用于基于人工神经网络分析强化学习代理的方法和设备与流程
本公开涉及用于基于人工神经网络来分析强化学习代理的方法和设备。
背景技术:
1、机器学习被广泛应用于日常设备和计算机应用。除了用人工智能(ai)使流行的应用更具吸引力之外,ai还可用于解决现实世界的复杂问题。一个这样的挑战是以安全和有效的方式规划自动车辆(av)在高速公路上的运动。针对这一问题的有前途的方法是应用深度强化学习(rl)方法,该rl方法使用人工神经网络(ann)来训练决策代理(agent)。然而,基于ann的方法的使用引入了黑盒因素,这使得代理做出的决策不可预测,并因此增加了操作风险。这种因素在必须验证和证明安全性的应用中是不适当的。因此,在不理解ann决策的情况下利用基于ann的方法来规划车辆在道路上的运动对于系统的最终用户可能是有风险的。
2、关于av中的rl,在过去几年中,对在自动车辆的运动规划中使用rl的兴趣越来越大。rl的应用的示例可以被发现用于典型的驾驶场景(诸如车道保持、车道变更、匝道汇入(ramp merging)、超车等)。
3、关于可解释rl,由于机器学习的应用变得更加流行,对其可解释性的需求已经增加。最初,开发了可解释机器学习(iml)的领域,其部分地聚焦于神经网络激活的解释。所述解释依赖于计算ann的输出如何受到网络的给定部分的每个要素的影响。
4、然而,rl的可解释性(xrl)超出了对单个神经激活的理解。这是因为连续状态与引起下一个被访问状态的代理的动作之间的时间依赖性。一序列转换可用于解释代理的关于长期目标的动作。另外,同样重要的是,代理训练的目的是最大化所收集的奖励的总和,而不是如在监督学习的情况下那样将输入映射到真值(ground truth)标签。这些另外的特征允许以内观、因果和对比的方式解释rl代理的行为。
5、xrl的最新进展可分为两大类:透明算法和事后可解释性。透明算法的类包括其模型被构建以支持其可解释性的那些算法。另一种方法是同时学习,其同时学习策略和解释。透明学习的最后一种类型是表示学习,其涉及学习潜在特征以便于代理模型提取有意义的信息。
6、然而,drl算法本来不是透明的;因此,事后可解释性更为普遍。它依赖于用已经训练的代理执行的状态分析和转变的神经激活。
7、一种事后(post-hoc)方法是显著图(saliency map),其可以被应用于以图像作为输入的卷积神经网络(cnn)。该方法生成热图,该热图突出显示图像上cnn的最相关信息。然而,理解个体决策不足以解释代理的一般行为。
8、因此,需要用于理解ann的决定基于什么的方法和设备。
技术实现思路
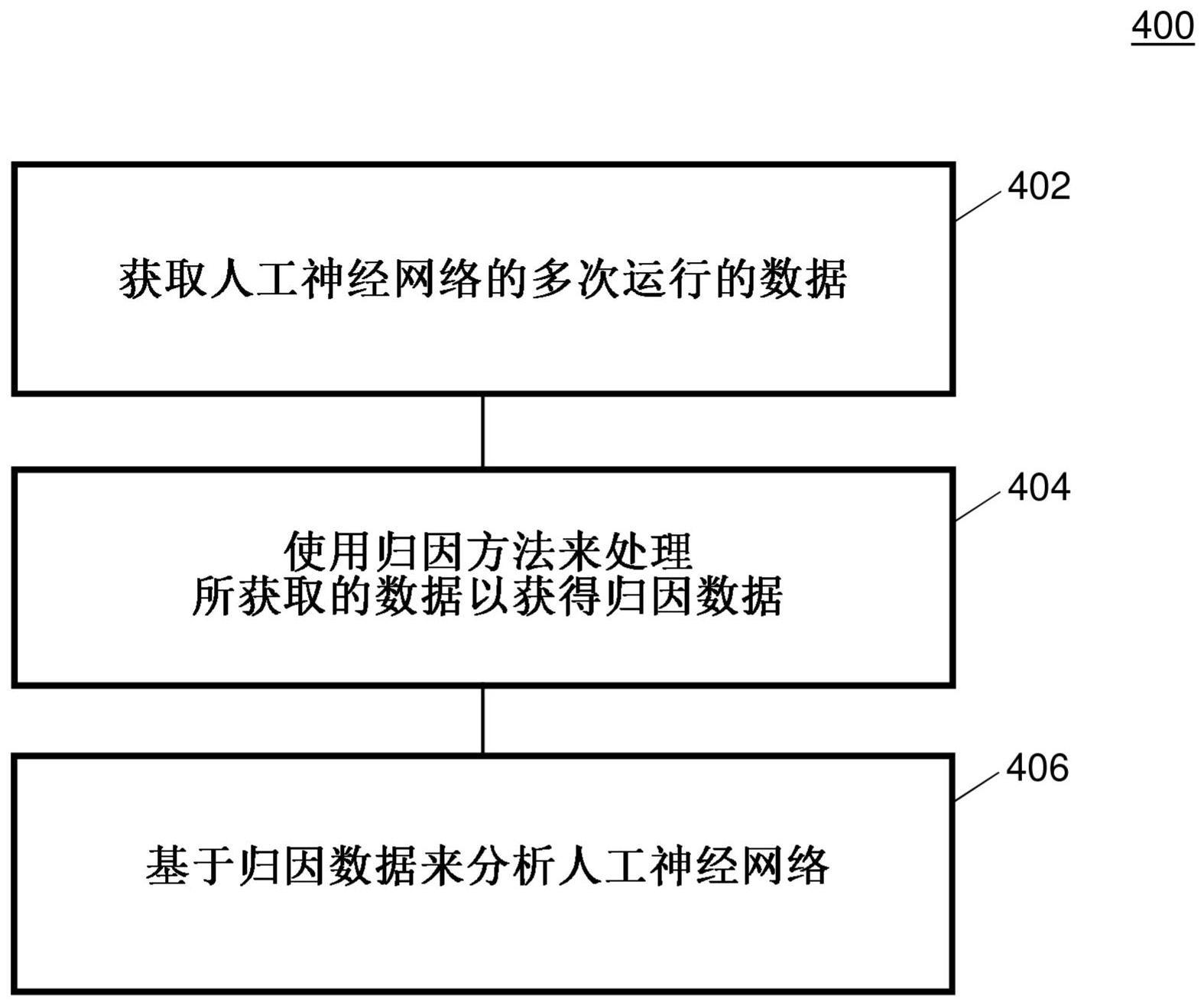
1、在一个方面,本公开旨在一种用于基于人工神经网络来分析强化学习代理的计算机实现方法,该计算机实现方法包括可以由计算机硬件组件执行(换言之:实现)的以下步骤:获取所述人工神经网络的多次运行的数据;使用归因法处理所获取的数据,以获得归因数据;以及基于归因数据对人工神经网络进行分析。
