代码夹带识别方法、装置、电子设备及介质与流程
本公开涉及计算机,可用于金融领域或其他领域,具体涉及一种代码夹带识别方法、装置、电子设备、介质和程序产品。
背景技术:
1、代码夹带是指通常在计算机正常的程序传播中,额外夹带着的一段代码。代码夹带容易对计算机的网络安全造成破坏。
2、目前,检测代码夹带的方法包括获取业务需求数据,根据历史需求数据和新版本需求数据对这些数据进行分词处理,得到多个关键词;根据关键词分别构建历史需求数据和新版本需求数据对应的关键词向量,计算历史需求数据和新版本需求数据之间的相似分数;确定新版本需求数据的需求类型,以及确定新版本需求数据中与需求类型关联的代码夹带风险等级。
3、但是,在实现本公开构思的过程中,申请人发现:(1)目前的方法存在多分支的特点,给每块待处理特性(新功能、优化等)单独分支,当分支完成开发,再合并到主干,需要消耗大量的时间和人力;(2)目前的方法存在特性开关,仍然在主干或者单分支上进行开发,利用特性开关来调试和发布,当需要发布但某特性还没有完成时,将开关关闭,完成后打开,导致兼容性差,操作复杂。
技术实现思路
1、鉴于上述问题,本公开提供了一种代码夹带识别方法、装置、电子设备、介质和程序产品。
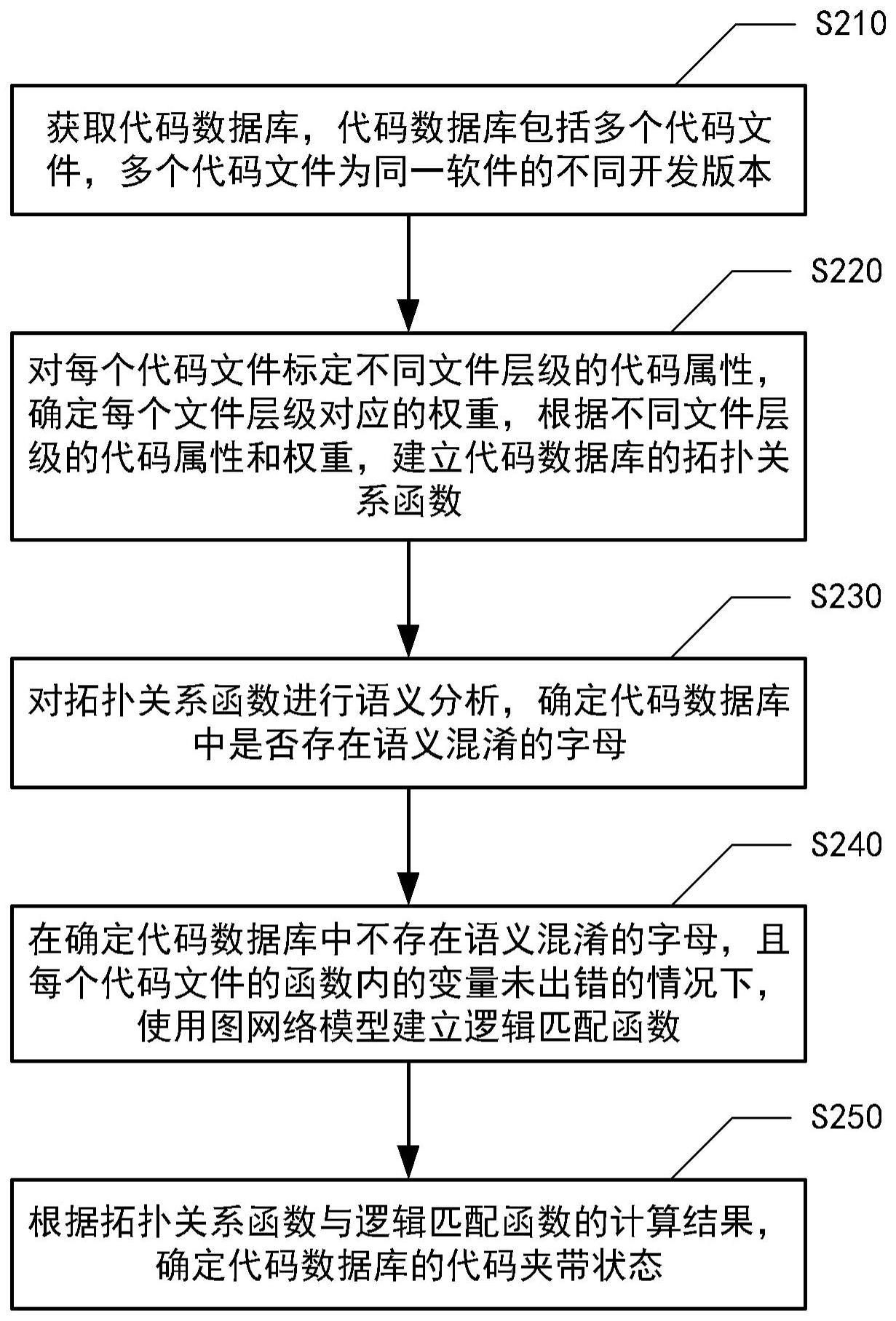
2、根据本公开的第一个方面,提供了一种代码夹带识别方法,包括:获取代码数据库,代码数据库包括多个代码文件,多个代码文件为同一软件的不同开发版本;对每个代码文件标定不同文件层级的代码属性,确定每个文件层级对应的权重,根据不同文件层级的代码属性和权重,建立代码数据库的拓扑关系函数;对拓扑关系函数进行语义分析,确定代码数据库中是否存在语义混淆的字母;在确定代码数据库中不存在语义混淆的字母,且每个代码文件的函数内的变量未出错的情况下,使用图网络模型建立逻辑匹配函数;根据拓扑关系函数与逻辑匹配函数的计算结果,确定代码数据库的代码夹带状态。
3、根据本公开的实施例,对每个代码文件标定不同文件层级的代码属性包括:为每个代码文件标记多个代码属性,代码属性包括文件名称、文件数量、每份文件的代码行号数、函数个数和引用关系;根据不同开发版本的业务逻辑关系,对每个代码属性所属的文件层级进行标定,文件层级依次包括文件夹、文件、项目程序、函数定义和函数引用关系。
4、根据本公开的实施例,确定每个文件层级对应的权重包括:根据函数引用关系,统计每个文件层级的代码属性在代码数据中的引用数量;根据引用数量,确定该文件层级对应的权重,其中,引用数量越多,则该文件层级对应的权重越大。
5、根据本公开的实施例,对每个代码属性所属的文件层级进行标定之前,还包括:根据业务逻辑关系,按照时间顺序更新代码数据库。
6、根据本公开的实施例,按照以下方式确定代码数据库中存在语义混淆的字母:从拓扑关系函数中提取函数类别和函数名称,作为多个关键词;对多个关键词中任意两个关键词进行语义分析,得到两个关键词的语义相似度;在语义相似度高于相似度阈值的情况下,确定代码数据库中存在语义混淆的字母。
