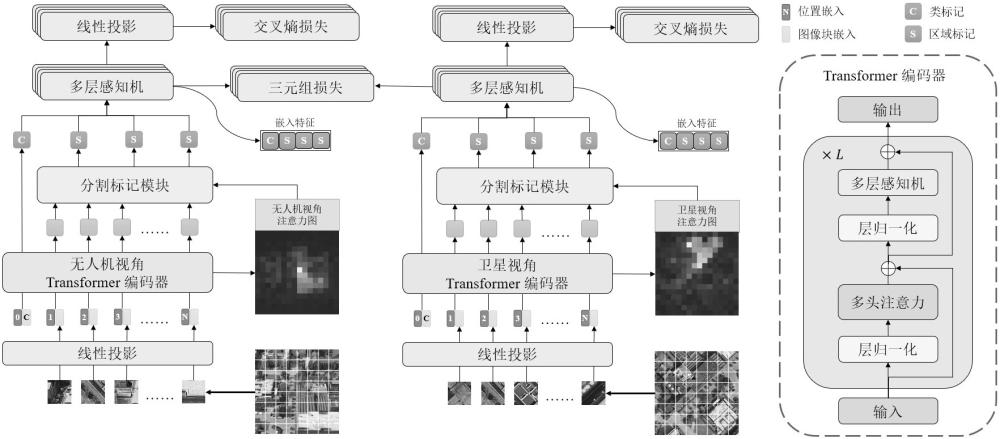
1、本发明针对无人机跨视角地理定位问题,提出了一种基于vit的无人机跨视角地理定位方法。以vit为骨干网络,引入了一种新的通过注意力机制引导的分割策略,并在此基础上设计了一个新的分割标记模块,最后利用训练学习得到的神经网络模型实现无人机视角图像与卫星视角图像的检索匹配,以实现无人机视觉定位。包含以下步骤:
2、(1)读取成对的表示同一地理位置的无人机视角图像和卫星视角图像,输入vit网络模型进行训练;
3、(2)在transformer编码器最后一层额外生成图像的全局注意力图,并应用注意力机制引导的分割策略分割区域、生成各区域中图像块的注意力权重;
4、(3)将注意力机制引导的分割策略的结果与图像块嵌入(由vit网络模型训练过程中产生)输入分割标记模块,生成区域标记;
5、(4)将类标记(由vit网络模型训练过程中产生)与区域标记输入各自不共享参数的分类模块进行训练;
6、(5)将类标记与区域标记进行拼接作为图像特征向量,用于无人机视角图像与卫星视角图像的检索匹配,图像之间的相似程度通过计算特征向量的余弦相似度进行衡量。
7、进一步,通过注意力机制引导的分割策略,主要包含以下步骤:
8、(1)生成全局注意力图,其中q、k表示vit模型中的查询矩阵和键矩阵,d表示transformer编码器中的图像块嵌入特征维度数,h表示多头注意力机制中头的个数:
9、
10、
11、提取矩阵a的第一行并重塑至图像块网格大小,作为全局注意力图,每个图像块对应一个注意力值;
12、(2)根据图像块的注意力值进行降序排序,并划分成n个区域,每个区域的图像块个数占比计算公式为:
13、softmax({[1,\, 2,\, ...,\, n]}^{t})
14、{[1,\, 2,\, ...,\, n]}^{t}表示一个从1递增到n的向量,计算后元素对应的结果即表示对应区域的图像块个数占比,其中注意力值越高的区域内,图像块的个数占比越少;
15、(3)以一个区域为整体,对每个区域内图像块的注意力值进行softmax运算,生成各区域中图像块的注意力权重。
16、进一步,新的分割标记模块,通过以下方式计算区域标记:
17、
18、其中表示第i组的区域标记,表示第i组图像块的个数,表示第i组中第j个图像块的权重,最后生成的特征向量表示为{[{x}_{cls},\, {x}_{{seg}_{1}},\, ...,\, {x}_{{seg}_{n}}]}^{t}。
技术特征:
1.一种基于vit的无人机跨视角地理定位方法,其特征在于,以vit为骨干网络,引入了一种新的通过注意力机制引导的分割策略,并在此基础上设计了一个新的分割标记模块,最后利用训练学习得到的神经网络模型实现无人机视角图像与卫星视角图像的检索匹配,以实现无人机视觉定位。
2.根据权利要求1所述的一种基于vit的无人机跨视角地理定位方法,其特征包括以下步骤:
3.根据权利要求1所述的一种新的通过注意力机制引导的分割策略,其特征包括以下步骤:
4.根据权利要求1所述的一个新的分割标记模块,其特征在于,通过以下方式计算区域标记:
技术总结
本发明提出了一种基于ViT的无人机跨视角地理定位方法,以ViT为骨干网络,引入了一种新颖的通过注意力机制引导的分割策略,来应对空中视角的巨大变化,通过注意力机制的引导,这种分割是自适应、非均匀的,即使在视角发生巨大变化后,也能分割出具有相应关系的区域;此外,还设计了一个新的分割标记模块来帮助神经网络更好地建模本地信息,该模块生成的区域标记与原本的类标记进行拼接作为图像特征向量,不仅考虑了全局信息还丰富了本地信息。利用训练学习得到的神经网络模型可以更好地进行无人机视角图像与卫星视角图像的检索匹配,以实现无人机视觉定位。
技术研发人员:刘怡光,赵子川,唐天航,陈杰,汤自新,史雪蕾
受保护的技术使用者:四川大学
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!