一种用于会计底稿录入的OCR识别的方法与流程
本发明属于ocr识别领域,特别涉及一种用于会计底稿录入的ocr识别的方法。
背景技术:
1、传统的业务票据识别主要是以人工方式进行,财务相关人员依照票据内容手动将票据内容输入excel等文件或者数据库之中。这种方式的坏处是工作量大,容易出错,并且重复性高,当企业的业务量增大,票据种类,数据增多的时候话费的人力成本是巨大的,特别是在财务领域,对票据内容,特别是与金额相关的要素信息要求准确率很高。于是在这种场景下提出了利用计算机图像识别软件与传统财务云平台整合的思路,将人工识别票据内容交由计算机图像识别软件来完成。从而节省人力成本,与此同时,由于计算机识别的速度远远高于人工,由此财务数据响应更快。
2、现代工业、商业、日常经济活动的繁荣,促使人们频繁适用发票等财务票据,而常规手动管理财务票据费时费力。在现实财务处理发票数据工作中,越来越多的发票需要整理,越来越多的时间耗费在发票上,手动录入和人工检索,不仅浪费时间,且容易出错。随着信息技术的发展,这项工作大多交由计算机完成,因此借助信息化手段,提高财务票据信息处理能力、处理效率、准确率,实现财务票据自动识别是解决问题的有效途径。
3、传统的ocr光学字符识别技术主要是为提高人机在处理信息时,人类效率明显落后于机器的矛盾,使人机之间的信息交流高速且有效。ocr技术出现后,随着技术的不断更新与发展,ocr技术在人类经济活动与日常生活中的各个领域开始崭露头角发挥作用,目前也已经有了较成熟的技术方案。ocr字符识别属于模式识别,在字符定位、字符切分以及提取方面都有了较深入的研究。现如今,单个字符的识别精确度已经很高。但是对于字符比划简单的阿拉伯数字,由于字符差异小、字符形状相似而识别精度较差。财务票据中多包涵汉语、数字多种形式结合的文本,传统ocr对于此类文本的识别繁琐且精准度较差,效果有待提高。且效果对于财务票据本身的影像要求比较严格,无法适用于业务经营活动中各种场景下的财务票据识别。
4、目前,会计电子档案是指以磁性介质形式储存的会计核算的专业材料,是记录和反映经济业务的重要历史资料和证据。它包括电子凭证、电子账簿、电子报表、其他电子会计核算资料等。
5、在录入时会计电子档案需要人工进行录入,会计科目很多,极其容易产生错录会计科目的情况发生,现今为了简单方便只是将原始凭证上的数据进行录入,在使用时不能查看原始凭证,不能确保数据的准确,必要的时候还是要查看原始凭证。因此,现在亟需一种用于会计底稿录入的ocr识别的方法。
