模型评估方法、装置、终端及存储介质与流程
本申请涉及计算机,具体而言,涉及一种模型评估方法、装置、终端及存储介质。
背景技术:
1、在很多应用场景下,如音乐推荐场景下需要使用实验模型来预测所要推荐的歌曲。因此,评估实验模型是否可以使用,也就是有没有必要上线十分重要。
2、目前,一般通过线上环境来评估实验模型和基线模型的差异性,进而判断实验模型是否有必要上线。具体的,先将实验模型和基线模型上线,然后分别给实验模型和基线模型分配一股真实的线上流量进行预测,再将实验模型和基线模型预测后的结果进行比较,并根据比较结果来判断实验模型是否有必要上线。
3、但是,上述方法不仅需要采用真实的线上流量,还需要完整的实验上线流程以及等待用户的反馈结果,导致评估实验模型和基线模型的差异性周期长。
技术实现思路
1、本申请的主要目的在于提供一种模型评估方法、装置、终端及存储介质,以解决相关技术中评估实验模型和基线模型的差异性周期长的问题。
2、为了实现上述目的,第一方面,本申请提供了一种模型评估方法,包括:
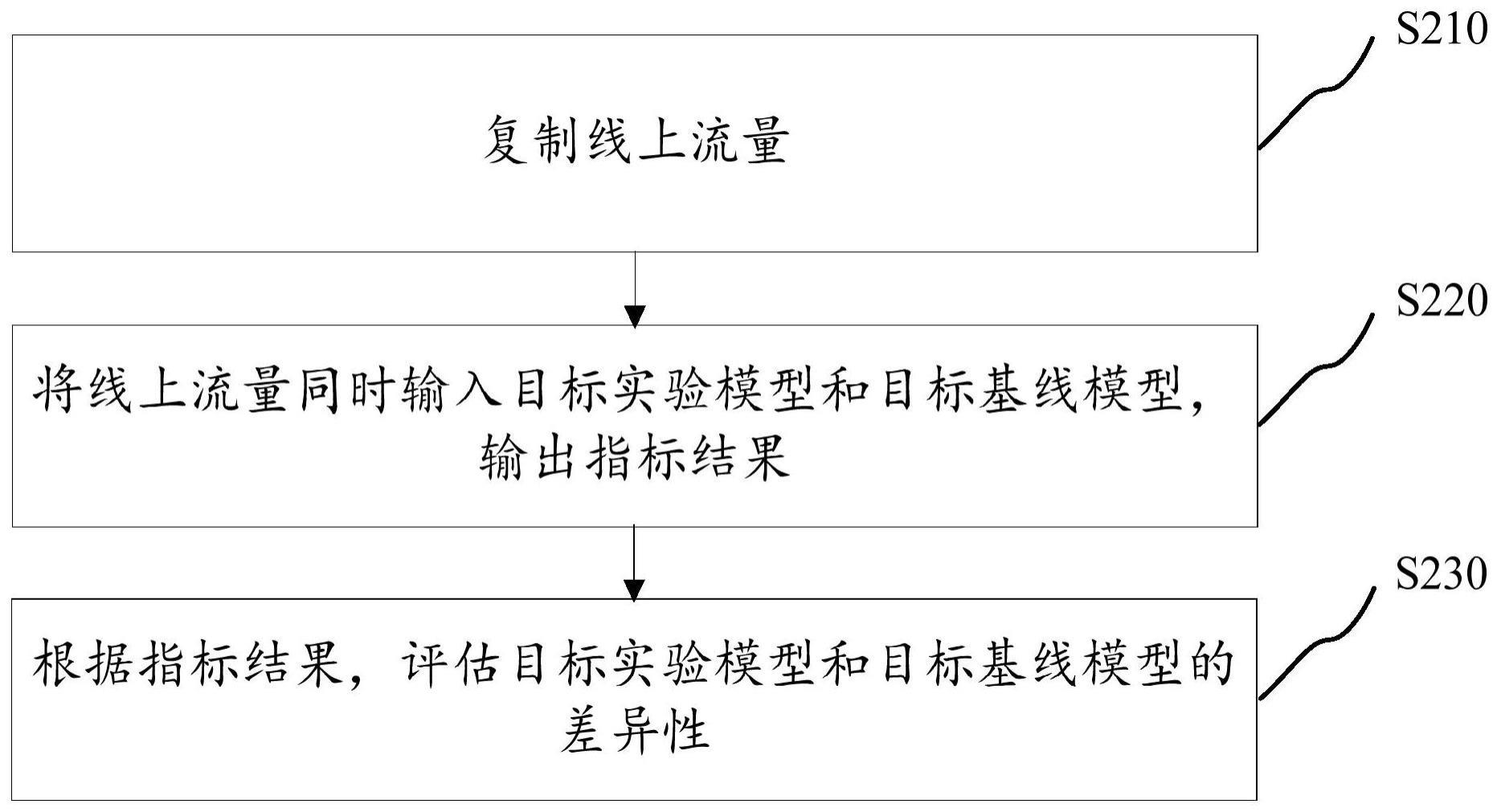
3、复制线上流量;
4、将线上流量同时输入目标实验模型和目标基线模型,输出指标结果,其中,目标实验模型和目标基线模型均设置于旁路环境中;
5、根据指标结果,评估目标实验模型和目标基线模型的差异性。
6、在一种可能的实现方式中,根据指标结果,评估目标实验模型和目标基线模型的差异性,包括:
7、对指标数据进行处理,得到指标数据对应的输出数据;
8、基于输出数据和预设条件,评估目标实验模型和目标基线模型的差异性。
9、在一种可能的实现方式中,对指标数据进行处理,得到指标数据对应的输出数据,包括:
10、利用flink任务对指标数据进行展开处理,得到指标数据对应的数据表;
11、利用spark任务对数据表中的数据进行配置、计算处理,得到输出数据。
12、在一种可能的实现方式中,利用flink任务对指标数据进行展开处理,得到指标数据对应的数据表,包括:
13、读取指标结果;
14、对指标结果按照字段维度展开,形成指标结果对应的数据表。
15、在一种可能的实现方式中,利用spark任务对数据表中的数据进行配置、计算处理,得到输出数据,包括:
16、提取配置文件;
17、读取数据表中的数据,并利用配置文件中的输入配置对数据表中数据进行配置,得到输入数据;
18、利用配置文件中的策略算子的计算方式对输入数据进行计算处理,得到输出数据。
19、在一种可能的实现方式中,利用配置文件中的策略算子的计算方式对输入数据进行计算处理,得到输出数据,包括:
20、在策略算子的计算方式为混淆矩阵的情况下,将输入数据中的目标实验模型和目标基线模型的打分结果分别按照用户粒度进行倒序排列,得到目标实验模型对应的第一序列和目标基线模型对应的第二序列;