7、根据本公开的实施例,图网络模型包括有向无环图模型,有向无环图模型包括多个节点和节点之间带有单向箭头的路径;逻辑匹配函数包括概率密度函数;使用图网络模型建立逻辑匹配函数包括:基于每个代码文件中的函数定义和函数引用关系,构建有向无环图模型;针对有向无环图模型,对每个路径涉及的两个节点进行语义分析,在确定两个节点的语义不通的情况下,根据两个节点的位置信息,联合先验概率计算后验概率;基于后验概率,推导出概率密度函数。
8、根据本公开的实施例,构建有向无环图模型包括:以每个函数定义来表示一个节点,分别以每个文件层级对应的权重来表示节点之间的路径;使用贝叶斯网络算法,确定多个节点中每个节点的先验概率。
9、根据本公开的实施例,该方法还包括:根据代码属性,建立代码数据库的索引机制;在确定一代码文件的函数内的变量出错的情况下,根据索引机制,确定问题代码的位置,并对问题代码进行更改。
10、根据本公开的实施例,代码夹带状态包括存在代码夹带;按照以下方式确定代码数据库存在代码夹带:在确定拓扑关系函数与逻辑匹配函数的计算结果不相同的情况下,确定代码数据库存在代码夹带,并根据索引机制,确定夹带的代码文件和对应的行号区域。
11、根据本公开的实施例,确定夹带的代码文件和对应的行号区域之后,还包括:对行号区域内的代码进行更改,更改后更新代码数据库;对更新后的代码数据库重复执行对每个代码文件标定不同文件层级的代码属性,至确定代码数据库的状态代码夹带的操作,直至拓扑关系函数与逻辑匹配函数的计算结果相同。
12、本公开的第二方面提供了一种代码夹带识别装置,包括:代码数据库获取模块,用于获取代码数据库,代码数据库包括多个代码文件,多个代码文件为同一软件的不同开发版本;拓扑关系函数建立模块,用于对每个代码文件标定不同文件层级的代码属性,确定每个文件层级对应的权重,根据不同文件层级的代码属性和权重,建立代码数据库的拓扑关系函数;语义分析模块,用于对拓扑关系函数进行语义分析,确定代码数据库中是否存在语义混淆的字母;逻辑匹配函数建立模块,用于在确定代码数据库中不存在语义混淆的字母,且每个代码文件的函数内的变量未出错的情况下,使用图网络模型建立逻辑匹配函数;代码夹带确定模块,用于根据拓扑关系函数与逻辑匹配函数的计算结果,确定代码数据库的代码夹带状态。
13、本公开的第三方面提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得一个或多个处理器执行上述代码夹带识别方法。
14、本公开的第四方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述代码夹带识别方法。
