一种基于联邦学习的集成学习分类器及分类方法与流程
本发明涉及联邦学习和集成学习,具体地说是一种基于联邦学习的集成学习分类器及分类方法。
背景技术:
1、随着深度学习的发展,集成学习已经成为一种广泛使用的技术,通过将多个模型进行集成,可以获得比单个模型更好的分类性能。在传统的集成学习方法中,通常是将多个模型在同一数据集上进行训练,然后使用加权投票等方式进行集成。然而,这种方法存在一定的局限性,例如需要在中心服务器上集中存储数据,难以保护隐私等问题。
技术实现思路
1、本发明的技术任务是针对以上不足之处,提供一种基于联邦学习的集成学习分类器及分类方法,可以保护数据的隐私性,同时模型具有较好的鲁棒性,并使训练过程更加高效。
2、本发明解决其技术问题所采用的技术方案是:
3、一种基于联邦学习的集成学习分类器,该分类器使用多个本地模型进行分类,所述多个本地模型在联邦学习框架下训练,并使用加权投票的方式进行集成,得到最终的分类结果;
4、在进行联邦学习训练时,采用动态选举的方式进行模型选择,在每轮训练过程中,中心服务器随机选择部分本地设备参与训练,从而增加了模型的多样性。
5、该分类器使用多个本地模型进行分类,这些模型是在联邦学习框架下训练的,并使用加权投票的方式进行集成。具有可以保护数据的隐私性、模型具有较好的鲁棒性、训练过程更加高效等特点。
6、优选的,所述使用加权投票的方式进行集成,每个本地模型将自己的分类结果提交给中心服务器,中心服务器使用加权投票的方式将这些结果进行集成,得到最终的分类结果。
7、进一步的,在测试阶段,对新的数据样本进行分类时,多个本地模型对该样本进行分类,最终分类结果由中心服务器进行加权投票得到。
8、优选的,所述多个本地模型,均是在各自的本地设备上训练,每个本地设备只能访问自己的本地数据集,从而保护了数据的隐私性;
9、中心服务器将集成后的分类结果反馈给每个本地设备,本地设备使用反馈结果更新本地模型。
10、优选的,该分类器的具体实现方式如下:
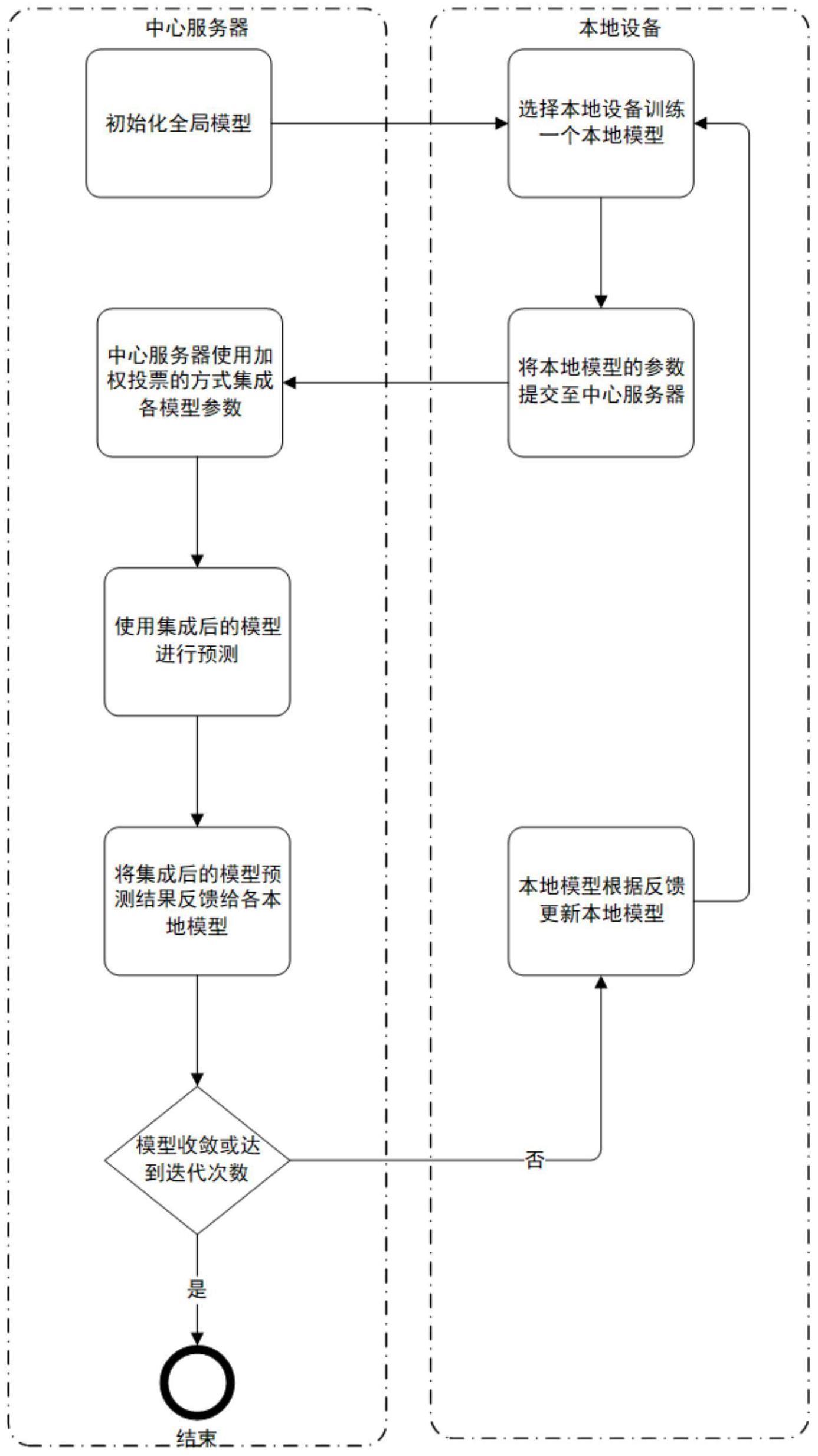
11、1)、在中心服务器上初始化一个全局模型,该模型将被用于集成本地模型的分类结果;
12、2)、每个设备的本地数据组成训练数据集,每个设备只能访问自己的本地数据集;
13、3)、在每轮训练过程中,中心服务器随机选择一部分本地设备参与训练,每个本地设备使用本地数据集训练一个本地模型;
14、4)、每个本地模型将自己的分类结果提交给中心服务器,中心服务器使用加权投票的方式将这些结果进行集成,得到最终的分类结果;
15、5)、中心服务器将集成后的分类结果反馈给每个本地设备,本地设备使用反馈结果更新本地模型;