21、将目标实验模型对应的第一序列和目标基线模型对应的第二序列中的打分结果与标识进行关联拼接,得到目标实验模型对应的第三序列和目标基线模型对应的第四序列,其中,标识至少包括用户标识、请求标识、资源标识;
22、将第三序列和第四序列按照行号进行排列,得到输出数据,其中,输出数据为n行n列的混淆矩阵,其中,n为大于2的整数。
23、在一种可能的实现方式中,基于输出数据和预设条件,评估目标实验模型和目标基线模型的差异性,包括:
24、以混淆矩阵中的任一对角点作为起始点提取目标矩阵,其中,目标矩阵为m行m列矩阵,m为小于等于n的整数;
25、若目标矩阵中对角线上的数字满足预设条件,目标实验模型和目标基线模型的差异性小。
26、在一种可能的实现方式中,若目标矩阵中对角线上的数字满足预设条件,目标实验模型和目标基线模型的差异性小,包括:
27、获取目标矩阵中对角线的数字;
28、若对角线上的数字中大于预设阈值的数字的数目大于等于预设数目,目标实验模型和目标基线模型的差异性小。
29、在一种可能的实现方式中,复制线上流量,包括:
30、接收配置参数,其中,配置参数中至少包括采样参数;
31、利用采样参数复制线上流量至旁路环境。
32、在一种可能的实现方式中,配置参数还包括模型参数和打分进程参数;
33、复制线上流量之前,还包括:
34、利用模型参数构建初始实验模型和初始基线模型,以及利用打分进程参数构建打分程序;
35、利用k8s容器化方式部署打分程序,并将打分程序载入初始实验模型和初始基线模型中,得到目标实验模型和目标基线模型;
36、基于目标实验模型和目标基线模型,搭建旁路环境。
37、在一种可能的实现方式中,将线上流量同时输入目标实验模型和目标基线模型,输出指标结果之后,还包括:
38、将指标结果存储至kafka中。
39、在一种可能的实现方式中,利用配置文件中的策略算子的计算方式对输入数据进行计算处理,得到输出数据之后,还包括:
40、利用配置文件中的输出配置将输出数据写入数据库引擎。
41、第二方面,本发明实施例提供了一种模型评估装置,包括:
42、复制模块,用于复制线上流量;
43、预测模块,用于将线上流量同时输入目标实验模型和目标基线模型,输出指标结果,其中,目标实验模型和目标基线模型均设置于旁路环境中;
44、评估模块,用于根据指标结果,评估目标实验模型和目标基线模型的差异性。
45、第三方面,本发明实施例提供了一种终端,包括存储器、处理器以及存储在存储器中并可在处理器上运行的计算机程序,处理器执行计算机程序时实现如上任一种模型评估方法的步骤。
46、第四方面,本发明实施例提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现如上任一种模型评估方法的步骤。
