一种用于视觉定位的特征提取模型的训练方法及装置
本发明涉及视觉定位,具体涉及一种用于视觉定位的特征提取模型的训练方法及装置。
背景技术:
1、视觉定位是一个估计6自由度(dof)相机姿态的问题,由此获取一幅图像相对于给定的参考场景的表示。相机姿态用于描述相机在世界坐标系(3d空间)中的位置和方向。相较于全球定位系统(gps)、激光雷达、毫米波雷达,将摄像头作为传感器部署在车辆上成本较低,且摄像头所拍摄的视觉内容丰富。因此视觉定位成为目前最主流的辅助自动驾驶定位技术之一。除了应用于自动驾驶外,视觉定位也是增强、混合虚拟现实的关键技术,还可以为环境感知和路径规划等提供参考和指导。增强现实(ar)技术可以通过投影将三维(3d)虚拟对象叠加到真实环境的图像上,以增强实时图像。增强现实在军事训练、教育、游戏和娱乐等方面具有广泛的应用前景。对于ar游戏来说,相机姿态的准确估计可以改善ar游戏体验。对于ar导航系统来说,视觉定位技术可以提供更高精度的定位来实现精确的ar交互显示,带来更加身临其境的实景导航体验。除此之外,视觉定位还可以应用于无人机驾驶,确保无人机稳定悬停,保证飞机姿态修正和基准定位。
2、综上所述,视觉定位是自动驾驶和增强虚拟现实等领域的核心技术之一,其在现实生活中有着广泛的应用前景。视觉定位方法主要包括基于图像检索的定位方法、基于结构的定位方法和基于分层的定位方法等。基于图像的检索定位方法精度较差,无法满足高精度应用场景的需求。基于结构的定位方法通常从数据库图像中建立sfm模型,在查询图像和点云之间建立2d-3d对应关系,然后利用这些对应关系进行相机姿态估计,从而计算查询图像的摄像机姿态。然而,其需要搜索每个3d点以查询特征,效率并不高。基于分层的定位方法简单有效,结合了基于图像检索和基于结构的定位方法的优点。基于分层的定位方法将定位问题划分为特征提取、全局检索、局部特征匹配和精细位姿估计四部分。通常,训练cnn网络用于特征提取,回归图像的局部描述子用于2d-3d匹配,使用先进的全局描述子用于图像检索,最后利用基于ransac的方法进行相机姿态估计。这种从粗到细的分层定位方法可以较好地平衡了定位过程中准确性和效率的问题。
3、近年来,视觉定位研究在一些公开数据集上取得了良好的效果,但仍面临着来自光照和环境变化的挑战。针对同一个场景,假设建图的时间是白天,而定位的时间是晚上,方法的定位精度较低。同样地,当建图与定位遇到的天气状况、季节不同时,视觉定位系统的精度也难以满足要求。其原因是在大的条件变化下,特征提取任务能够提取到的特征信息数量和质量是不稳定的。
技术实现思路
1、本发明的目的在于提供一种用于视觉定位的特征提取模型的训练方法及装置,旨在解决现有技术中特征提取任务能够提取到的特征信息数量和质量不稳定的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、一方面提供了一种用于视觉定位的特征提取模型的训练方法,所述训练方法包括如下步骤:
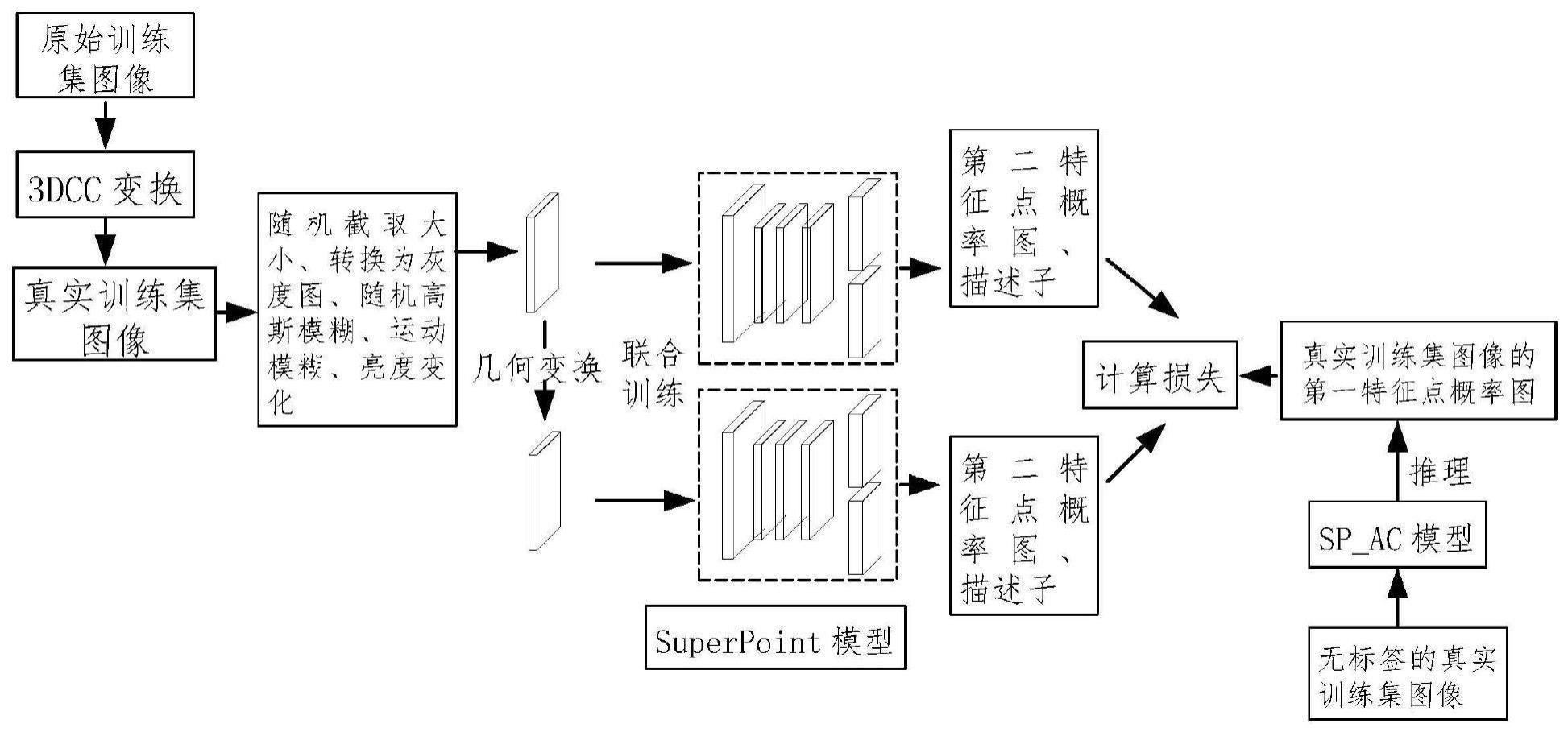
4、将无标签的原始训练集图像进行数据增强得到无标签的真实训练集图像,所述无标签的真实训练集图像包括景深图像和雾图像;
5、根据所述真实训练集图像得到第一图像对并将其输入融合自注意力和卷积混合模块的模型得到第一特征点概率图;
6、将所述真实训练集图像输入所述特征提取基础模块得到第二特征点概率图和描述子;
7、根据所述第一特征点概率图、所述描述子以及所述第二特征点概率图计算得到最终损失。
8、另一方面提供了一种用于视觉定位的特征提取模型的训练系统,所述训练系统包括至少一个处理器;以及存储器,其存储有指令,当通过至少一个处理器来执行该指令时,实施按照前述的方法的步骤。
