一种基于文本核心信息抽取的金融因果关系链构建方法
本发明属于自然语言处理的信息抽取领域,具体涉及因果关系二分类、因果关系抽取和语义相似度计算。
背景技术:
1、在大数据时代,越来越多的人开始利用金融新闻进行投资理财。金融领域的文本信息量大且价值高,尤其是其中的隐式因果关系事件包含着巨大的潜在利用价值,而现如今针对海量金融新闻事件挖掘、分析、金融知识总结提取应用工作基本处于空白状态。通过本项目的研究,从真实金融新闻文本中挖掘隐式因果关系事件中隐含的重要信息、抽取因果关系和构建金融事件因果关系链,有助于了解金融领域事件更深层的演化逻辑,对于金融领域分析和决策具有一定的指导意义。
2、目前,因果关系识别的方法主要分为两大类:基于模式匹配的方法和基于深度学习的方法。基于模式匹配的方法需要人工总结因果关系关键标识词,构建因果关系模板,通过因果关系模板与原句匹配发现因果关系。基于深度学习的方法需要构建统计模型或神经网络自动学习文本的因果特征,无须预先学习语义知识即可实现因果关系的抽取。例如,使用双向lstm编解码器提取事件实体,通过cnn分类器获取实体之间的关系,实现了事件之间的关系抽取。随着越来越多的学者对深度学习研究的深入,基于神经网络的信息抽取方法逐步占据主导地位。
3、然而,金融领域因果关系识别还存在以下问题。例如:对有明显触发词的显示因果关系识别效果较好而对于隐式因果关系识别准确度不高;面对新的金融新闻事件数量迅速增加,不能需要识别大量未登录的金融词语;大部分文本含有噪音,非核心词语经常影响金融事件相似度计算的准确性。由于金融领域因果关系识别存在的问题以及缺乏对大量金融新闻事件挖掘,鲜有能有效预测经济事件演变路径的金融领域因果关系链。
技术实现思路
1、为了解决现有领域技术的不足,本发明的目的在于提供一种基于文本核心信息抽取的金融因果关系链构建方法,利用过往发生的事件构建因果关系链,当某事件再次发生时,可推导出将来可能发生的演变,可用于预测经济事件的演变路径及股票预测等下游任务。
2、基于文本核心信息抽取的金融领域因果关系链构建方法,通过以下技术方案予以实现。
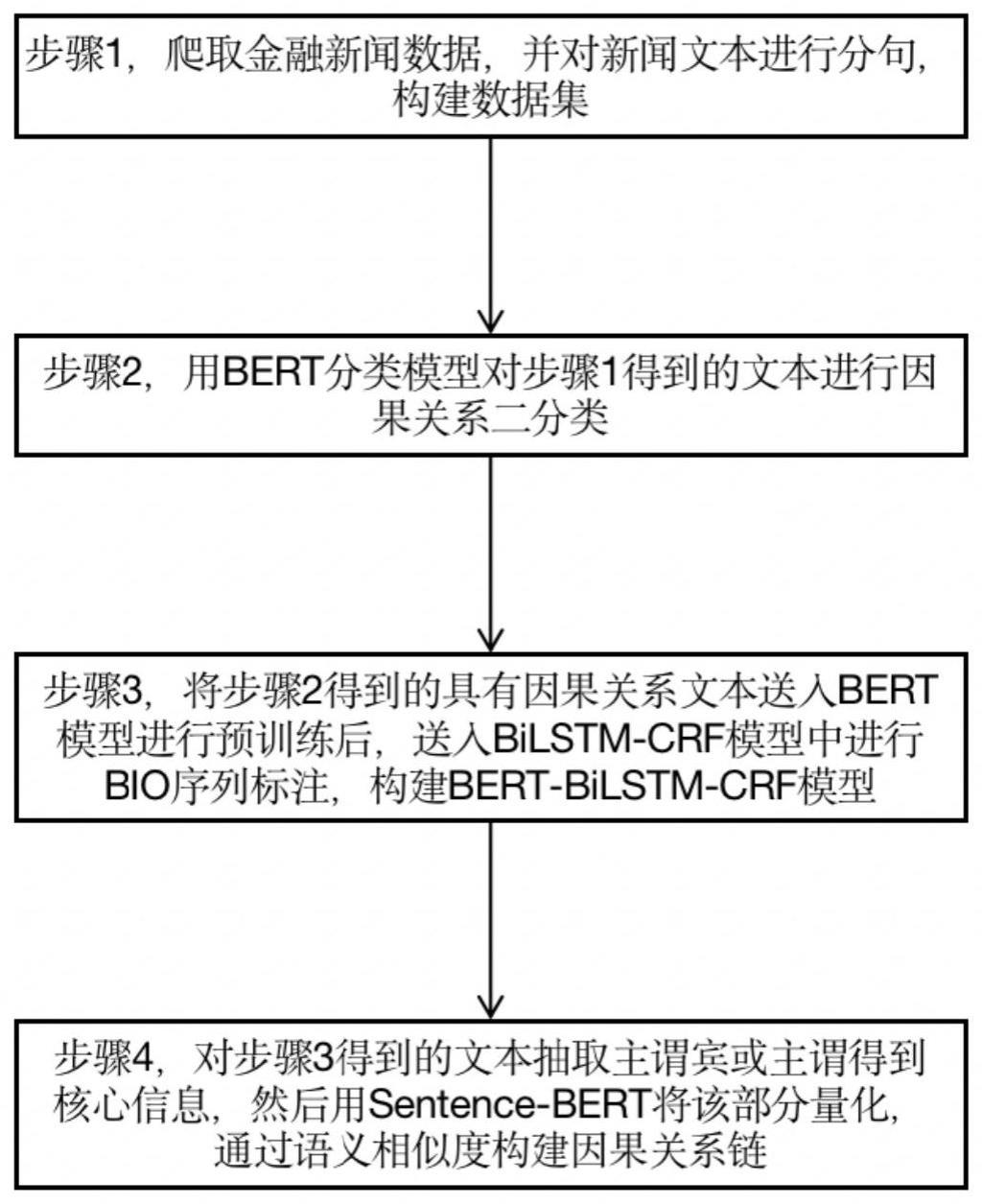
3、s1:爬取金融新闻数据,并对新闻文本进行分句,构建文本数据集;
4、s2:用bert分类模型对文本进行因果关系二分类;
5、s3:对具有因果关系的文本用bert模型进行预训练,送入bilstm-crf模型进行bio序列标注,构建bert-bilstm-crf模型;
6、s4:对经过bio序列标注的文本原因和结果部分进行文本核心信息抽取,然后用sentence-bert将其转换成向量,计算文本间的余弦相似度,根据相似度矩阵构建因果关系链;