15、本公开的第五方面还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述代码夹带识别方法。
16、通过本公开实施例的代码夹带识别方法、装置、电子设备、介质和程序产品,对某一软件产品的各个开发版本的代码文件进行汇总,通过逐级标定和权重赋值,建立拓补关系函数;经过语义分析后,基于拓扑关系函数与逻辑匹配函数,对代码夹带进行有效识别。本公开提供的方法,作为一种计算机业务逻辑的自主迭代过程,可以有效提升软件产品的安全性,降低代码夹带识别的复杂度。
技术特征:
1.一种代码夹带识别方法,包括:
2.根据权利要求1所述的方法,其中,所述对每个代码文件标定不同文件层级的代码属性包括:
3.根据权利要求2所述的方法,其中,所述确定每个文件层级对应的权重包括:
4.根据权利要求2所述的方法,其中,所述对每个代码属性所属的文件层级进行标定之前,还包括:
5.根据权利要求1所述的方法,其中,按照以下方式确定所述代码数据库中存在语义混淆的字母:
6.根据权利要求2所述的方法,其中,所述图网络模型包括有向无环图模型,所述有向无环图模型包括多个节点和节点之间带有单向箭头的路径;所述逻辑匹配函数包括概率密度函数;
7.根据权利要求6所述的方法,其中,所述构建所述有向无环图模型包括:
8.根据权利要求1所述的方法,其中,所述方法还包括:
9.根据权利要求8所述的方法,其中,所述代码夹带状态包括存在代码夹带;按照以下方式确定所述代码数据库存在代码夹带:
10.根据权利要求9所述的方法,其中,所述确定夹带的代码文件和对应的行号区域之后,还包括:
11.一种代码夹带识别装置,包括:
12.一种电子设备,包括:
13.一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行根据权利要求1~10中任一项所述的方法。
14.一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现根据权利要求1~10中任一项所述的方法。
技术总结
本公开提供了一种代码夹带识别方法、装置、电子设备及介质,可用于金融领域或其他领域。该方法包括:获取代码数据库,代码数据库包括多个代码文件,多个代码文件为同一软件的不同开发版本;对每个代码文件标定不同文件层级的代码属性,确定每个文件层级对应的权重,根据不同文件层级的代码属性和权重,建立代码数据库的拓扑关系函数;对拓扑关系函数进行语义分析,确定代码数据库中是否存在语义混淆的字母;在确定代码数据库中不存在语义混淆的字母,且每个代码文件的函数内的变量未出错的情况下,使用图网络模型建立逻辑匹配函数;根据拓扑关系函数与逻辑匹配函数的计算结果,确定代码数据库的代码夹带状态。
技术研发人员:杨飞雪,施阳,成汉平
受保护的技术使用者:中国工商银行股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!