基于深度学习及人工蜂群的古籍文本实体抽取方法
本发明涉及实体抽取,尤其涉及基于深度学习及人工蜂群的古籍文本实体抽取方法。
背景技术:
1、为了从文本中提取有效的信息,通常需要提取词汇表中的实体关系。现阶段,实体关系提取主要由三种类型组成:一种是自动提取,主要是无人参与提取,自动提取文本,通常没有定义的关系名称、词汇表或短语,可以通过语法或语义结构描述对应的关系,这种提取方法仍然取决于主体的质量,还需要手动过滤低频实体文本,很少使用;第二种类型:文本关系分类以监督为主,因此文本关系绘制被视为一项分类任务。预定义并手动标记有限数量的关系标签,然后使用分类模型来形成图形关系。这种方法过于依赖于标记材料的质量和数量。事实上,只有少量的标记材料可用,能够对实体关系进行分类的分类模型是有限的,被分类的实体的关系自然是有限的;第三种方法是基于远程监控的实体关系提取方法。主要是将大量未标记的语料库与由大量实体对和实体关系组成的知识库对齐,以确定未命名语料库中的实体关系。然而,目前知识基础非常不足,导致实体在抽取训练时不够充分,反过来影响到整个实体关系提取模型的性能。
2、中医典籍是中医知识的重要来源,从中医典籍中抽取知识是中医知识图谱规模化和知识全面化的必然要求,而上述的实体关系提取方法对于中医典籍的应用十分匮乏,无法识别典籍中的生僻字、生僻词,其文法与语法与现代汉语不同,而且不同的典籍对于中医医治内容的描述也不尽相同,导致在进行中医典籍的基于远程监控的实体关系抽取时,需要手动进行语料库的添加,以达到实体与实体对之间的匹配,耗时费力,且准确性较差。为此,我们提出了基于深度学习及人工蜂群的古籍文本实体抽取方法。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺点,而提出的基于深度学习及人工蜂群的古籍文本实体抽取方法,通过知识图谱自动化构建中的实体抽取模型,采用深度学习方法,在以字为基本输入元素的基础上提出基于bilstm-crf的序列标注模型,实现对古籍文本实体的准确抽取,降低相关领域专家的投入,提升古籍对应的知识图谱的快速构建。
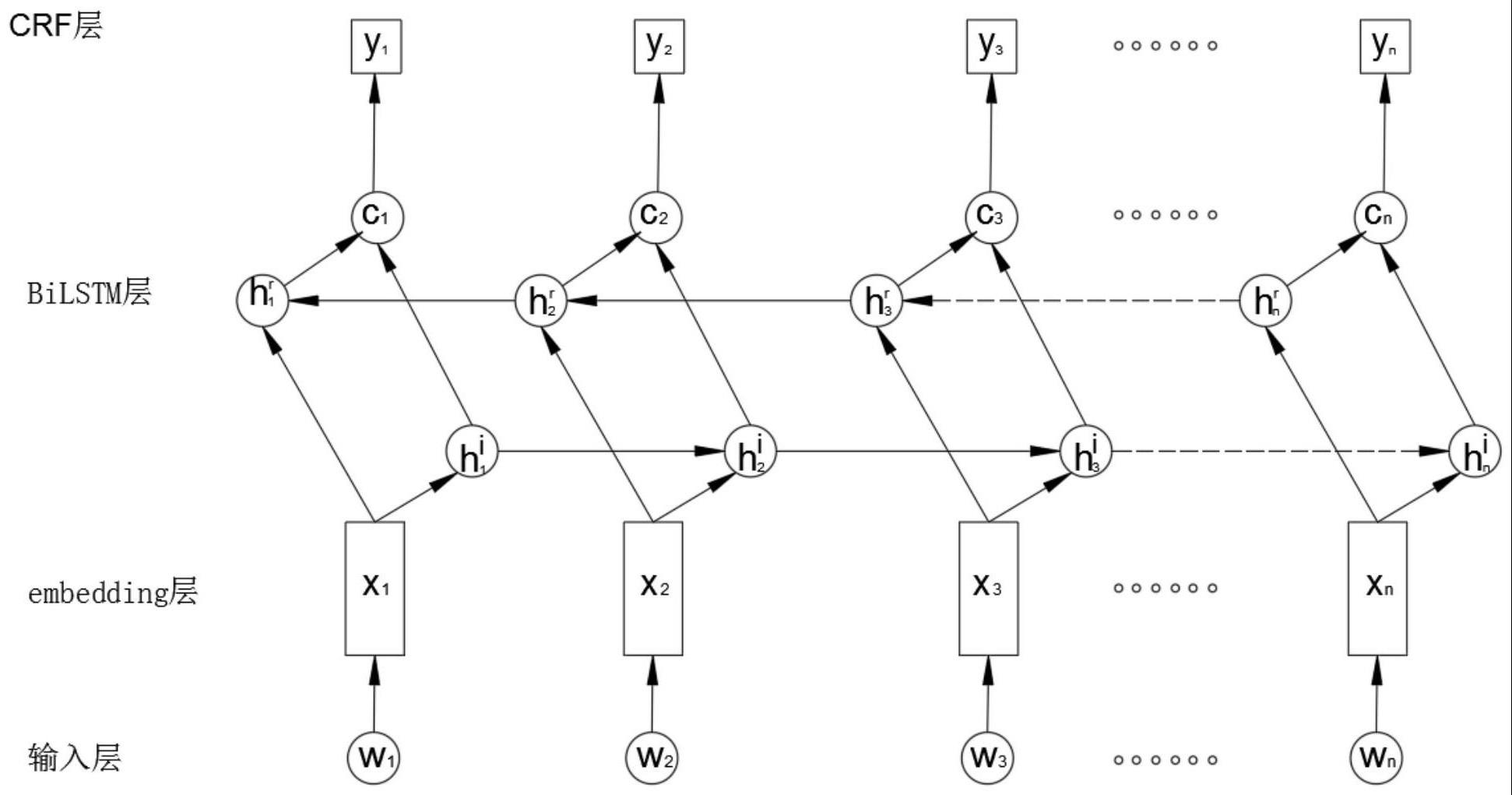
2、为达到以上目的,本发明采用的技术方案为:基于深度学习及人工蜂群的古籍文本实体抽取方法,包括输入层、embedding层、bilstm层以及crf层;具体的,以中文汉字的序列作为初始输入文本,通过输入层完成输入,随即通过embedding层将输入层输入的字序列中各个字映射为相应的向量,再通过bilstm层的双向结构对当前位置进行标注时结合上下文的信息,得到当前字的上下文表征向量;
3、最后通过crf层,根据上下文表征向量序列得到标注序列;
4、对于bilstm层的双向结构输出的结果,通过全连接层,将其转换为nxk的矩阵p,其中k为目标标签的种类数量,pi,j为第i个字标记为第j个标签的得分,对于给定预测序列y,其得分为:
5、
6、其中a为条件随机场的状态转移矩阵,是k+2阶的方阵,ai,j表示从标签i转移到标签j的得分;
7、接入softmax层实现归一处理,对于序列y,其概率为:
8、p(y│x)=es(x,y)/∑εyxes(x,);
9、在训练阶段,对于x的正确标注序列t=(t1,t2,…,tn),用梯度下降算法最大化log计算:
10、log(p(y|x))=s(x,y)-log(∑εyxesx,))=s(x,y)-log∑εyxs(x,),
11、在预测阶段,预测结果记为y*:
12、y*=argmax(s(x,))εyx。