16、6)、重复执行步骤3)至步骤5),直到全局模型收敛或达到预设的迭代次数;
17、7)、在测试阶段,对新的数据样本进行分类时,多个本地模型对该样本进行分类,最终分类结果由中心服务器进行加权投票得到。
18、优选的,加权投票的权重根据每个本地模型的准确率进行分配,准确率越高的模型权重越大。
19、本发明还要求保护一种基于联邦学习的集成学习分类方法,使用多个本地模型进行分类,所述多个本地模型在联邦学习框架下训练,并使用加权投票的方式进行集成,得到最终的分类结果;
20、所述多个本地模型,均是在各自的本地设备上训练,每个本地设备只能访问自己的本地数据集,从而保护了数据的隐私性;中心服务器将集成后的分类结果反馈给每个本地设备,本地设备使用反馈结果更新本地模型;
21、在进行联邦学习训练时,采用动态选举的方式进行模型选择,在每轮训练过程中,中心服务器随机选择部分本地设备参与训练。
22、优选的,所述使用加权投票的方式进行集成,每个本地模型将自己的分类结果提交给中心服务器,中心服务器使用加权投票的方式将这些结果进行集成,得到最终的分类结果。
23、进一步的,在测试阶段,对新的数据样本进行分类时,多个本地模型对该样本进行分类,最终分类结果由中心服务器进行加权投票得到。
24、优选的,该分类方法的实现方式如下:
25、1)、在中心服务器上初始化一个全局模型,该模型将被用于集成本地模型的分类结果;
26、2)、每个设备的本地数据组成训练数据集,每个设备只能访问自己的本地数据集;
27、3)、在每轮训练过程中,中心服务器随机选择一部分本地设备参与训练,每个本地设备使用本地数据集训练一个本地模型;
28、4)、每个本地模型将自己的分类结果提交给中心服务器,中心服务器使用加权投票的方式将这些结果进行集成,得到最终的分类结果;
29、5)、中心服务器将集成后的分类结果反馈给每个本地设备,本地设备使用反馈结果更新本地模型;
30、6)、重复执行步骤3)至步骤5),直到全局模型收敛或达到预设的迭代次数;
31、7)、在测试阶段,对新的数据样本进行分类时,多个本地模型对该样本进行分类,最终分类结果由中心服务器进行加权投票得到。
32、本发明的一种基于联邦学习的集成学习分类器及分类方法与现有技术相比,具有以下有益效果:
33、1、可以保护数据的隐私性。每个本地设备只能访问自己的本地数据集,不需要将数据集集中存储在中心服务器上,因此可以保护数据的隐私性。
34、2、模型具有较好的鲁棒性。通过使用多个本地模型进行集成,可以增加模型的多样性,从而提高模型的鲁棒性。
35、3、训练过程更加高效。由于本地设备进行训练,不需要将数据传输到中心服务器,因此可以减少通信开销,提高训练效率。
