算子热更新方法及装置与流程
本发明涉及大数据,尤其涉及算子热更新方法及装置。
背景技术:
1、本部分旨在为权利要求书中陈述的本发明实施例提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
2、在数据挖掘过程中,需要对海量数据进行清洗、分析、加工,且每个过程对资源的要求也不同,为了实现资源动态扩缩容,满足不同数据量的使用场景,业内的趋势是结合容器编排引擎spark on kubernetes来实现。
3、基于spark on kubernetes进行数据挖掘要求用户具备技术基础,门槛高。因此业内比较常见的做法是基于spark提供封装好的算子,用户基于多种算子就能快速地探索出一套数据加工的方案。当需要支持新的计算逻辑时,就会针对性的开发出一个独立的算子来支撑该逻辑。因此更新算子是一个相对频繁的操作,现有的技术方案下新增一个定制化算子,一般需要经过如下步骤:
4、1、开发算子。
5、2、添加算子所需的依赖包。
6、3、更新应用镜像。
7、4、增加算子及依赖包所需的参数。
8、5、重新打包镜像。
9、6、结束正在进行的计算任务并停止生产环境的spark集群。
10、7、更新镜像。
11、8.重新启动spark集群。
12、因此每次增加一种新算子,都需要停服升级,在更新期间服务处于不可用状态,这给使用上带来诸多不便,效率低下。
技术实现思路
1、本发明实施例提供一种算子热更新方法,用以实现算子热更新,该方法包括:
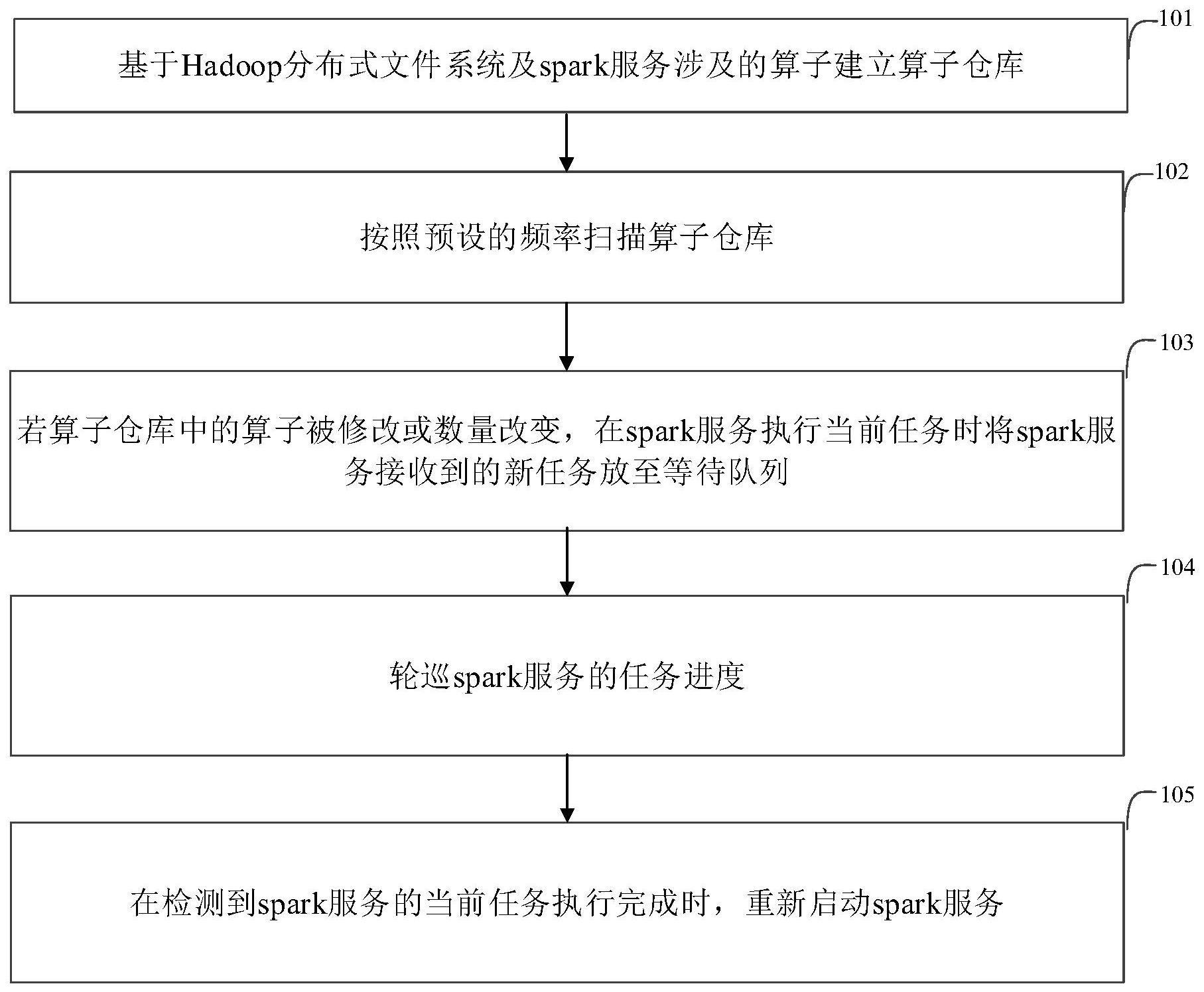
2、基于hadoop分布式文件系统及spark服务涉及的算子建立算子仓库;
3、按照预设的频率扫描算子仓库;
4、若算子仓库中的算子被修改或数量改变,在spark服务执行当前任务时将spark服务接收到的新任务放至等待队列;
5、轮巡spark服务的任务进度;
6、在检测到spark服务的当前任务执行完成时,重新启动spark服务。
7、本发明实施例还提供一种算子热更新装置,用以实现算子热更新,该装置包括:
8、扫描模块,用于基于hadoop分布式文件系统及spark服务涉及的算子建立算子仓库;按照预设的频率扫描算子仓库;
9、热更新模块,用于若算子仓库中的算子被修改或数量改变,在spark服务执行当前任务时将spark服务接收到的新任务放至等待队列;轮巡spark服务的任务进度;在检测到spark服务的当前任务执行完成时,重新启动spark服务。
10、本发明实施例还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述算子热更新方法。
11、本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述算子热更新方法。
12、本发明实施例还提供一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序被处理器执行时实现上述算子热更新方法。