技术实现思路
1、本发明提出一种用于会计底稿录入的ocr识别的方法,解决了现有技术中在进行会计底稿录入时,通过ocr识别会出现数字或者字符误差需要人工校正,而没有一个完整的识别方法来减少人工参与的程度,导致工作效率不高的问题。
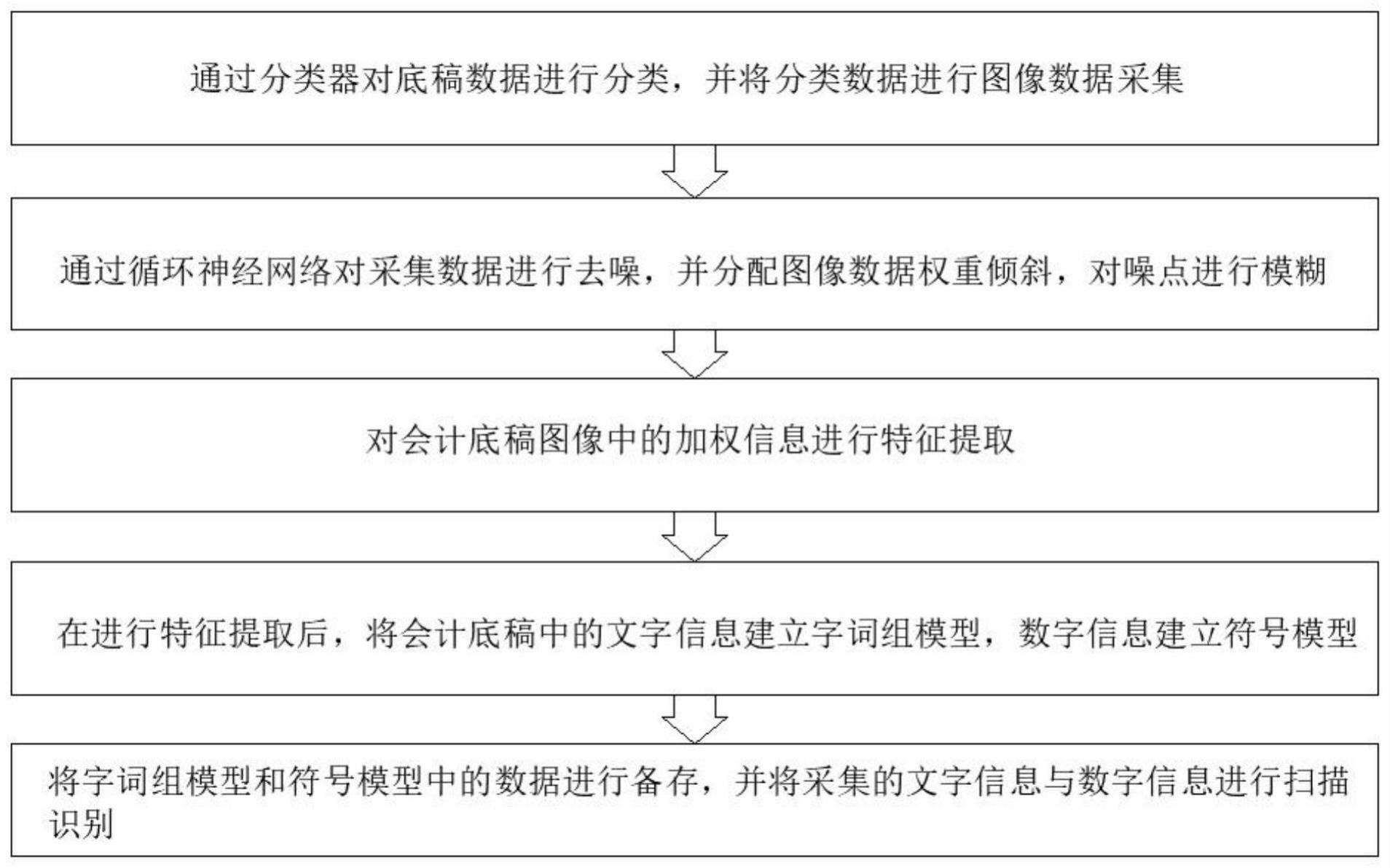
2、本发明的技术方案是这样实现的:一种用于会计底稿录入的ocr识别的方法,所述方法包括如下步骤:通过分类器对底稿数据进行分类,并将分类数据进行图像数据采集;通过循环神经网络对采集数据进行去噪,并分配图像数据权重倾斜,对噪点进行模糊;对会计底稿图像中的加权信息进行特征提取:在进行特征提取后,将会计底稿中的文字信息建立字词组模型,数字信息建立符号模型;将字词组模型和符号模型中的数据进行备存,并将采集的文字信息与数字信息进行扫描识别。
3、目前在录入会计底稿中的数字和文本时,困难主要体现在以下几个方面:1.文字变形:由于会计底稿中的文字可能存在变形的情况,导致录入的结果不准确。2.字符模糊:由于会计底稿中的字符可能存在模糊等问题,导致录入不准确。3.字符倾斜:由于会计底稿中的字符可能存在倾斜等问题,导致录入不准确。4.文本格式:由于会计底稿中的文本可能存在格式不统一等问题,导致录入不准确。针对上述困难,本申请文件采用的措施解决方案为:1.使用ocr识别软件进行ocr识别,以提取会计底稿中的文本信息。2.使用字符识别软件进行字符识别,以提取会计底稿中的数字信息。3.使用ocr识别软件配合使用,以提高录入效率。4.使用文本转换软件将会计底稿中的文本转换为统一的格式,以提高录入准确性。
4、作为一优选的实施方式,所述分类器采用机器学习算法进行分类,首先通过分析会计底稿样本的特征,根据样本的特征,对样本进行评估,计算样本的分类结果,确定归属于对应类别。
5、作为一优选的实施方式,所述循环神经网络通过对序列数据进行训练,获取训练数据模型,通过训练数据模型建构会计底稿标准化数据库,通过标准化数据库与采集数据进行对比获取区别特征点。
6、作为一优选的实施方式,在获取区别特征点后,对该特征点图像数据进行权重倾斜,对图像数据中的噪点进行模糊后,将模糊噪点去除。
7、作为一优选的实施方式,所述字词组模型利用标准化数据库对用户输入的字词组模型进行分析,得到字词组模型中字符分布的匹配概率,根据匹配对字词组模型中文本进行筛选,判断字词组模型中文本字符是否为错别字,并根据匹配概率确定前后词组正确率。