技术特征:
1.一种基于联邦学习的集成学习分类器,其特征在于,该分类器使用多个本地模型进行分类,所述多个本地模型在联邦学习框架下训练,并使用加权投票的方式进行集成,得到最终的分类结果;
2.根据权利要求1所述的一种基于联邦学习的集成学习分类器,其特征在于,所述使用加权投票的方式进行集成,每个本地模型将自己的分类结果提交给中心服务器,中心服务器使用加权投票的方式将这些结果进行集成,得到最终的分类结果。
3.根据权利要求1或2所述的一种基于联邦学习的集成学习分类器,其特征在于,在测试阶段,对新的数据样本进行分类时,多个本地模型对该样本进行分类,最终分类结果由中心服务器进行加权投票得到。
4.根据权利要求3所述的一种基于联邦学习的集成学习分类器,其特征在于,所述多个本地模型,均是在各自的本地设备上训练,每个本地设备只能访问自己的本地数据集;
5.根据权利要求4所述的一种基于联邦学习的集成学习分类器,其特征在于,该分类器的具体实现方式如下:
6.根据权利要求5所述的一种基于联邦学习的集成学习分类器,其特征在于,加权投票的权重根据每个本地模型的准确率进行分配,准确率越高的模型权重越大。
7.一种基于联邦学习的集成学习分类方法,其特征在于,使用多个本地模型进行分类,所述多个本地模型在联邦学习框架下训练,并使用加权投票的方式进行集成,得到最终的分类结果;
8.根据权利要求7所述的一种基于联邦学习的集成学习分类方法,其特征在于,所述使用加权投票的方式进行集成,每个本地模型将自己的分类结果提交给中心服务器,中心服务器使用加权投票的方式将这些结果进行集成,得到最终的分类结果。
9.根据权利要求7或8所述的一种基于联邦学习的集成学习分类方法,其特征在于,在测试阶段,对新的数据样本进行分类时,多个本地模型对该样本进行分类,最终分类结果由中心服务器进行加权投票得到。
10.根据权利要求7所述的一种基于联邦学习的集成学习分类方法,其特征在于,该分类方法的实现方式如下:
技术总结
本发明公开了一种基于联邦学习的集成学习分类器及分类方法,属于联邦学习和集成学习技术领域,该分类器使用多个本地模型进行分类,所述多个本地模型在联邦学习框架下训练,并使用加权投票的方式进行集成,得到最终的分类结果;在进行联邦学习训练时,采用动态选举的方式进行模型选择,在每轮训练过程中,中心服务器随机选择部分本地设备参与训练。本发明可以保护数据的隐私性,同时模型具有较好的鲁棒性,并使训练过程更加高效。
技术研发人员:李彬,贾荫鹏,李圣伟,孙善宝,罗清彩,李锐
受保护的技术使用者:山东浪潮科学研究院有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!