语义表征模型的训练方法、装置、存储介质及计算机设备与流程
本发明涉及数字医疗,尤其是涉及一种语义表征模型的训练方法、装置、存储介质及计算机设备。
背景技术:
1、随着医疗技术的日趋成熟,医疗技术领域内文本数量也随之快速增长,在大范围地文本搜索场景下,基于内容理解的搜索至关重要。能否快速地在海量的文本内搜索出所要得到的文本文档,对医疗工作的快速推进有着重要的作用,能否快速的在海量的医疗技术领域的文档中快速准确的找出所要获取的医学文档,对疾病辅助诊断以及健康管理方面有着重要的意义。
2、当前,业界主流的做法是建立语义模型,其中,直接使用bert的cls的特征信息作为输入的向量表示、使用文本所有词的特征信息的平均值作为向量表示、使用文本所有词的特征表示的最大值作为输入文本的向量对模型进行训练。
3、但是,以该种模型训练方式训练的语义模型,在医疗文本搜索的数据非常稀缺的情况下,无法构造高质量的数据,导致语义模型的准确率大幅降低。
技术实现思路
1、有鉴于此,本申请提供了一种语义表征模型的训练方法、装置、存储介质及计算机设备,主要目的在于解决传统方法训练出的语义模型的准确率过低的技术问题。
2、根据本发明的第一个方面,提供了一种语义表征模型的训练法,该方法包括:
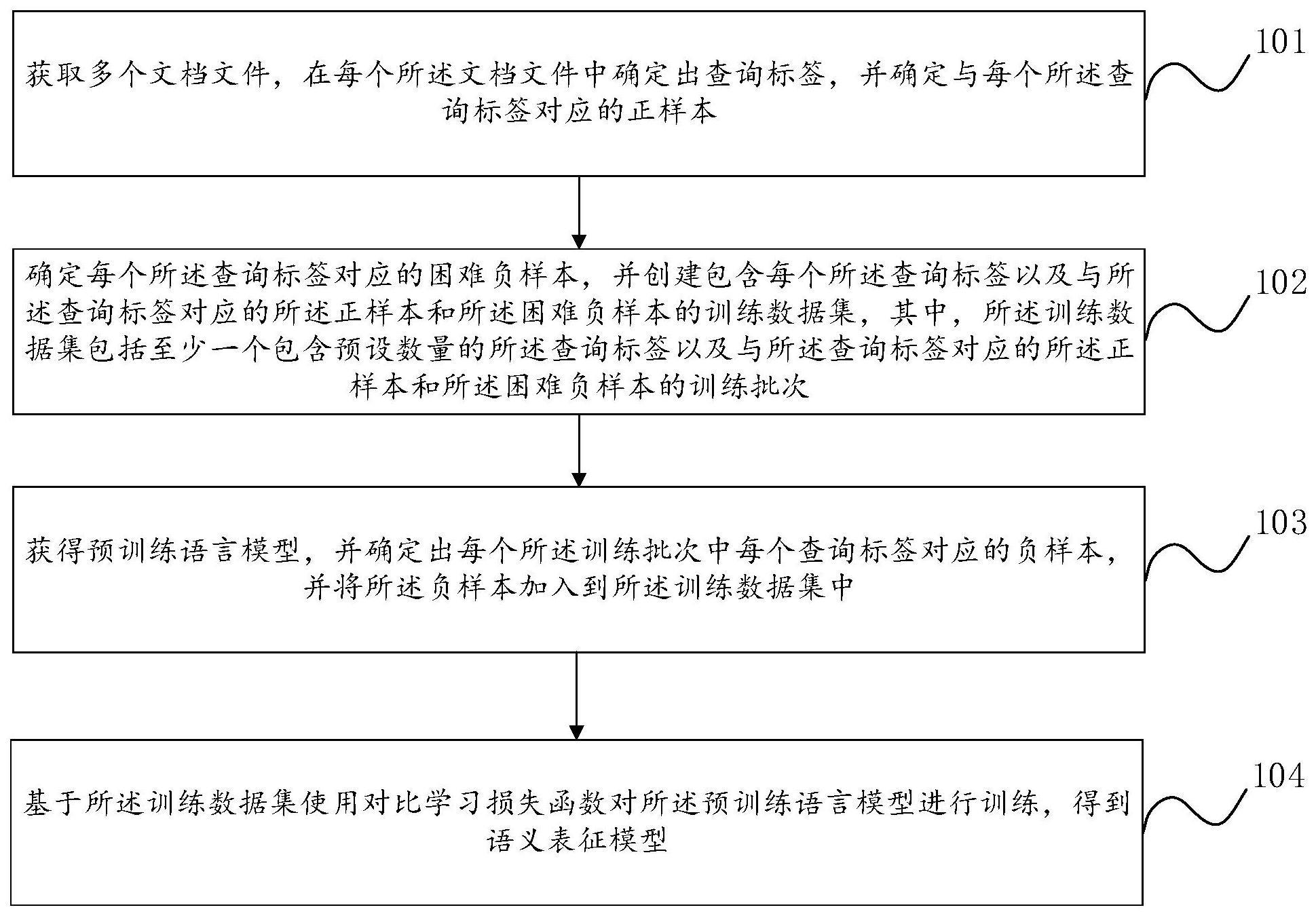
3、获取多个文档文件,在每个所述文档文件中确定出查询标签,并确定与每个所述查询标签对应的正样本;
4、确定每个所述查询标签对应的困难负样本,并创建包含每个所述查询标签以及与所述查询标签对应的所述正样本和所述困难负样本的训练数据集,其中,所述训练数据集包括至少一个包含预设数量的所述查询标签以及与所述查询标签对应的所述正样本和所述困难负样本的训练批次;
5、获得预训练语言模型,并确定出每个所述训练批次中每个查询标签对应的负样本,并将所述负样本加入到所述训练数据集中;
6、基于所述训练数据集使用对比学习损失函数对所述预训练语言模型进行训练,得到语义表征模型。
7、根据本发明的第二个方面,提供了一种语义表征模型的训练装置,该装置包括:
8、样本确定模块,用于获取多个文档文件,在每个所述文档文件中确定出查询标签,并确定与每个所述查询标签对应的正样本;
9、数据集获取模块,用于确定每个所述查询标签对应的困难负样本,并创建包含每个所述查询标签以及与所述查询标签对应的所述正样本和所述困难负样本的训练数据集,其中,所述训练数据集包括至少一个包含预设数量的所述查询标签以及与所述查询标签对应的所述正样本和所述困难负样本的训练批次;
10、模型获取模块,用于获得预训练语言模型,并确定出每个所述训练批次中每个查询标签对应的负样本,并将所述负样本加入到所述训练数据集中;
11、模型训练模块,用于基于所述训练数据集使用对比学习损失函数对所述预训练语言模型进行训练,得到语义表征模型。
12、根据本发明的第三个方面,提供了一种存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述语义表征模型的训练方法。
