一种计算机视觉的语义分割对抗性训练方法
本发明涉及对抗性训练方法,尤其涉及一种计算机视觉的语义分割对抗性训练方法。
背景技术:
1、对抗性训练方法,是一种选取对应样本进行对抗性预训练,以此夹块下有任务训练的方法,在现有对抗性训练方法中,代理任务通常为分类任务,直接迁移backbone到分割这样的密集任务会导致task gap,且训练往往采用分割模型的decoder,decoder采用随机初始化方式,会导致architectural gap情况发生,需要进行改进。
技术实现思路
1、本发明的目的是解决现有技术中存在的缺点,而提出的一种计算机视觉的语义分割对抗性训练方法。
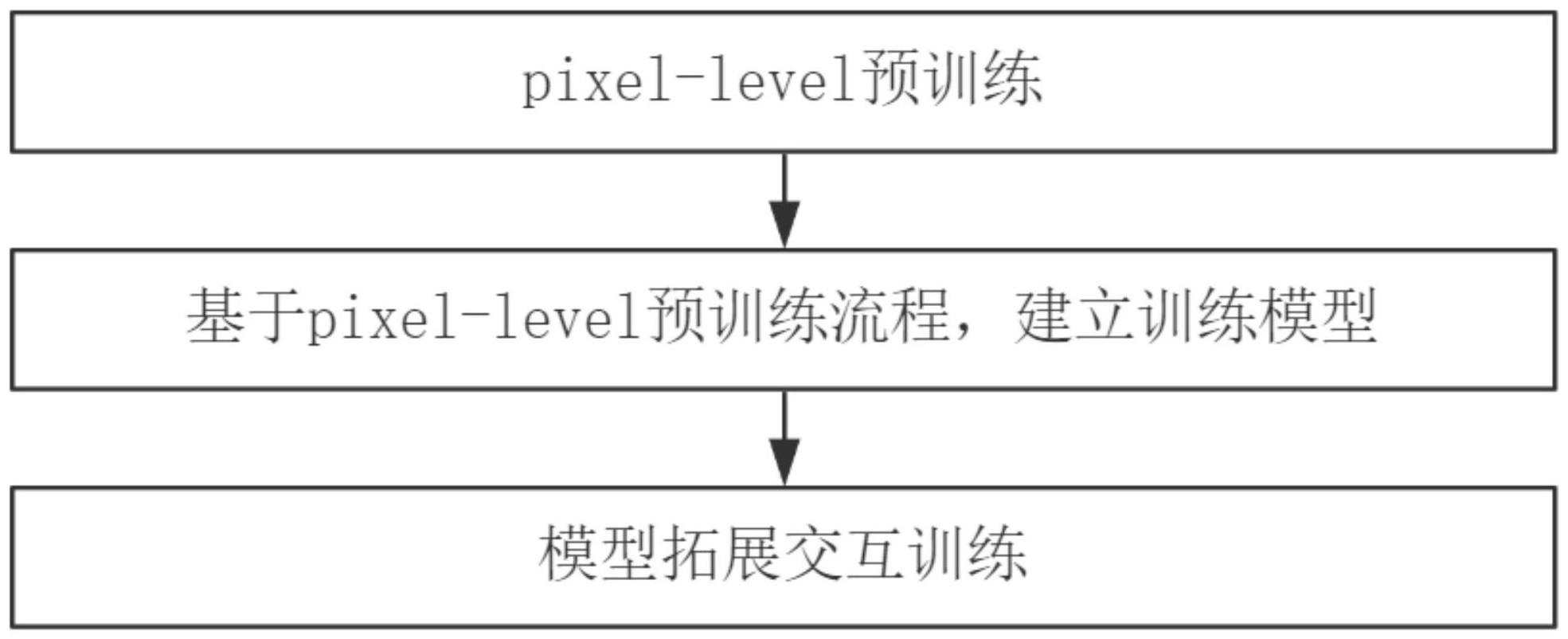
2、为了实现上述目的,本发明采用了如下技术方案:一种计算机视觉的语义分割对抗性训练方法,包括以下步骤:
3、s1:pixel-level预训练;
4、s2:基于pixel-level预训练流程,建立训练模型;
5、s3:模型拓展交互训练。
6、作为本发明的进一步方案,所述s1中,所述pixel-level的预训练的步骤具体为:
7、s110:图像裁剪训练;
8、s120:比对像素致密对比损耗和实例对比损失,并将样本导入屏蔽池。
9、作为本发明的进一步方案,所述s110中,所述图像裁剪训练的步骤具体为:
10、s111:将单张参与训练图片的两组任意位置进行裁剪截取,获取第一截图与第二截图;
11、s112:选取两张任意图片作为背景图;
12、s113:将s111裁剪截取第一截图与第二截图作为前景图,分别粘贴至两组背景图上。
13、作为本发明的进一步方案,所述s120中,所述比对像素致密对比损耗和实例对比损失,并将样本导入屏蔽池的步骤具体为:
14、s121:引入查询编码器和键编码器,并通过查询编码器更新键编码器;
15、s122:将s113中,第一截图的粘贴结果作为样本一,第二截图的粘贴结果作为样本二;
16、s123:查询比对样本一和样本二的像素致密对比损耗;
17、s124:将样本一与样本二引入屏蔽池;
18、s125:在屏蔽池中查询比对样本一和样本二的实例对比损失。
19、作为本发明的进一步方案,所述s123中,所述像素致密对比损耗的比对公式采用:
20、
21、其中,e为像素致密对比损耗记录结果,e1为单位时间内的总能耗,w1为单位时间内样本一和样本二成型总质量。
22、作为本发明的进一步方案,所述s125中,所述实例对比损失采用对比损失函数,具体是通过随机的数据增强模块在s111执行过程中,将执行结果作为增强图像,并基于查询编码器和键编码器提取增强图像对应的样本一和样本二,投影头使用一组小的辅助网络表示进行进一步的变换,基于实例映射函数从投影帧产生实例,对比损失函数将正样本表示结果尽可能接近以及确保与负样本的差异。
23、作为本发明的进一步方案,所述s2中,所述建立训练模型的步骤具体为:
24、s210:建立模型库文件,并在模型库文件中建立训练模型;
25、s220:基于训练模型,对s1整体步骤流程进行自动化记录;
26、s230:封装s220记录项,存储训练模型文件。
27、作为本发明的进一步方案,所述s220中,所述对s1整体步骤流程进行自动化记录的步骤具体为:
28、s221:在输入阶段,抽调并增强样本一和样本二;
29、s222:获取样本一的骨架和投影数据,生成x变量;
30、s223:获取样本二的动量骨架和投影数据,生成x′变量;
31、s224:记录s123中像素致密对比损耗和s125中实例对比损失;
32、s225:通过图像传输模块传输,并计算每个pixel与其他pixel的相似度,作为权重项,对变换后的x变量加权求和,获得y变量,生成y变量与x′变量的consistency约束。
33、作为本发明的进一步方案,所述s3中,所述模型拓展交互训练的步骤具体为:
34、s310:基于s2所获取训练模型文件,引入另一组参与训练图片;
35、s320:以当前参与训练图片在另一视角下的相同pixel作为正样本;
36、s330:以另一组参与训练图片中任意选取pixel作为负样本;
37、s340:调用s120步骤比对像素致密对比损耗和实例对比损失;
38、s350:调用s220步骤,自动化记录s340步骤流程,并基于所调用训练模型文件生成新的训练模型。