7、优选地,基于文本核心信息抽取的金融领域因果关系链构建方法,所述s1的具体过程为:
8、s101:从东方财富网爬取新闻,对新闻进行分句处理;
9、s102:利用transformers包tokenizer.encode()方法对文本数据编码并统一编码格式;
10、s103:人工筛选设置标签,将有因果关系的句子标记为tag:1,无因果关系的句子标记为tag:0;
11、s104:将数据保存为json格式。按比例划分为训练集、验证集和测试集;
12、优选地,基于文本核心信息抽取的金融领域因果关系链构建方法,所述s2的具体过程为:
13、s201:利用bert网络对s104得到的数据进行预训练;
14、s202:载入transformer里的bertforsequenceclassification模块,并完成分类模型的微调任务;
15、s203:定义一个train()函数完成模型的训练;
16、s204:将外来样本送入bert分类模型中,进行分类;
17、s205:对错误的分类结果进行人工反馈纠正;
18、优选地,基于文本核心信息抽取的金融领域因果关系链构建方法,所述s3的具体过程为:
19、s301:将s205得到的具有因果关系文本送入bert模型进行预训练;
20、s302:送入bilstm-crf模型中进行bio序列标注,标注标签为b-c、i-c、b-r、i-r、b-c_clue、b-c_clue、b-r_clue、i-r_clue、o;
21、优选地,基于文本核心信息抽取的金融领域因果关系链构建方法,所述s4的具体过程为:
22、s401:读取s3得到的数据,根据标签把原因部分的文本存为列表,结果部分文本存为列表;
23、s402:计算文本a的结果部分和文本b原因部分相似度;
24、s403:将所有的原因和结果部分做相似度匹配;
25、s404:计算相似度矩阵,将s403得到的结果存入一个二维矩阵。其中,矩阵的行代表原因,列代表结果,矩阵里面的值为原因和结果的相似度值。
26、s405:根据相似度矩阵,构建因果关系链;
27、优选地,基于文本核心信息抽取的金融领域因果关系链构建方法,所述s402的具体过程为:
28、s4021:用ltp.pipeline()方法提取原因和结果部分的主谓或者主谓宾来文本噪音,保留核心字段;
29、s4022:加载sentence-bert里的distiluse-base-multilingual-cased-v1模型将原因和结果文本转化成向量;
30、s4023:用cosine_similarity()函数计算相似度,当原因和结果相似度大于或等于阈值0.9时,判定两者相同;