13、本发明实施例中,基于hadoop分布式文件系统及spark服务涉及的算子建立算子仓库;按照预设的频率扫描算子仓库;若算子仓库中的算子被修改或数量改变,在spark服务执行当前任务时将spark服务接收到的新任务放至等待队列;轮巡spark服务的任务进度;在检测到spark服务的当前任务执行完成时,重新启动spark服务,与现有技术相比,通过动态扫描的方式检测到算子变更,不需要将算子插件对应的依赖包重新打包到spark集群的镜像中,解耦了算子更新与镜像更新。检测当前正在执行的任务,不需要中断执行中的任务,当任务执行完成后重启spark服务,实现了算子热更新,整个升级过程对用户无感知,提升了用户体验。
技术特征:
1.一种算子热更新方法,其特征在于,包括:
2.如权利要求1所述的算子热更新方法,其特征在于,在所述按照预设的频率扫描算子仓库之后,还包括:
3.如权利要求1所述的算子热更新方法,其特征在于,所述基于hadoop分布式文件系统及spark服务涉及的算子建立算子仓库,包括:
4.如权利要求1所述的算子热更新方法,其特征在于,所述将spark服务接收到的新任务放至等待队列,包括:
5.如权利要求1所述的算子热更新方法,其特征在于,在所述重新启动spark服务之后,还包括:
6.一种算子热更新装置,其特征在于,包括:
7.如权利要求6所述的算子热更新装置,其特征在于,所述热更新模块还用于:
8.如权利要求6所述的算子热更新装置,其特征在于,所述扫描模块具体用于:
9.如权利要求6所述的算子热更新装置,其特征在于,所述热更新模块具体用于:
10.如权利要求6所述的算子热更新装置,其特征在于,所述热更新模块还用于:
11.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至5任一所述方法。
12.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现权利要求1至5任一所述方法。
13.一种计算机程序产品,其特征在于,所述计算机程序产品包括计算机程序,所述计算机程序被处理器执行时实现权利要求1至5任一所述方法。
技术总结
本发明公开了算子热更新方法及装置,方法包括:基于Hadoop分布式文件系统及spark服务涉及的算子建立算子仓库;按照预设的频率扫描算子仓库;若算子仓库中的算子被修改或数量改变,在spark服务执行当前任务时将spark服务接收到的新任务放至等待队列;轮巡spark服务的任务进度;在检测到spark服务的当前任务执行完成时,重新启动spark服务。本发明通过动态扫描的方式检测到算子变更,不需要将算子插件对应的依赖包重新打包到spark集群的镜像中,解耦了算子更新与镜像更新。检测当前正在执行的任务,不需要中断执行中的任务,当任务执行完成后重启spark服务,实现了算子热更新,提升了用户体验。
技术研发人员:林培峰,方景星
受保护的技术使用者:中国建设银行股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!