一种热点事件挖掘方法、系统、装置与存储介质与流程
本申请涉及数据处理,尤其是一种热点事件挖掘方法、系统、装置与存储介质。
背景技术:
1、近年来,随着政务服务工作转到线上,政务数据库会形成大量的政务工单,并以自然语言文本的形式保存下来。这些政务工单中包含了大量的热点事件相关的信息,因此对其进行分析和挖掘可以发现当前热点的各类事件。
2、相关技术中,热点事件挖掘的主流方法是基于聚类算法,即基于预训练语言模型以及基于政务工单文本的语义相似度对其进行聚类处理,并从聚类结果中筛选热点事件。但是该方法的预训练的语言模型是面向开放领域的,其无法有效表征政务领域中的一些专业概念和词汇以及难以标注政务工单,导致其无法利用下游任务来优化预训练语言模型,最终使热点事件挖掘准确度降低,导致该方法不能很好地适应政务专业领域的需求。因此,相关技术中仍存在技术问题亟需解决。
技术实现思路
1、本申请的目的在于至少一定程度上解决现有技术中存在的技术问题之一。
2、为此,本申请实施例的一个目的在于提供一种热点事件挖掘方法、系统、装置与存储介质,该方法、系统、装置与存储介质可以提高热点事件挖掘的准确度。
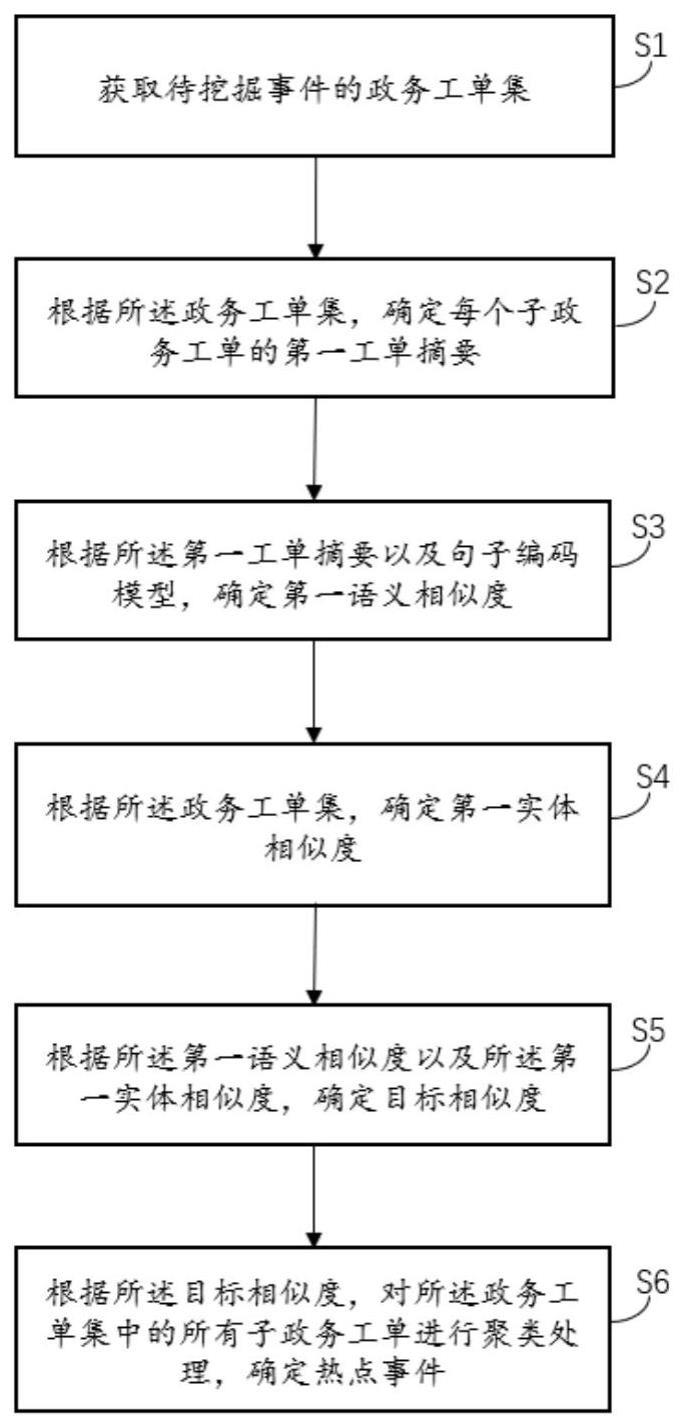
3、为了达到上述技术目的,本申请实施例所采取的技术方案包括:获取待挖掘事件的政务工单集,所述政务工单集中包括若干子政务工单;根据所述政务工单集,确定每个所述子政务工单的第一工单摘要;根据所述第一工单摘要以及句子编码模型,确定第一语义相似度;所述第一语义相似度用于表征所述第一工单摘要对应的任意两个子政务工单的语义相似度;根据所述政务工单集,确定第一实体相似度;所述第一实体相似度用于表征任意两个子政务工单所对应的政务实体的实体相似度;根据所述第一语义相似度以及所述第一实体相似度,确定目标相似度;根据所述目标相似度,对所述政务工单集中的所有所述子政务工单进行聚类处理,确定热点事件。
4、另外,根据本发明中上述实施例的一种热点事件挖掘的方法,还可以有以下附加的技术特征:
5、进一步地,本申请实施例中,所述根据所述政务工单集,确定每个所述子政务工单的第一工单摘要这一步骤,具体包括:构建子政务工单的句子关联图;根据所述句子关联图,确定每个句子对应节点的第一节点权重;将所述第一节点权重的排序在前若干个的节点对应的句子确定为第一工单摘要。
6、进一步地,本申请实施例中,所述根据所述第一工单摘要以及句子编码模型,确定第一语义相似度这一步骤,具体包括:根据所述第一工单摘要以及所述句子编码模型,确定若干个句子向量;根据所述若干个句子向量中任意两个句子向量,确定第一语义相似度。
7、进一步地,本申请实施例中,所述根据所述政务工单集,确定第一实体相似度这一步骤,具体包括:提取所述政务工单集的每个子政务工单中所有句子包含的政务实体,确定每个子政务工单所对应的政务实体列表,根据任意两个所述政务实体列表以及相似度计算公式,确定任意两个子政务工单的实体相似度;其中所述相似度计算公式包括:
