一种语言模型问题回答优化方法及其系统与流程
本发明涉及计算机领域,特别是一种语言模型问题回答优化方法及其系统。
背景技术:
1、语言模型通过对句子的上下文特征进行数学建模,来回答一个问题:出现的句子是否合理,语言模型是自然语言的基础,广泛应用于机器翻译语音识别、拼写纠错、输入法、手写体识别等。
2、目前使用语言模型进行提问回答,由于很多语言模型都是训练好的,在使用时候都有字数限制,对于未训练过的内容,语言模型无法很好的回答问题。目前只能通过对语言模型进行额外训练才能解决。
技术实现思路
1、为克服现有语言模型有字数限制,并且在回答未训练过的问题时,输出答案准确率低的问题,本发明的目的是提供一种语言模型问题回答优化方法及其系统,能够提高回答语言模型中不存在的内容的问题的准确性,并且解决字数限制的问题。
2、本发明采用以下方案实现:
3、一种语言模型问题回答优化方法,所述方法步骤如下:
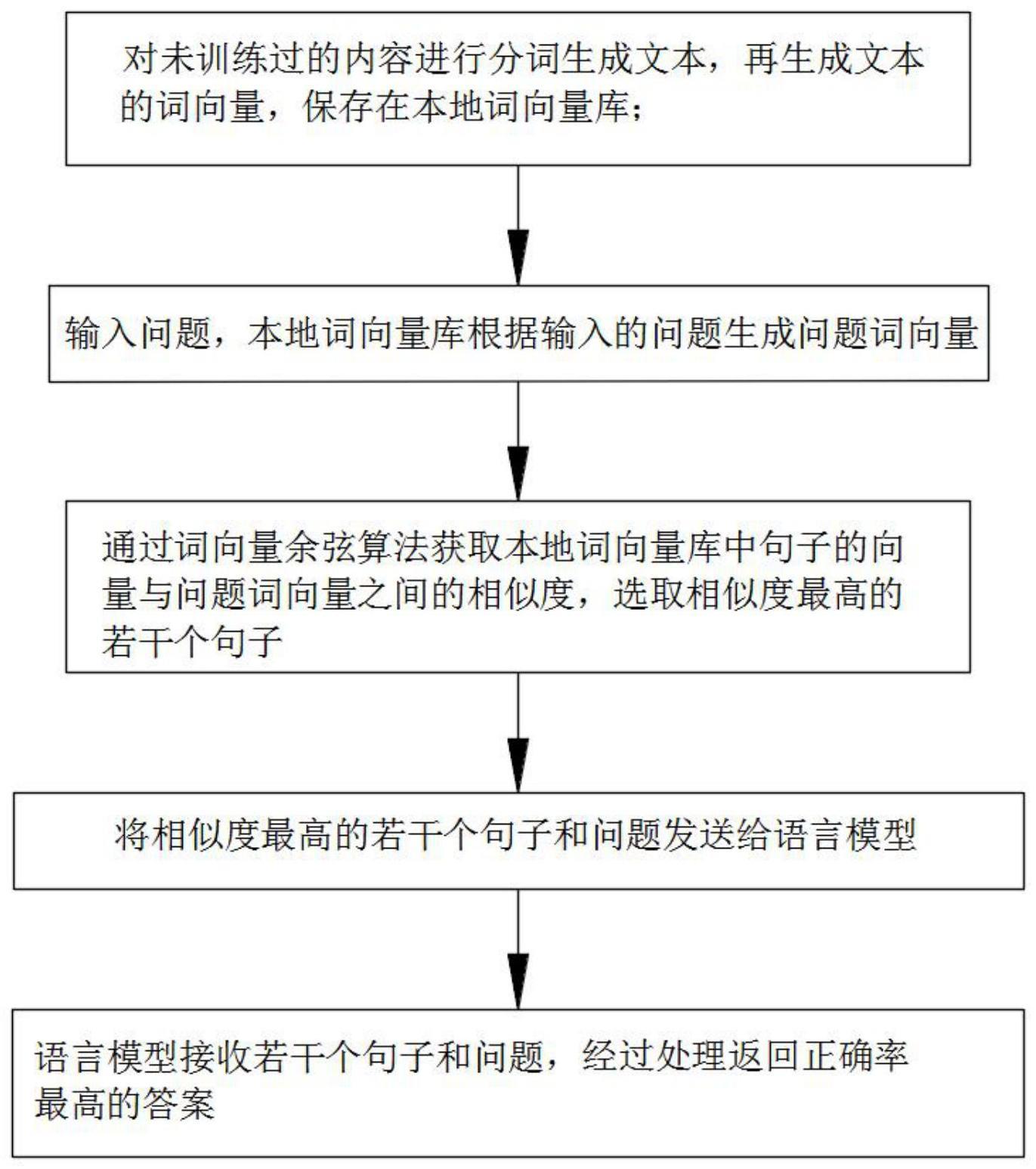
4、步骤1:对未训练过的内容进行分词生成文本,再生成文本的词向量,保存在本地词向量库;
5、步骤2:输入问题,根据输入的问题生成问题词向量;
6、步骤3:通过词向量余弦算法获取本地词向量库中句子与问题词向量之间的相似度,选取相似度最高的若干个句子;
7、步骤4:将相似度最高的若干个句子和问题发送给语言模型;
8、步骤5:语言模型接收若干个句子和问题,经过处理返回正确率最高的答案。
9、进一步的,步骤1进一步具体为:通过jieba分词工具对未训练过的内容进行分词,通过word2vec库将文本转为词向量,保存在本地词向量库。
10、进一步的,步骤2进一步具体为:输入问题,在本地词向量库中,将输入的问题转成一个的问题词向量,问题词向量能够匹配到相近距离的句子的向量或段落的向量。
11、进一步的,步骤3进一步具体为:通过词向量余弦算法计算每个句子的向量与问题词向量之间的相似度,得到一个相似度矩阵,所述相似度矩阵中每个元素表示两个句子之间的相似度得分,从相似度矩阵中选出与目标句子相似度最高的句子作为匹配结果。
12、进一步的,步骤4进一步具体为:通过模版字符串拼接的方式,把问题和若干个句子,提交给语言模型。
13、一种语言模型问题回答优化系统,所述系统包括词向量生成模块、问题词向量生成模块、相似度计算模块、输入模块、输出模块;
14、所述词向量生成模块用于对未训练过的内容进行分词生成文本,再生成文本的词向量,保存在本地词向量库;
15、所述问题词向量生成模块用于输入问题,根据输入的问题生成问题词向量;
16、所述相似度计算模块用于通过词向量余弦算法获取本地词向量库中句子与问题词向量之间的相似度,选取相似度最高的若干个句子;
17、所述输入模块用于将相似度最高的若干个句子和问题发送给语言模型;
18、所述输出模块用于语言模型接收若干个句子和问题,经过处理返回正确率最高的答案。
19、进一步的,词向量生成模块进一步具体为:通过jieba分词工具对未训练过的内容进行分词,通过word2vec库将文本转为词向量,保存在本地词向量库。
20、进一步的,问题词向量生成模块进一步具体为:输入问题,在本地词向量库中,将输入的问题转成一个的问题词向量,问题词向量能够匹配到相近距离的句子的向量或段落的向量。
21、进一步的,相似度计算模块进一步具体为:通过词向量余弦算法计算每个句子的向量与问题词向量之间的相似度,得到一个相似度矩阵,所述相似度矩阵中每个元素表示两个句子之间的相似度得分,从相似度矩阵中选出与目标句子相似度最高的句子作为匹配结果。
