基于特征构建和特征选择的火电机组煤耗智能预测方法
本申请涉及数据挖掘领域,尤其是基于特征构建和特征选择的火电机组煤耗智能预测方法。
背景技术:
1、以水电、风电和太阳能发电等为代表的清洁能源具有显著的间歇性和不确定性的特点,其发电量易受气候、季节和时段等因素的影响。
2、为了尽量充分利用清洁能源,提高清洁能源占比,规避大规模“弃风、弃水和弃光”现象的发生,需要在电力市场辅助服务机制的帮助下,以火电作为辅助和备用能源来提升电网整体的稳定性;当清洁能源供给量充足时降低火力发电量,当清洁能源供给量不足时增加火力发电量,火电由现在的基础电力来源角色转变为清洁能源发电的动态补充电力。也就是在电力系统中,火电需要在电网调峰为可再生能源的接入提供了必要的基础和保障。
3、这意味着火电的角色将从过去的稳定运行以提供电力负载中的基荷转变为快速调节以应对电力负载中的峰荷,这种火力发电运营模的重大改变给火电机组运营优化与机组调度带来了新的挑战。如何在电网调峰条件下实现高效运行、节能减排是火电企业必须解决的一个管理问题。建立准确有效的火电机组煤耗预测模型是实现上述目标需要解决的最根本问题之一。
4、近年来,包括分布式控制系统、监控信息系统、工厂信息系统和现场总线控制系统在内的智能管理部署越来越受到火电企业的关注。这些系统使火电企业能够记录火电机组的实时运行状态和发电数据。基于运行数据的数据驱动技术经常被用于火力发电厂各个领域的建模和分析,如燃煤发电机组的故障诊断、燃煤发电机组基准区间的确定,以及为操作员优化汽轮机系统自变量参考值。与传统的基于机构的建模相比,数据驱动方法具有更大的通用性和准确性。
5、然而,很少有研究关注火电机组的煤耗预测。经检索,文献中最接近的研究是提出了一项关于最小二乘支持向量机理论在预测煤耗方面的研究(zhang l.,zhou l.,&zhangy.et al.coal consumption prediction based on least squares support vectormachine[c].iop conference series:earth and environmental science,2019,227(3),032007)。而在煤耗预测模型的指标选择方面,他们直接基于领域知识制定了20个特征,这种基于经验的特征分配错过了找到更好的特征子集来建立煤耗预测模式的可能性。
6、从火电厂的原始运行数据中获取最优关键特征集的问题通常具有高维、复杂非线性和强耦合性,大量特征导致模型构建过程中出现错误,并显著增加预测模型的计算成本。因此,识别关键特征以用作预测模型的输入变量是至关重要的。发现特征之间缺失的关系并构建可能更好的特征是一个被称为特征构建的过程,这也可能导致创建许多不必要的特征。一种经常用来解决这个问题的方法是特征选择,它包括选择重要特征和消除不重要的特征。通过降低时间复杂性、提高准确性和降低过拟合风险,特征选择可以增强机器学习预测模型。
7、综上所述,现有研究方法并不能充分利用火电机组数据并准确预测火电机组的煤耗水平,因此针对上述问题提出一种基于特征构建和特征选择的火电机组煤耗智能预测方法。
技术实现思路