2、归因可以是要素对人工神经网络输出的贡献值。可以将要素输入到人工神经网络,人工神经网络的层或人工神经网络的单个神经元。贡献可以是正的或负的。要素可以有助于返回给定的输出以及有助于不返回给定的输出。
3、根据各种实施方式,在至少一次真实运行期间和/或在至少一次模拟运行期间获取数据。
4、根据各个实施方式,归因方法是基于沿着从基线到输入数据的路径相对于所述输入数据确定梯度的。
5、基线可以是人工神经网络的任意组成的输入,其对于模型可以是中性的。中性可以意味着当被提供了中性输入时人工神经网络应当返回默认值(例如在分类问题中,当被提供了中性输入时人工神经网络应当针对所有类返回相等预测)。
6、根据各种实施方式,基线表示对所有可能输入的总体引用。
7、根据各个实施方式,归因方法包括集成梯度、deeplift、梯度shap或引导反向传播和反卷积中的至少一项。
8、根据各个实施方式,该计算机实现方法还包括将归因数据划分为多个组,其中,人工神经网络是基于所述多个组来分析的。
9、根据各个实施方式,该计算机实现方法还包括确定参数之间的相关性、与参数相关的归因以及人工神经网络的输出。
10、所述参数可以是由人工神经网络消耗的输入向量。例如,所述参数可以描述自我车辆特征、检测到的对象和/或道路几何形状。因此,所计算的相关性可以检查参数值与归因值之间关于人工神经网络的输出的关系。
11、根据各种实施方式,相关包括pearson相关和/或spearson秩相关系数。
12、根据各种实施方式,该计算机实现方法被应用于运动规划模块。
13、如本文所述,机动代理可使用离散动作空间(分类问题),而acc代理可使用连续动作空间(回归)。
14、根据各种实施方式,分析人工神经网络包括检测人工神经网络中或人工神经网络的输入数据中的错误。
15、根据各种实施方式,该计算机实现方法提供用于解释人工神经网络的本地和事后方法。
16、在另一方面,本公开旨在一种计算机系统,所述计算机系统包括多个计算机硬件组件,所述多个计算机硬件组件被配置成执行本文所述的计算机实现的方法的若干或所有步骤。
17、该计算机系统可以包括多个计算机硬件组件(例如处理器(例如处理单元或处理网络)、至少一个存储器(例如存储器单元或存储器网络)以及至少一个非暂时性数据存储装置)。应当理解,可以提供另外的计算机硬件组件并用于在计算机系统中执行计算机实现的方法的步骤。非暂时性数据存储器和/或存储器单元可以包括计算机程序,用于指示计算机例如使用处理单元和至少一个存储器单元执行在此描述的计算机实现的方法的若干或所有步骤或方面。
