基于自然语言的舆情追踪方法及装置与流程
本发明涉及自然语言处理,尤其是涉及一种基于自然语言的舆情追踪方法及装置。
背景技术:
1、随着互联网技术的不断发展,现如今互联网信息交互流通庞大、互联网信息更新速度快,想要及时掌握行业舆情动态以及事件在互联网中的发酵程度和关注度,舆情的追踪显得尤为重要。为了实时监测行业舆情,尤其是在事件发生后需要将互联网上关于事件的报道及时反馈给相关部门,现有舆情处理方式主要涉及高频词的tf-idf、kmeans、lrc等算法的处理。虽然通过这些算法可以较好的提取出舆情中的高频词,但是针对单篇舆情仅根据高频词判定舆情关键信息可能会丢失一些重点词,从而导致在后续舆情分析时丢失更多的关键信息。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于自然语言的舆情追踪方法及装置,以缓解现有舆情处理方式中存在的关键信息丢失、处理较复杂的问题。
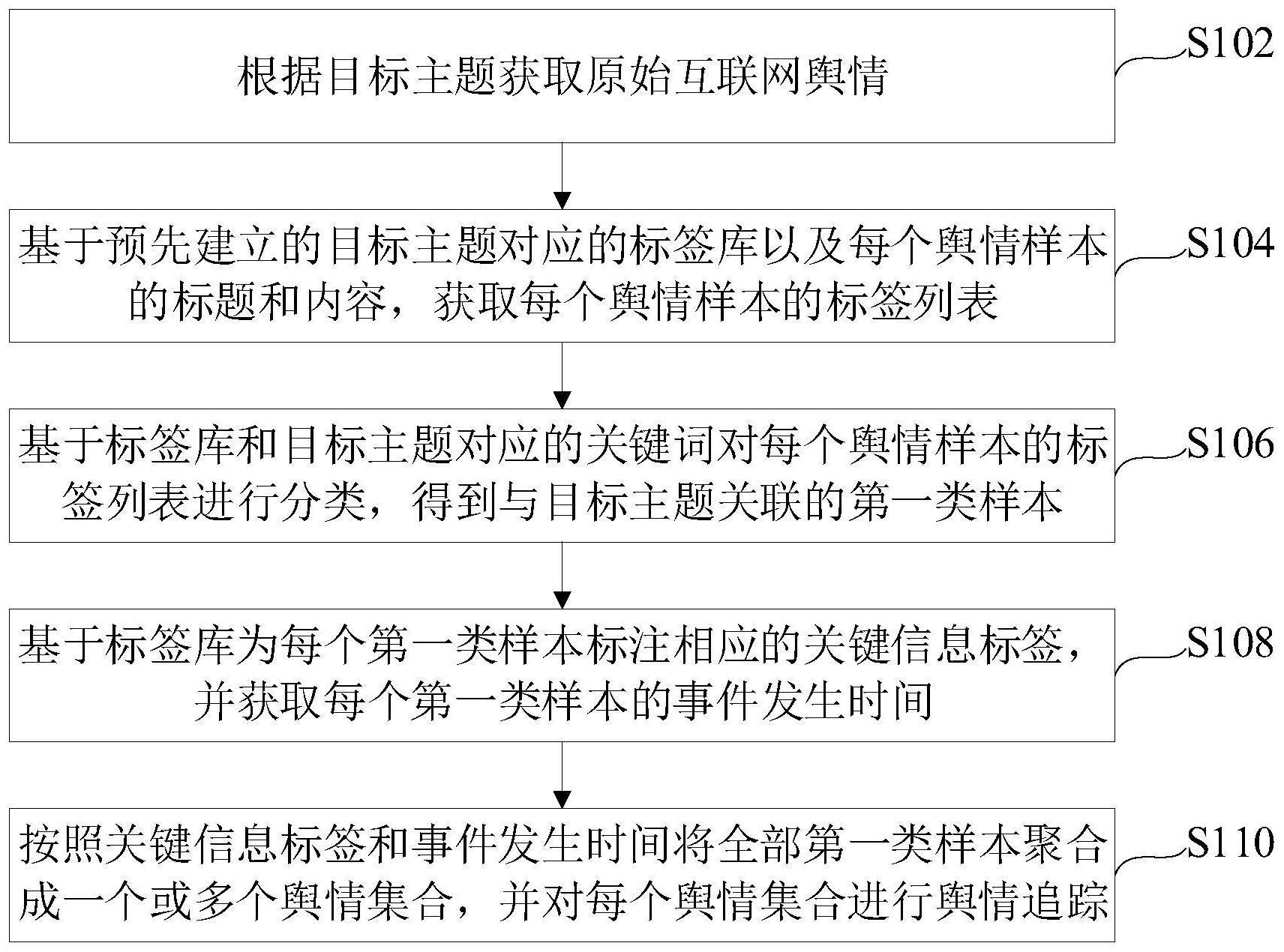
2、第一方面,本发明实施例提供了一种基于自然语言的舆情追踪方法,所述方法包括:根据目标主题获取原始互联网舆情;其中,所述原始互联网舆情包括多个舆情样本;基于预先建立的所述目标主题对应的标签库以及每个舆情样本的标题和内容,获取每个舆情样本的标签列表;基于所述标签库和所述目标主题对应的关键词对每个舆情样本的标签列表进行分类,得到与所述目标主题关联的第一类样本;基于所述标签库为每个第一类样本标注相应的关键信息标签,并获取每个第一类样本的事件发生时间;按照关键信息标签和事件发生时间将全部第一类样本聚合成一个或多个舆情集合,并对每个舆情集合进行舆情追踪。
3、第二方面,本发明实施例还提供一种基于自然语言的舆情追踪装置,所述装置包括:第一获取模块,用于根据目标主题获取原始互联网舆情;其中,所述原始互联网舆情包括多个舆情样本;第二获取模块,用于基于预先建立的所述目标主题对应的标签库以及每个舆情样本的标题和内容,获取每个舆情样本的标签列表;分类模块,用于基于所述标签库和所述目标主题对应的关键词对每个舆情样本的标签列表进行分类,得到与所述目标主题关联的第一类样本;第一处理模块,用于基于所述标签库为每个第一类样本标注相应的关键信息标签,并获取每个第一类样本的事件发生时间;第二处理模块,用于按照关键信息标签和事件发生时间将全部第一类样本聚合成一个或多个舆情集合,并对每个舆情集合进行舆情追踪。