39、作为本发明的进一步方案,所述s3中,所述模型拓展交互训练的步骤还包括基于所获取y变量数值比对,建立新的训练模型与所调用训练模型文件关联,即基于y变量数值浓稠度作为参照降序排列,并生成关联索引。
40、与现有技术相比,本发明的优点和积极效果在于:
41、本发明中,在图像裁剪训练的方式中,其训练过程是基于现有模型进行进一步调优处理,训练过程所消耗单位时间较少,能够有效提升运算效率,且在迁移到下游的分割任务时,基于查询编码器和键编码器确保其泛化性,无需再次设置weight decay,在训练运算过程中,计算每个pixel与其他pixel的相似度,作为权重项,对变换后的x变量加权求和,获得y变量,生成y变量与x′变量的consistency约束,并在此基础上,进行模型拓展交互训练,进一步提升模型泛化性以及训练效果。
技术特征:
1.一种计算机视觉的语义分割对抗性训练方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s1中,所述pixel-level的预训练的步骤具体为:
3.根据权利要求2所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s110中,所述图像裁剪训练的步骤具体为:
4.根据权利要求3所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s120中,所述比对像素致密对比损耗和实例对比损失,并将样本导入屏蔽池的步骤具体为:
5.根据权利要求4所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s123中,所述像素致密对比损耗的比对公式采用:
6.根据权利要求4所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s125中,所述实例对比损失采用对比损失函数,具体是通过随机的数据增强模块在s111执行过程中,将执行结果作为增强图像,并基于查询编码器和键编码器提取增强图像对应的样本一和样本二,投影头使用一组小的辅助网络表示进行进一步的变换,基于实例映射函数从投影帧产生实例,对比损失函数将正样本表示结果尽可能接近以及确保与负样本的差异。
7.根据权利要求1所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s2中,所述建立训练模型的步骤具体为:
8.根据权利要求7所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s220中,所述对s1整体步骤流程进行自动化记录的步骤具体为:
9.根据权利要求1所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s3中,所述模型拓展交互训练的步骤具体为:
10.根据权利要求1所述的计算机视觉的语义分割对抗性训练方法,其特征在于,所述s3中,所述模型拓展交互训练的步骤还包括基于所获取y变量数值比对,建立新的训练模型与所调用训练模型文件关联,即基于y变量数值浓稠度作为参照降序排列,并生成关联索引。
技术总结
本发明涉及对抗性训练方法技术领域,具体为一种计算机视觉的语义分割对抗性训练方法,包括以下步骤,S1:pixel‑level预训练;S2:基于pixel‑level预训练流程,建立训练模型;S3:模型拓展交互训练。本发明中,在图像裁剪训练方面,其训练过程是基于现有模型进行进一步调优处理,训练过程所消耗单位时间较少,能够有效提升运算效率,且在迁移到下游的分割任务时,基于查询编码器和键编码器确保其泛化性,无需再次设置weight decay,在训练运算过程中,计算每个pixel与其他pixel的相似度,作为权重项,对变换后的X变量加权求和,获得Y变量,生成Y变量与X<supgt;′</supgt;变量的consistency约束,并在此基础上,进行模型拓展交互训练,进一步提升模型泛化性以及训练效果。
技术研发人员:权龙杰,黄丹丹,刘智,高凯
受保护的技术使用者:长春理工大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!