1、在本实施例中提供了基于特征构建和特征选择的火电机组煤耗智能预测方法,经过计算得到火电机组的预测煤耗,其具有客观公正、准确易行的特点。
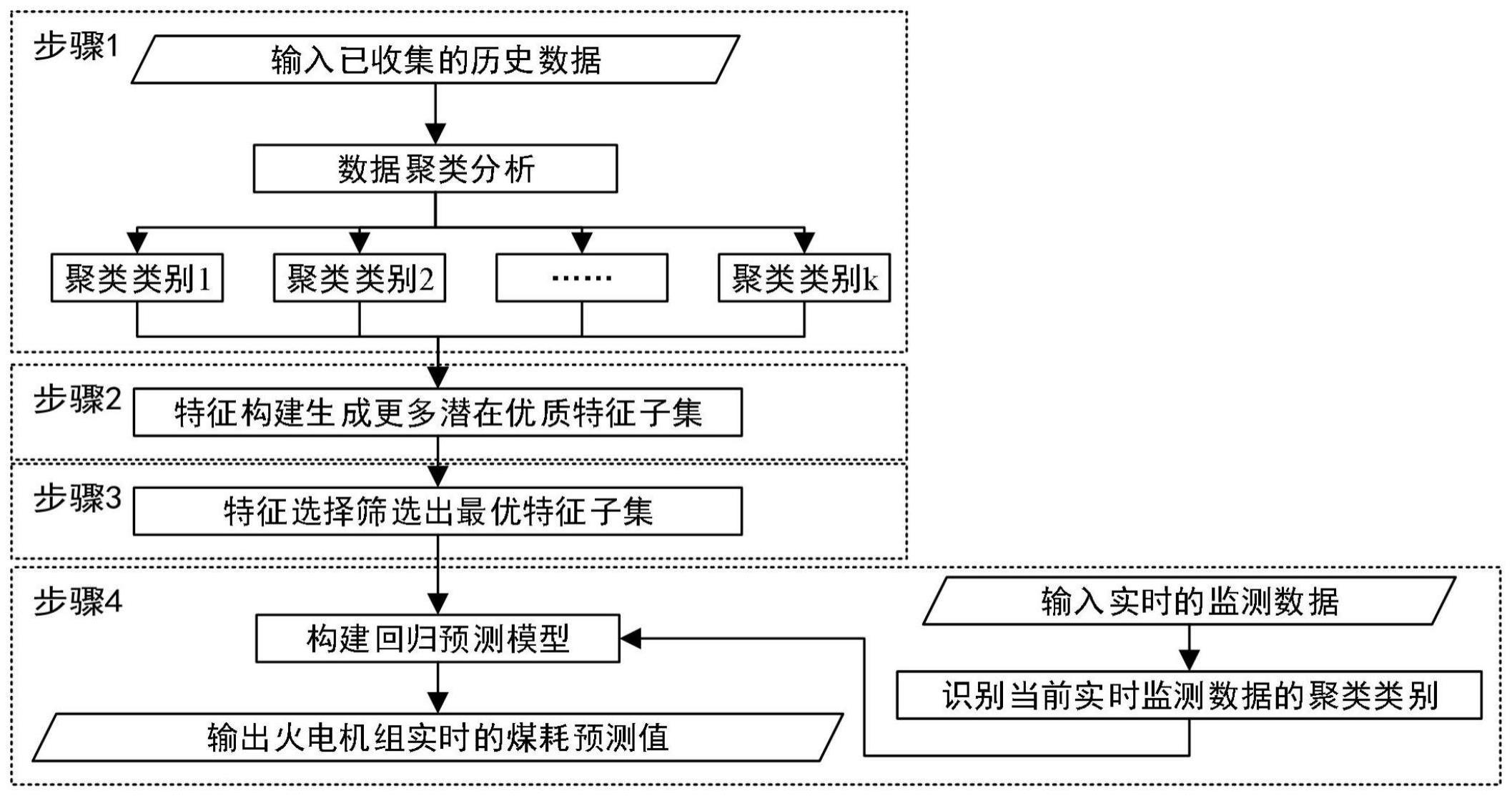
2、根据本申请的一个方面,提供了基于特征构建和特征选择的火电机组煤耗智能预测方法,所述智能预测方法包括如下步骤:
3、步骤一、对于通过安装在火电机组上的传感器所收集到的历史监控数据x=(x1,...,xd),使用k-means算法进行聚类分析以划分不同的火电机组基本工况,其中xj=(x1,j,…,xn,j)t是表示x中第j个特征的列向量,xi,j是第j个特征的第i个样本,y=(y1,...,yn)t是与监控数据x对应的火电机组煤耗,其中yi表示第i个样本的煤耗值,i=1,2,...,n,j=1,2,...,d,n是样本总数,d是特征总数;
4、首先,将聚类数量设置为k,然后随机选择k个观测值作为初始聚类中心;其次,在测量每个观测点与每个聚类中心之间的距离后,指定最接近每个观测点的聚类;然后,重新计算现在每个类别的聚类中心并更新聚类中心结果;重复该过程,直到迭代次数达到预定阈值m;
5、对于不同的聚类数量k的取值,使用轮廓系数来评估最理想的聚类数量;计算所有不同的聚类数量k所对应的轮廓系数,选取其中轮廓系数最大的所对应的聚类数目作为最终的聚类数;
6、步骤二、火电机组系统中各种特征的记录数据来自放置在各种系统位置的各种传感器;然而,这些特征的测量值可能不会立即获得,这意味着在不同的参数内以及在特征和相应的煤耗之间可能存在相应的延迟或提前时间;因此,为了创建一个准确的火电机组煤耗智能预测模型,我们使用特征构建来反映这种延迟或提前时间现象;
7、每个特征的记录数据都是一个时间序列,我们每次考虑一个时间间隔来刻画每个特征一个时间点的延迟或提前效应;我们分别考虑总共l的延迟或提前时间间隔,因为每个特征可以构建出额外的2l个特征,则特征的数量从d个增加到2ld+d个;
8、步骤三、高维特征集会对回归机器学习模型产生许多不利影响,例如增加模型的时间复杂性、降低其精度以及增加过拟合风险等,我们使用遗传算法来剔除那些无意义的冗余特征以实现特征子集的提炼和精简;
9、首先进行编码,原始特征集的每个可能的子集可以表示为染色体,并且染色体中的每个基因指示相应的特征;当基因的值被赋为1时,代表这个特征子集中选择相应的特征,而当基因的值被赋为0时,则代表这个特征子集中不选择相应的特征;
10、然后根据编码规则,随机生成给定数量的染色体,形成初始群体;每个染色体都使用其均方根误差作为适应度函数进行评估;基于遗传算法的选择、交叉和变异操作,生成新的一代染色体种群;
11、重复上一步操作,直到达到指定的迭代次数m,输出最后一代种群中的最优染色体,该染色体所对应的特征子集即为特征选择的结果;
12、步骤四、通过matlab 2021b软件中的装袋树模型,使用步骤三中所筛选出的特征子集作为自变量,将煤耗作为因变量,使用5交叉验证方法,建立装袋树回归预测模型;
13、则对于后续任意的新到达的火电机组监控数据样本,将该样本带入前述建立的回归预测模型,即可得到该样本对应的火电机组煤耗预测。