9、本发明的有益效果在于,通过自监督的方式同时提取图像特征点和描述子,将3dcc变换应用于训练阶段,通过模拟现实世界中计算机视觉模型将遇到的自然分布变化进行离线数据增强,提高了模型的健壮性;使用融合了自注意力和卷积混合模块的sp-ac模型推理真实训练集的伪标签,增强了伪标签的质量,从而提高了模型特征提取的质量且保持计算成本不变;应用于视觉定位中的特征提取任务,使得定位技术能够提取到的特征信息的数量和质量大大提高,从而有效提高了定位精度;本发明在提高定位精度的同时仅消耗较小的定位时间,较好地权衡了定位过程中准确性和效率。
技术特征:
1.一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述训练方法包括如下步骤:
2.根据权利要求1所述的一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述将无标签的原始训练集图像进行数据增强得到无标签的真实训练集图像包括:
3.根据权利要求1所述的一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述将无标签的原始训练集图像进行数据增强得到无标签的真实训练集图像还包括:
4.根据权利要求1所述的一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述根据所述真实训练集图像得到第一图像对并将其输入融合自注意力和卷积混合模块的模型得到第一特征点概率图包括:
5.根据权利要求4所述的一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述第一共享编码器模块包括acmix层、第一conv层、maxpool层、第一非线性函数relu层和第一batchnorm归一化层,所述acmix层被配置为:
6.根据权利要求5所述的一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述第一特征点检测解码器模块被配置为:
7.根据权利要求6所述的一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述将所述真实训练集图像输入所述特征提取基础模块得到第二特征点概率图和描述子包括:
8.根据权利要求7所述的一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述最终损失的计算表达式如式(3)所示:
9.根据权利要求8所述的一种用于视觉定位的特征提取模型的训练方法,其特征在于,所述式(5)中,训练图像(h,w)单元和变换图像(h',w')单元中所有对应关系的集合的关系表达式如式(6)所示:
10.一种用于视觉定位的特征提取模型的训练系统,其特征在于,所述训练系统包括至少一个处理器;以及存储器,其存储有指令,当通过至少一个处理器来执行该指令时,实施按照权利要求1-9任一项所述的方法的步骤。
技术总结
本发明涉及一种用于视觉定位的特征提取模型的训练方法,所述训练方法包括如下步骤:将无标签的原始训练集图像进行数据增强得到无标签的真实训练集图像,所述无标签的真实训练集图像包括景深图像和雾图像;根据所述真实训练集图像得到第一图像对并将其输入融合自注意力和卷积混合模块的模型得到第一特征点概率图;通过自监督的方式同时提取图像特征点和描述子,将3DCC变换应用于训练阶段,通过模拟现实世界中计算机视觉模型将遇到的自然分布变化进行离线数据增强,提高了模型的健壮性;使用融合了自注意力和卷积混合模块的SP‑AC模型推理真实训练集的伪标签,增强了伪标签的质量,从而提高了模型特征提取的质量且保持计算成本不变。
技术研发人员:李艳凤,张又,陈后金,孙嘉,陈紫微
受保护的技术使用者:北京交通大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!