22、进一步的,输入模块进一步具体为:通过模版字符串拼接的方式,把问题和若干个句子,提交给语言模型。
23、本发明的有益效果在于:
24、本发明提供了一种语言模型问题回答优化方法及其系统,能够提高回答语言模型中不存在的内容的问题的准确性,对于未训练过的内容,只需把未训练过的内容的段落拆分开,只提取出和问题最相关的片段给语言模型,就能回答问题,在一定程度上解决字数限制的问题。
技术特征:
1.一种语言模型问题回答优化方法,其特征在于,所述方法步骤如下:
2.根据权利要求1所述的一种语言模型问题回答优化方法,其特征在于,步骤1进一步具体为:通过jieba分词工具对未训练过的内容进行分词,通过word2vec库将文本转为词向量,保存在本地词向量库。
3.根据权利要求1所述的一种语言模型问题回答优化方法,其特征在于,步骤2进一步具体为:输入问题,在本地词向量库中,将输入的问题转成一个的问题词向量,问题词向量能够匹配到相近距离的句子的向量或段落的向量。
4.根据权利要求1所述的一种语言模型问题回答优化方法,其特征在于,步骤3进一步具体为:通过词向量余弦算法计算每个句子的向量与问题词向量之间的相似度,得到一个相似度矩阵,所述相似度矩阵中每个元素表示两个句子之间的相似度得分,从相似度矩阵中选出与目标句子相似度最高的句子作为匹配结果。
5.根据权利要求1所述的一种语言模型问题回答优化方法,其特征在于,步骤4进一步具体为:通过模版字符串拼接的方式,把问题和若干个句子,提交给语言模型。
6.一种语言模型问题回答优化系统,其特征在于,所述系统包括词向量生成模块、问题词向量生成模块、相似度计算模块、输入模块、输出模块;
7.根据权利要求6所述的一种语言模型问题回答优化系统,其特征在于,词向量生成模块进一步具体为:通过jieba分词工具对未训练过的内容进行分词,通过word2vec库将文本转为词向量,保存在本地词向量库。
8.根据权利要求6所述的一种语言模型问题回答优化系统,其特征在于,问题词向量生成模块进一步具体为:输入问题,在本地词向量库中,将输入的问题转成一个的问题词向量,问题词向量能够匹配到相近距离的句子的向量或段落的向量。
9.根据权利要求6所述的一种语言模型问题回答优化系统,其特征在于,相似度计算模块进一步具体为:通过词向量余弦算法计算每个句子的向量与问题词向量之间的相似度,得到一个相似度矩阵,所述相似度矩阵中每个元素表示两个句子之间的相似度得分,从相似度矩阵中选出与目标句子相似度最高的句子作为匹配结果。
10.根据权利要求6所述的一种语言模型问题回答优化系统,其特征在于,输入模块进一步具体为:通过模版字符串拼接的方式,把问题和若干个句子,提交给语言模型。
技术总结
本发明涉及一种语言模型问题回答优化方法,方法为:对未训练过的内容进行分词生成文本,再生成文本的词向量,保存在本地词向量库;输入问题,本地词向量库根据输入的问题生成问题词向量;通过词向量余弦算法获取本地词向量库中句子的向量与问题词向量之间的相似度,选取相似度最高的若干个句子;将相似度最高的若干个句子和问题发送给语言模型;语言模型接收若干个句子和问题,经过处理返回正确率最高的答案,能够提高回答语言模型中未训练过的内容的问题的准确性,对于未训练过的内容,只需把未训练过的内容的段落拆分开,只提取出和问题最相关的片段给语言模型,就能回答问题,一定程度上解决字数限制的问题。
技术研发人员:刘德建,陈丛亮,李佳
受保护的技术使用者:福建天晴在线互动科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!