一种基于YOLOv5的复杂场景人脸检测方法
本发明涉及给图像处理领域,尤其涉及一种基于yolov5的复杂场景人脸检测方法。
背景技术:
1、随着计算机视觉技术的高速发展,人脸检测已经广泛应用到安防监控,人证比对,人机交互,社交和娱乐等领域,监控系统在各大城市逐步完备。在实际监控系统中,监控系统采集到各种自然场景下的情况较为复杂,经常会出现遮挡、光照、噪声、扭曲、年龄、旋转等因素影响人脸检测效果。目前的人脸检测算法在实时监控中应用效果仍然有待改善,在复杂场景下进行人脸检测仍然是一个具有挑战性的课题。因此不断改进目标检测算法,提高复杂场景下人脸检测的准确率和检测速率有着重要意义。
2、但本申请发明人在实现本申请实施例中发明技术方案的过程中,发现上述技术至少存在如下技术问题:目前人脸检测算法主要分为双阶段检测(two-stage)和单阶段检测(one-stage)两个分支。其中,two-stage方法有faster r-cnn、r-fcn等系列通用网络框架用于人脸检测,主要采用由粗到精的检测方式,人脸检测技术得到其检测准确率较高但检测速度比较慢。one-stage方法有yolo、ssd等方法,主要采用多层直接预测的方式,在训练阶段分别计算置信度和坐标值误差,然后传递给损失层,这种单阶段的检测算法相比于两阶段算法的处理速度得到很大的提升。但这两类方法在复杂场景下的检测精度和处理速度等方面仍然表现不佳,模型尺寸也较大。
技术实现思路
1、本申请实施例通过提供一种基于yolov5的复杂场景人脸检测方法,解决了现有技术中在复杂场景下中对于多人脸、小人脸检测准确率低且检测速度慢的问题,实现了复杂场景下人脸检测的精准、快速识别。
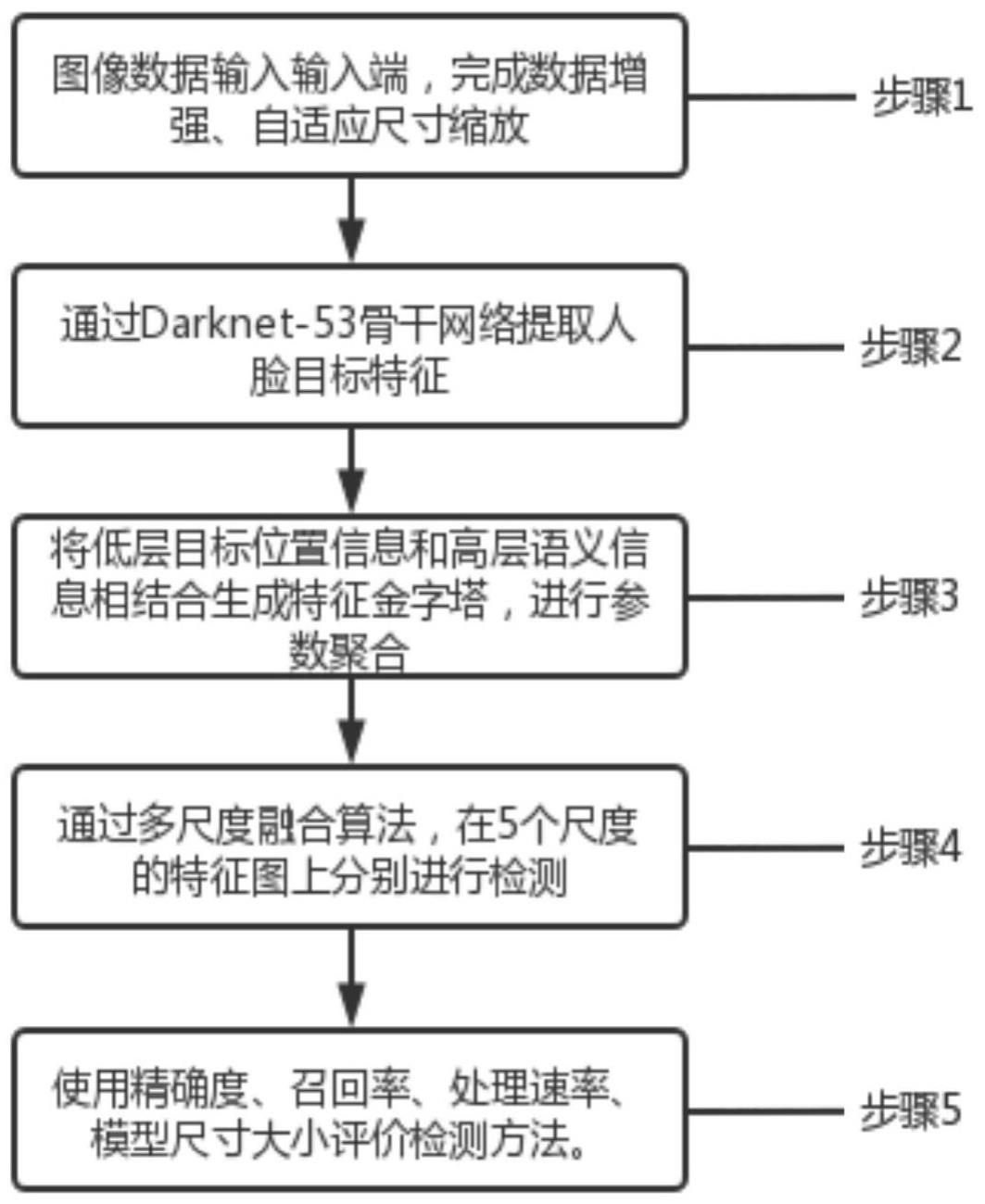
2、本申请实施例提供了一种基于yolov5的复杂场景人脸检测方法,包括以下步骤:
3、步骤1,图像数据输入输入端,完成数据增强、自适应尺寸缩放。
4、步骤2,通过darknet-53骨干网络提取人脸目标特征。
5、步骤3,yolov5多尺度预测网络的颈部网络主干为特征融合网络,采用panet算法,将低层目标位置信息和高层语义信息相结合生成特征金字塔,特征金字塔通过上采样传递底层定位特征,进行参数聚合。
6、步骤4,通过多尺度融合算法,在5个尺度的特征图上分别进行检测。
7、步骤5,在人脸检测数据集wider face进行验证,使用精确度、召回率、处理速率、模型尺寸大小评价检测方法。
8、优选的,输入端采用mosaic方式进行数据增强,对输入的图像数据进行随机剪裁和随机拼接。
9、优选的,自适应尺寸缩放,具体包括:计算图片的缩放比例;获取较小的缩放系数;计算黑边填充高度。
10、优选的,darknet-53骨干网络,具体包括:darknet-19以及其它残差网络,所述darknet-53骨干网络有53个卷积层,由3×3和1×1大小的卷积核组合而成,使用一个全连接层和softmax完成最后的分类。
11、优选的,panet包括:fpn网络结构、自下而上的联合扩充部分、自适应特征池化部分。
12、优选的,多尺度融合算法,融合5个尺度:8×8×255、16×16×255、32×32×255、64×64×255和128×128×255。