8、采用了上述技术方案后,本发明的有益效果是:准确性高,采用orc录入技术,可以有效避免因文字变形、模糊、倾斜等问题导致的录入错误,效率高,可以快速、高效地完成录入任务,减少手工录入的时间和精力;安全性高,可以确保输入的准确性,防止出现误读等问题。适应性强,根据不同的文字情况和输入需求,进行灵活的调整和适应。提高工作效率和准确性,减少人工录入的时间和精力,同时也有利于提高工作质量和可靠性。
技术特征:
1.一种用于会计底稿录入的ocr识别的方法,其特征在于,所述方法包括如下步骤:
2.如权利要求1所述的一种用于会计底稿录入的ocr识别的方法,其特征在于:所述分类器采用机器学习算法进行分类,首先通过分析会计底稿样本的特征,根据样本的特征,对样本进行评估,计算样本的分类结果,确定归属于对应类别。
3.如权利要求1所述的一种用于会计底稿录入的ocr识别的方法,其特征在于:所述循环神经网络通过对序列数据进行训练,获取训练数据模型,通过训练数据模型建构会计底稿标准化数据库,通过标准化数据库与采集数据进行对比获取区别特征点。
4.如权利要求3所述的一种用于会计底稿录入的ocr识别的方法,其特征在于:在获取区别特征点后,对该特征点图像数据进行权重倾斜,对图像数据中的噪点进行模糊后,将模糊噪点去除。
5.如权利要求3所述的一种用于会计底稿录入的ocr识别的方法,其特征在于:所述字词组模型利用标准化数据库对用户输入的字词组模型进行分析,得到字词组模型中字符分布的匹配概率,根据匹配对字词组模型中文本进行筛选,判断字词组模型中文本字符是否为错别字,并根据匹配概率确定前后词组正确率。
技术总结
本发明提出了一种用于会计底稿录入的OCR识别的方法,所述方法包括如下步骤:通过分类器对底稿数据进行分类,并将分类数据进行图像数据采集;通过循环神经网络对采集数据进行去噪,并分配图像数据权重倾斜,对噪点进行模糊;对会计底稿图像中的加权信息进行特征提取:在进行特征提取后,将会计底稿中的文字信息建立字词组模型,数字信息建立符号模型;将字词组模型和符号模型中的数据进行备存,并将采集的文字信息与数字信息进行扫描识别。目前在录入会计底稿中的数字和文本时,困难主要体现在以下几个方面,文字变形,由于会计底稿中的文字可能存在变形的情况,导致录入的结果不准确。字符模糊,由于会计底稿中的字符可能存在模糊等问题。
技术研发人员:权博,王辉辉,卫兵兵,张芳,石磊
受保护的技术使用者:陕西联兴网络科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!