18、在另一方面,本公开旨在一种包含指令的非暂时性计算机可读介质,所述指令在由处理器执行时造成(或使得)该处理器执行在此描述的计算机实现的方法的若干或所有步骤或方面。所述计算机可读媒介可以被配置为:光学介质,例如光盘(cd)或数字多功能盘(dvd);磁介质,例如硬盘驱动器(hdd);固态驱动器(ssd);只读存储器(rom),例如闪存;等等。此外,计算机可读介质可以被配置为可经由诸如因特网连接的数据连接来访问的数据存储。计算机可读介质例如可以是在线数据储存库或云存储。
19、本公开还旨在一种用于指示计算机执行本文所述的计算机实现的方法的若干或所有步骤或方面的计算机程序。
技术特征:
1.一种基于人工神经网络分析强化学习代理的计算机实现方法,所述计算机实现方法包括由计算机硬件组件执行的以下步骤:
2.根据权利要求1所述的计算机实现方法,其中,所述数据是在至少一次真实运行期间和/或在至少一次仿真运行期间获取的。
3.根据权利要求1或2所述的计算机实现方法,其中,所述归因方法是基于沿着从基线到输入数据的路径相对于所述输入数据确定梯度的。
4.根据权利要求3所述的计算机实现方法,其中,所述基线表示对所有可能的输入的总体引用。
5.根据权利要求1至4中任一项所述的计算机实现方法,其中,所述归因方法包括积分梯度、deeplift、梯度shap或引导反向传播和反卷积中的至少一项。
6.根据权利要求1至5中任一项所述的计算机实现方法,所述计算机实现方法还包括由所述计算机硬件组件执行的以下步骤:
7.根据权利要求1至6中任一项所述的计算机实现方法,所述计算机实现方法还包括由所述计算机硬件组件执行的以下步骤:
8.根据权利要求7所述的计算机实现方法,其中,所述相关包括pearson相关和/或spearman秩相关系数。
9.根据权利要求1至8中任一项所述的计算机实现方法,其中,所述计算机实现方法被应用于运动规划模块。
10.根据权利要求1至9中任一项所述的计算机实现方法,其中,分析所述人工神经网络包括检测所述人工神经网络中或所述人工神经网络的输入数据中的错误。
11.根据权利要求1至10中任一项所述的计算机实现方法,其中,所述计算机实现的方法提供用于解释所述人工神经网络的本地和事后方法。
12.一种计算机系统(500),所述计算机系统(500)包括多个计算机硬件组件,所述多个计算机硬件组件被配置为执行根据权利要求1至11中任一项所述的计算机实现方法的步骤。
13.一种非暂时性计算机可读介质,所述非暂时性计算机可读介质包含用于执行根据权利要求1至11中任一项所述的计算机实现方法的指令。
技术总结
用于基于人工神经网络分析强化学习代理的方法和设备。一种用于基于人工神经网络分析强化学习代理的计算机实现方法包括:获取所述人工神经网络的多次运行的数据;使用归因方法处理所获取的数据以获得归因数据;基于归因数据对人工神经网络进行分析。
技术研发人员:N·潘基维奇,P·科瓦尔茨克,M·奥尔沃夫斯基,W·图尔杰
受保护的技术使用者:APTIV技术有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!