31、与现有技术相比,本发明具有如下有益效果:
32、1、现有金融领域对金融实体识别较少,且存在金融领域识别识别处理中忽略大量未登陆词问题,识别不准确等问题。本发明通过爬虫爬取真实新闻文本,用表达能力强的bert作为预训练模型,学习文本的嵌入特征,通过bilstm-crf标注新闻文本的原因结果部分,能够大幅度增加原因结果识别的精确度。
33、2、在因果关系链构建的过程中,在判断结果和原因部分的相似度的时候,先提取主谓宾或者主谓,再将该部分向量化,从而排除了在将文本向量化时,形容词和副词等缺少实质意义的信息的干扰,可以提升核心信息相似度的判断精度,从而提升因果关系链的精准度。
34、3、本发明通过用过往发生的新闻事件构建金融领域的因果关系链,当某事件再次发生时,可推导出将来可能发生的演变,可用于预测经济事件的演变路径及股票预测等下游任务。
技术特征:
1.一种基于文本核心信息抽取的金融因果关系链构建方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的基于文本核心信息抽取的金融领域因果关系链构建方法,其特征在于,所述s1的具体过程为:
3.根据权利要求1所述的基于文本核心信息抽取的金融领域因果关系链构建方法,其特征在于,所述s2的具体过程为:
4.根据权利要求1所述的基于文本核心信息抽取的金融领域因果关系链构建方法,其特征在于,所述s3的具体过程为:
5.根据权利要求1所述的基于文本核心信息抽取的金融领域因果关系链构建方法,其特征在于,所述s4的具体过程为:
6.根据权利要求所5述的基于文本核心信息抽取的金融领域因果关系链构建方法,其特征在于,所述s402的具体过程为:
技术总结
本发明公开了一种基于文本核心信息抽取的金融因果关系链构建方法,属于自然语言处理的信息抽取领域。具体方法包括:步骤1,爬取金融新闻数据,并对新闻文本进行分句,构建数据集;步骤2,用BERT分类模型对步骤1得到的文本进行因果关系二分类;步骤3,将步骤2得到的具有因果关系文本送入BERT模型进行预训练后,送入BiLSTM‑CRF模型中进行BIO序列标注,构建BERT‑BiLSTM‑CRF模型;步骤4,对步骤3得到的文本抽取主谓宾或主谓得到核心信息,然后用Sentence‑BERT将该部分量化,通过语义相似度构建因果关系链。本发明用抽取主谓宾或主谓获取核心信息,再将其向量化,消除了形容词和副词等缺少实质意义的信息的干扰,可以提升核心信息相似度的判断精度,从而提升因果关系链的精准度。
技术研发人员:孙晓梅,许韬,杨江
受保护的技术使用者:江苏科技大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!