一种基于Hive的前置知识库优化方法与流程
本发明涉及一种基于hive的前置知识库优化方法,属于数据库、大数据。
背景技术:
1、 在大规模使用的hive计算引擎中,数据运算往往经过去重处理、分组处理、连接处理、条件处理,求和处理等一种或者多种的组合逐步实现运算过程。在此场景下,使用hive自带的cbo优化器(基于代价的优化器cost based optimization)对运算进行优化,在编译阶段,cbo根据查询条件与使用的表,对运算中具有join(连接查询)的步骤调整运算顺序,减少中间数据量来达到优化目的。
2、现有的hive cbo技术主要有三个缺点: 一,在处理join性能上有其优势,但未对各种运算逻辑(group,join,distinct,union等组合)全方位优化;二,对数据模型(hive表)感知度不高,优化粒度是在已存在模型(hive表)的粒度,进而对模型之上的运算进行优化,然而对于模型自身设计是否合理、模型属性是否匹配等模型级别的粒度cbo有其缺陷;三,cbo偏向于后置优化,未能做到动态优化,对于需要提前优化的运算,往往需要专业人员手动干预,根据理论与经验,进行大量的参数调优后,才能释放性能。
技术实现思路
1、本发明目的是提供了一种基于hive的前置知识库优化方法,提高hive引擎对业务的感知度。
2、本发明为实现上述目的,通过以下技术方案实现:
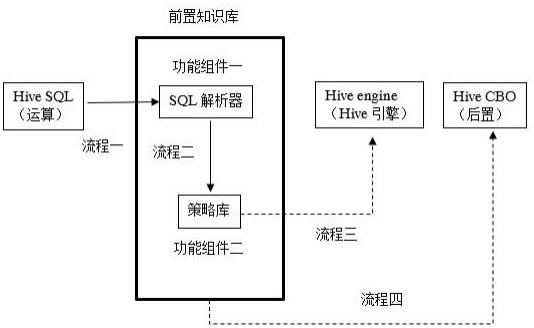
3、将hive sql输入到前置知识库,得到hive sql优化策略;所述前置知识库包括sql解析器和策略库,所述sql解析器对hive sql进行运算逻辑和表属性解析;所述运算逻辑解析包括解析逻辑运算的频次与深度,所述表属性解析包括解析表大小、字段数、小文件数;所述策略库将sql解析器解析的运算集合通过策略库的规则算法,生成set参数策略;将生成的set参数策略与hive交互,设置在sql之前,实现前置优化。
4、优选的,所述sql解析器对hive sql进行解析包括:
5、预处理获取的标准sql,对运算及其子运算以一个完整的select为单位进行切割,并解析每个select的运算逻辑;定义hivesql语法树的解析结构,所述解析结构为运算和子运算中使用的逻辑操作拼装成的树状结构;对sql编号并解析,将解析后的语法树做缓存处理,提高语法解析程序性能;将解析到的语法树作为输入参数输入到算法中处理生成运算集合;通过解析后的表属性按照表名到物理表实际获取的其他属性,从hive数据库中取到真实值,对模型本身的表属性填充,将解析结果以标准数据格式输入策略库。
6、优选的,所述将解析后的语法树做缓存处理采用redis缓存技术,其中key为sql编号,value为具体的语法树结构,以文本形式存入缓存。
7、优选的,所述算法包括以下两种方式:根据运算和子运算中使用的具体操作出现的频次高低生成到运算集合,或根据语法树深度,按照语法树中深度大小生成到运算集合。
8、优选的,所述策略库包括规则库、模型策略表和set策略表,所述规则库包括规则表和计算公式表。
9、优选的,所述策略库生成set参数策略具体方式如下:
10、sql解析器的解析结果输入到策略库,将逻辑运算频次和深度与规则库表中的规则和计算公式表中的计算公式匹配;将表的属性参数输入到公式计算,将匹配到的规则与表属性对具体的set数值进行计算,生成最终的set策略。
11、本发明的优点在于:本发明通过结合cbo,在其后置特性基础上,增加前置知识库优化方法,解决了上述缺陷,将运算(hive sql)作为输入参数,对hive sql进行解析,解析后的运算集合经过策略库匹配到合适的优化策略,提高hive引擎对业务的感知度。
技术特征:
1.一种基于hive的前置知识库优化方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于hive的前置知识库优化方法,其特征在于,所述sql解析器对hive sql进行解析包括:
3.根据权利要求2所述的基于hive的前置知识库优化方法,其特征在于,所述将解析后的语法树做缓存处理采用redis缓存技术,其中key为sql编号,value为具体的语法树结构,以文本形式存入缓存。
4.根据权利要求3所述的基于hive的前置知识库优化方法,其特征在于,所述算法包括以下两种方式:根据运算和子运算中使用的具体操作出现的频次高低生成到运算集合,或根据语法树深度,按照语法树中深度大小生成到运算集合。
5.根据权利要求1所述的基于hive的前置知识库优化方法,其特征在于,所述策略库包括规则库、模型策略表和set策略表,所述规则库包括规则表和计算公式表。
6.根据权利要求5所述的基于hive的前置知识库优化方法,其特征在于,所述策略库生成set参数策略具体方式如下:
技术总结
本发明提供了一种基于Hive的前置知识库优化方法,属于数据库、大数据技术领域。预先在编译之前介入对Hive SQL的优化,解析SQL中的运算集合,从策略库中匹配满足运算集合的优化策略,所述前置知识库包括SQL解析器和策略库,所述SQL解析器对Hive SQL进行运算逻辑和表属性解析;所述策略库将SQL解析器解析的运算集合通过策略库的规则算法,生成set参数策略;将生成的set参数策略与Hive交互,设置在SQL之前,实现前置优化。与现有技术相比,通过解析运算逻辑,提前将优化策略生成到引擎中,前置知识库可以提升引擎与业务交互,提高业务对底层引擎的感知,同时提升了运算性能。
技术研发人员:李克学,张婉蒙,叶迎春,陈刚,王恒军
受保护的技术使用者:山东未来网络研究院(紫金山实验室工业互联网创新应用基地)
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!