4、本发明实施例提供的一种基于自然语言的舆情追踪方法及装置,根据目标主题获取包括多个舆情样本的原始互联网舆情;基于预先建立的目标主题对应的标签库以及每个舆情样本的标题和内容,获取每个舆情样本的标签列表;基于标签库和目标主题对应的关键词对每个舆情样本的标签列表进行分类,得到与目标主题关联的第一类样本;基于标签库为每个第一类样本标注相应的关键信息标签,并获取每个第一类样本的事件发生时间;按照关键信息标签和事件发生时间将全部第一类样本聚合成一个或多个舆情集合,并对每个舆情集合进行舆情追踪。采用上述技术,针对单个舆情样本可以比较全面、准确地提取出关键信息,且操作方式简单、计算速度快,可以便于相关人员根据舆情追踪结果及时做出响应。
5、本发明的其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
6、为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
技术特征:
1.一种基于自然语言的舆情追踪方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述标签库包括多个第一标签,每个所述第一标签具有各自的标签属性;所述方法还包括:
3.根据权利要求2所述的方法,其特征在于,所述第一标签包括表征目标主题对应的实体归属信息、人员状况信息以及事件类型信息。
4.根据权利要求2所述的方法,其特征在于,基于预先建立的所述目标主题对应的标签库以及每个舆情样本的标题和内容,获取每个舆情样本的标签列表的步骤包括:
5.根据权利要求1所述的方法,其特征在于,获取每个第一类样本的事件发生时间的步骤包括:
6.根据权利要求1或2所述的方法,其特征在于,对每个舆情集合进行舆情追踪的步骤包括:
7.根据权利要求6所述的方法,其特征在于,对每个舆情集合进行舆情追踪的步骤还包括:
8.根据权利要求7所述的方法,其特征在于,采用fpgrowth算法为该第一舆情集合的总标签列表建立相应的fp树的步骤包括:
9.根据权利要求8所述的方法,其特征在于,对每个舆情集合进行舆情追踪的步骤还包括:
10.一种基于自然语言的舆情追踪装置,其特征在于,所述装置包括:
技术总结
本发明提供了一种基于自然语言的舆情追踪方法及装置,根据目标主题获取包括多个舆情样本的原始互联网舆情;基于预先建立的目标主题对应的标签库以及每个舆情样本的标题和内容,获取每个舆情样本的标签列表;基于标签库和目标主题对应的关键词对每个舆情样本的标签列表进行分类,得到与目标主题关联的第一类样本;基于标签库为每个第一类样本标注相应的关键信息标签,并获取每个第一类样本的事件发生时间;按照关键信息标签和事件发生时间将全部第一类样本聚合成一个或多个舆情集合,并对每个舆情集合进行舆情追踪。采用本发明可以缓解现有舆情处理方式中存在的关键信息丢失、处理较复杂的问题。
技术研发人员:李鑫,李锦涛,高敏敏,潘涛
受保护的技术使用者:精英数智科技股份有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!