47、本发明实施例提供了一种模型评估方法、装置、终端及存储介质,包括:复制线上流量,然后将线上流量同时输入目标实验模型和目标基线模型,输出指标结果,其中,目标实验模型和目标基线模型均设置于旁路环境中,再根据指标结果,评估目标实验模型和目标基线模型的差异性。本发明直接复制线上流量,无需采用真实的线上流量,降低了线上流量的损耗,此外,将目标实验模型和目标基线模型均设置于旁路环境中,不需要完整的上线流程以及等待用户的反馈结果,降低了评估目标实验模型和目标基线模型的差异性的周期,提高了评估效率。
技术特征:
1.一种模型评估方法,其特征在于,包括:
2.如权利要求1所述模型评估方法,其特征在于,所述根据所述指标结果,评估所述目标实验模型和目标基线模型的差异性,包括:
3.如权利要求2所述模型评估方法,其特征在于,所述对所述指标数据进行处理,得到所述指标数据对应的输出数据,包括:
4.如权利要求3所述模型评估方法,其特征在于,所述利用flink任务对所述指标数据进行展开处理,得到所述指标数据对应的数据表,包括:
5.如权利要求3所述模型评估方法,其特征在于,所述利用spark任务对所述数据表中的数据进行配置、计算处理,得到所述输出数据,包括:
6.如权利要求5所述模型评估方法,其特征在于,所述利用所述配置文件中的策略算子的计算方式对所述输入数据进行计算处理,得到所述输出数据,包括:
7.如权利要求6所述模型评估方法,其特征在于,所述基于所述输出数据和预设条件,评估所述目标实验模型和目标基线模型的差异性,包括:
8.一种模型评估装置,其特征在于,包括:
9.一种终端,其特征在于,包括存储器,以及与所述存储器通信连接的一个或多个处理器;
10.一种计算机可读存储介质,其特征在于,包括程序或指令,当所述程序或指令在计算机上运行时,实现权利要求1至7中任一项所述的模型评估方法。
技术总结
本申请公开了一种模型评估方法、装置、终端及存储介质,方法包括:复制线上流量;将线上流量同时输入目标实验模型和目标基线模型,输出指标结果,其中,目标实验模型和目标基线模型均设置于旁路环境中;根据指标结果,评估目标实验模型和目标基线模型的差异性。本发明直接复制线上流量,无需采用真实的线上流量,降低了线上流量的损耗,此外,将目标实验模型和目标基线模型均设置于旁路环境中,不需要完整的上线流程以及等待用户的反馈结果,降低了评估目标实验模型和目标基线模型的差异性的周期,提高了评估效率。
技术研发人员:陈赢,李雪冬,黄崛,谭钧心,骆庚,吴官林
受保护的技术使用者:杭州网易云音乐科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!