13、根据本发明的第四个方面,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述语义表征模型的训练方法。
14、本发明提供的一种语义表征模型的训练方法、装置、存储介质及计算机设备,能够构造出高质量的查询标签(query)、正样本(document)和困难负样本(hard negative)数据集,并使用对比学习损失函数基于包括query、document、hard negative和得到的负样本(negative)对预训练模型进行训练。本申请通过构建query和document搜索数据的方法,操作简单,运算量小,训练质量较高,正样本语义相关性高的方式训练语义模型,能大幅提高训练出的高语义表征模型的准确性。
15、上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其它目的、特征和优点能够更明显易懂,以下特举本申请的具体实施方式。
技术特征:
1.一种语义表征模型的训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述在每个所述文档文件中确定出查询标签,并确定与每个所述查询标签对应的正样本,包括:
3.根据权利要求2所述的方法,其特征在于,所述确定与每个所述查询标签对应的正样本,还包括:
4.根据权利要求1所述的方法,其特征在于,所述确定每个所述查询标签对应的困难负样本,包括:
5.根据权利要求1-4任一项所述的方法,其特征在于,所述确定出每个所述训练批次中每个查询标签对应的负样本,包括
6.根据权利要求1-4任一项所述的方法,其特征在于,所述预训练语言模型的获取方法包括:
7.根据权利要求1所述的方法,其特征在于,所述基于所述训练数据集使用对比学习损失函数对所述预训练语言模型进行训练,得到语义表征模型,包括:
8.一种语义表征模型的训练装置,其特征在于,所述装置包括:
9.一种存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7中任一项所述的方法的步骤。
10.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7中任一项所述的方法的步骤。
技术总结
本发明公开了一种语义表征模型的训练方法、装置、存储介质及计算机设备,涉及数字医疗技术领域。其中方法包括:获取多个文档文件,在每个文档文件中确定查询标签,确定与每个查询标签对应的正样本;确定每个查询标签对应的困难负样本,创建包含每个查询标签以及与查询标签对应的正样本和困难负样本的训练数据集,其中,训练数据集包括包含预设数量的查询标签以及与查询标签对应的正样本和困难负样本的训练批次;获得预训练语言模型,确定出每个训练批次中每个查询标签对应的负样本;基于包含每个查询标签对应的负样本的训练数据集使用对比学习损失函数对预训练语言模型进行训练得到语义表征模型。上述方法能提高训练出的语义表征模型的准确性。
技术研发人员:凌慧峰
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!