13、优选的,其中,embedding层使用word2vec训练的字向量初始化参数,在模型训练时进行参数微调。
14、优选的,训练语料采用典籍与最新中文文章拼接而成的,并通过opencc软件完成繁转简。
15、优选的,对于初始输入的字序列,由预训练得到词向量,从而作为embedding层的输入参数。
16、优选的,其中训练语料还需进行空格处理、统一不同类型标点符号以及分字处理。
17、优选的,还包括有:根据已知古籍数据库的实体关系三元组、对数据库中的语料按照词或字级进行序列标注处理。
18、所述标注处理包括有利用自然语言工具,给每个词或每个字进行词性标注,再输入至神经网络编码层,经过编码层解析,然后通过解码层,最后通过输出层输出结果;其中,输出结果代表输入古籍文本分词或分字的序列标签,并与分词结果一一对应
19、与现有技术相比,本发明具有以下有益效果:
20、通过知识图谱自动化构建中的实体抽取模型,采用深度学习方法,在以字为基本输入元素的基础上提出基于bilstm-crf的序列标注模型,实现对古籍文本实体的准确抽取,降低相关领域专家的投入,提升古籍对应的知识图谱的快速构建。
技术特征:
1.基于深度学习及人工蜂群的古籍文本实体抽取方法,其特征在于,包括:
2.根据权利要求1所述的基于深度学习及人工蜂群的古籍文本实体抽取方法,其特征在于,其中,embedding层使用word2vec训练的字向量初始化参数,在模型训练时进行参数微调。
3.根据权利要求1所述的基于深度学习及人工蜂群的古籍文本实体抽取方法,其特征在于,训练语料采用典籍与最新中文文章拼接而成的,并通过opencc软件完成繁转简。
4.根据权利要求1所述的基于深度学习及人工蜂群的古籍文本实体抽取方法,其特征在于,对于初始输入的字序列,由预训练得到词向量,从而作为embedding层的输入参数。
5.根据权利要求1所述的基于深度学习及人工蜂群的古籍文本实体抽取方法,其特征在于,其中训练语料还需进行空格处理、统一不同类型标点符号以及分字处理。
6.根据权利要求1所述的基于深度学习及人工蜂群的古籍文本实体抽取方法,其特征在于,还包括有:根据已知古籍数据库的实体关系三元组、对数据库中的语料按照词或字级进行序列标注处理。
7.根据权利要求6所述的基于深度学习及人工蜂群的古籍文本实体抽取方法,其特征在于,所述标注处理包括有利用自然语言工具,给每个词或每个字进行词性标注,再输入至神经网络编码层,经过编码层解析,然后通过解码层,最后通过输出层输出结果。
8.根据权利要求7所述的基于深度学习及人工蜂群的古籍文本实体抽取方法,其特征在于,其中,输出结果代表输入古籍文本分词或分字的序列标签,并与分词结果一一对应。
技术总结
本发明涉及实体抽取技术领域,尤其是基于深度学习及人工蜂群的古籍文本实体抽取方法,包括输入层、embedding层、BiLSTM层以及CRF层;具体的,以中文汉字的序列作为初始输入文本,通过输入层完成输入,随即通过embedding层将输入层输入的字序列中各个字映射为相应的向量,再通过BiLSTM层的双向结构对当前位置进行标注时结合上下文的信息,得到当前字的上下文表征向量;最后通过CRF层,根据上下文表征向量序列得到标注序列。通过知识图谱自动化构建中的实体抽取模型,采用深度学习方法,在以字为基本输入元素的基础上提出基于BiLSTM‑CRF的序列标注模型,实现对古籍文本实体的准确抽取,降低相关领域专家的投入,提升古籍对应的知识图谱的快速构建。
技术研发人员:潘秀琴,孙娜,李素敏,李瑞翔,卢勇
受保护的技术使用者:中央民族大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!