8、
9、其中,eli和elj分别为任意两个子政务工单所对应的政务实体列表;∩为交集运算,∪为并集运算,esim(i,j)为第一实体相似度。
10、进一步地,本申请实施例中,所述根据所述第一语义相似度以及所述第一实体相似度,确定目标相似度这一步骤,具体包括:根据所述第一语义相似度、所述第一实体相似度以及融合公式,确定目标相似度;其中所述融合公式包括:
11、fsim(i,j)=λ×ssim(i,j)+(1-λ)×esim(i,j)
12、其中,ssim(i,j)为第一语义相似度,esim(i,j)为第一实体相似度,fsim(i,j)为目标相似度,0<λ<1。
13、进一步地,本申请实施例中,所述构建子政务工单的句子关联图这一步骤,具体包括:将所述政务工单按句子进行拆分并根据字数进行过滤,确定句子列表;根据所述句子编码模型以及所述句子列表,确定任意两个句子的句子向量,将所述任意两个句子向量的余弦相似度作为任意两个句子的第一关联度;根据所述句子列表确定政务实体数量;根据所述第一关联度以及所述政务实体数量,确定政务工单的句子关联图。
14、进一步地,本申请实施例中,所述根据所述若干个句子向量中任意两个句子向量,确定第一语义相似度这一步骤,具体包括:提取任意两个句子的句子向量分别作为第一向量以及第二向量;根据所述第一向量、所述第二向量以及相似度计算公式,确定第一语义相似度,所述相似度计算公式包括:
15、
16、其中ssim(i,j)为第一语义相似度,hia为第一向量,hjb为第二向量,sim(,)为相似度运算符,为取最大值运算。
17、另一方面,本申请实施例还提供一种热点事件挖掘系统,包括:获取单元,用于获取待挖掘事件的政务工单集,所述政务工单集中包括若干子政务工单;第一处理单元,用于根据所述政务工单集,确定每个所述子政务工单的第一工单摘要;第二处理单元,用于根据所述第一工单摘要以及句子编码模型,确定第一语义相似度;所述第一语义相似度用于表征所述第一工单摘要对应的任意两个子政务工单的语义相似度;第三处理单元,用于根据所述政务工单集,确定第一实体相似度;所述第一实体相似度用于表征任意两个子政务工单所对应的政务实体的实体相似度;第四处理单元,用于根据所述第一语义相似度以及所述第一实体相似度,确定目标相似度第五处理单元,用于根据所述目标相似度,对所述政务工单集中的所有所述子政务工单进行聚类处理,确定热点事件。
18、另一方面,本申请还提供一种热点事件挖掘装置,包括:
19、至少一个处理器;
20、至少一个存储器,用于存储至少一个程序;
21、当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如
技术实现要素:
中任一项所述一种热点事件挖掘方法。