13、本申请实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
14、1、由于采用了yolov5算法,所以,过邻域的正样本匹配策略增加正样本,还能使用不同复杂度的检测模型提升精准率,yolov5还有具有自适应锚框计算功能,即在默认设定的锚框上输出一个预测框,并计算标注好的真实框与预测框之间的差值,再反向迭代网络中的参数实现反向更新,最后自动获取最佳锚框值。
15、2、由于输入端采用mosaic方式即对输入的图像数据进行随机剪裁和随机拼接,不仅可以大幅度提高数据集的数据量,也可以减少gpu内存的使用。
16、3、由于采用了轻量级的darknet-53网络,提高了精确率和推理速度,且降低了模型尺寸。
17、4、采用了panet算法,特征金字塔通过上采样传递底层定位特征,进行参数聚合;同时,缩短信息传输路径,既减少计算量,也增强对小目标的检测效果,实现多尺度的输出。
18、5、在多尺度分别进行检测,能够明显提升网络的性能,增强小目标的检出率。
技术特征:
1.一种基于yolov5的复杂场景人脸检测方法,包括以下步骤:
2.如权利要求1所述的基于yolov5的复杂场景人脸检测方法,其特征在于,所述输入端采用mosaic方式进行数据增强,对输入的图像数据进行随机剪裁和随机拼接。
3.如权利要求1所述的基于yolov5的复杂场景人脸检测方法,其特征在于,在所述自适应尺寸缩放,具体包括:计算图片的缩放比例;获取较小的缩放系数;计算黑边填充高度。
4.如权利要求1所述的基于yolov5的复杂场景人脸检测方法,其特征在于,所述darknet-53骨干网络,具体包括:darknet-19以及其它残差网络,所述darknet-53骨干网络有53个卷积层,由3×3和1×1大小的卷积核组合而成,使用一个全连接层和softmax完成最后的分类。
5.如权利要求1所述的基于yolov5的复杂场景人脸检测方法,其特征在于,所述panet包括:fpn网络结构、自下而上的联合扩充部分、自适应特征池化部分。
6.如权利要求1所述的基于yolov5的复杂场景人脸检测方法,其特征在于,所述多尺度融合算法,融合5个尺度:8×8×255、16×16×255、32×32×255、64×64×255和128×128×255。
技术总结
本发明公开了一种基于YOLOv5的复杂场景人脸检测方法,包括以下步骤:步骤1,图像数据输入输入端,完成数据增强、自适应尺寸缩放;步骤2,通过Darknet‑53骨干网络提取人脸目标特征;步骤3,YOLOv5多尺度预测网络的颈部网络主干为特征融合网络,采用PANet算法,将低层目标位置信息和高层语义信息相结合生成特征金字塔,特征金字塔通过上采样传递底层定位特征,进行参数聚合;步骤4,通过多尺度融合算法,在5个尺度的特征图上分别进行检测;步骤5,使用精确度、召回率、处理速率、模型尺寸大小评价检测方法;实现了复杂场景下人脸检测的精准、快速识别。
技术研发人员:云海姣,李明晶,董玉冰,刘妍君,夏洋,栾金阳,杨佚存,闫登豪
受保护的技术使用者:长春大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!