14、本申请的有益之处在于:
15、本申请提供的基于特征构建和特征选择的火电机组煤耗智能预测方法,与现有技术相比,其基于特征构建和特征选择来获取潜在更优质的特征来构建回归预测模型,该回归预测模型的预测值可以准确预测火电机组的煤耗量,该方法高效准确、客观公正、且简单易行。
技术特征:
1.基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述智能预测方法包括如下步骤:
2.根据权利要求1所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述步骤一中的k-means聚类分析如下:
3.根据权利要求2所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述k-means聚类分析最后,选取其中轮廓系数最大的所对应的聚类数目作为最终的聚类数。
4.根据权利要求1所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述步骤二中的特征构建如下:
5.根据权利要求4所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述特征构建中分别考虑总共l的延迟或提前时间间隔,每个特征可以构建出额外的2l个特征。
6.根据权利要求5所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述特征的数量从d个增加到2ld+d个。
7.根据权利要求1所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述步骤三中的特征选择、提炼和精简如下:
8.根据权利要求7所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述最优染色体所对应的特征子集即为特征选择的结果。
9.根据权利要求1所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述步骤四中的回归预测模型如下:
10.根据权利要求9所述的基于特征构建和特征选择的火电机组煤耗智能预测方法,其特征在于:所述装袋树模型通过matlab 2021b软件提供。
技术总结
本申请公开了基于特征构建和特征选择的火电机组煤耗智能预测方法,所述步骤如下:通过传感器收集火电机组历史监控数据,使用K‑means算法进行聚类分析以划分不同的火电机组基本工况;使用特征构建来反映这种延迟或提前时间现象,以期得到更多的潜在优质子集;使用遗传算法剔除无意义的冗余特征以实现特征子集的提炼和精简;使用上述筛选出的特征子集作为自变量煤耗作为因变量建立装袋树回归预测模型,对于后续的实时监测数据通过该回归预测模型实时预测火电机组的煤耗。本申请提出的智能预测方法,高效准确且简单易行。
技术研发人员:朱磊,章魏,周健,张丽忠,刘永平
受保护的技术使用者:北京航空航天大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!