22、此外,本申请还提供一种存储介质,其中存储有处理器可执行的指令,所述处理器可执行的指令在由处理器执行时用于执行如上述任一项所述一种热点事件挖掘方法。
23、本申请的优点和有益效果将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到:
24、本申请可以根据政务工单集确定任意两个政务工单的政务实体相似度以及确定政务工单的工单摘要中任意两个子政务工单的语义相似度,根据语义相似度以及实体相似度确定热点事件。该方法结合了语义相似度以及政务实体相似度,通过政务实体增强对政务工单的摘要的进行聚类的能力,可以提高模型对政务领域的适配能力,可以提高热点事件挖掘的准确度。
技术特征:
1.一种热点事件挖掘方法,其特征在于,包括以下步骤:
2.根据权利要求1所述一种热点事件挖掘方法,其特征在于,所述根据所述政务工单集,确定每个所述子政务工单的第一工单摘要这一步骤,具体包括:
3.根据权利要求1所述一种热点事件挖掘方法,其特征在于,所述根据所述第一工单摘要以及句子编码模型,确定第一语义相似度这一步骤,具体包括:
4.根据权利要求1所述一种热点事件挖掘方法,其特征在于,所述根据所述政务工单集,确定第一实体相似度这一步骤,具体包括:
5.根据权利要求1所述一种热点事件挖掘方法,其特征在于,所述根据所述第一语义相似度以及所述第一实体相似度,确定目标相似度这一步骤,具体包括:
6.根据权利要求2所述一种热点事件挖掘方法,其特征在于,所述构建所述子政务工单的句子关联图这一步骤,具体包括:
7.根据权利要求3所述一种热点事件挖掘方法,其特征在于,所述根据所述若干个句子向量中任意两个句子向量,确定第一语义相似度这一步骤,具体包括:
8.一种热点事件挖掘系统,其特征在于,包括:
9.一种热点事件挖掘装置,其特征在于,包括:
10.一种计算机可读存储介质,其中存储有处理器可执行的指令,其特征在于,所述处理器可执行的指令在由处理器执行时用于执行如权利要求1-7任一项所述一种热点事件挖掘方法。
技术总结
本申请公开了一种热点事件挖掘方法、系统、装置和存储介质,其中方法包括以下步骤:获取待挖掘事件的政务工单集;根据政务工单集,确定每个子政务工单的第一工单摘要;根据第一工单摘要以及句子编码模型,确定第一语义相似度;第一语义相似度用于表征第一工单摘要对应的任意两个子政务工单的语义相似度;根据政务工单集,确定第一实体相似度;第一实体相似度用于表征任意两个子政务工单所对应的政务实体的实体相似度;根据第一语义相似度以及第一实体相似度,确定目标相似度;根据目标相似度,对政务工单集中的所有子政务工单进行聚类处理,确定热点事件。本方法可以提高热点事件挖掘的准确度。本申请可广泛应用于数据处理技术领域内。
技术研发人员:童海,孙礼红
受保护的技术使用者:中国电信股份有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!