基于分层强化学习的时序知识图谱多跳推理方法
本发明涉及时序知识图谱,具体涉及一种基于分层强化学习的时序知识图谱多跳推理方法。
背景技术:
1、知识图谱是利用图结构来表示事物间的关系。它将事物抽象成图结构中的结点,将事物的关系抽象成连接这些结点的有向边。然而这些图谱中存在着大量一对多,多对多的关系类型,他们的数量远多于一对一的关系类型。这种类型的关系的大量存在将导致以关系和尾实体为组合的二元组动作空间发生空间爆炸。为了解决这一问题,现有方法中采取了限制动作空间的容量的办法,但是这个方法可能会将正确的预测目标排除在动作空间之外,从而降低模型的性能。
技术实现思路
1、本发明的目的在于提供一种基于分层强化学习的时序知识图谱多跳推理方法,以有效缓解动作空间爆炸的问题。
2、本发明解决上述技术问题的技术方案如下:
3、本发明提供一种基于分层强化学习的时序知识图谱多跳推理方法,所述基于分层强化学习的时序知识图谱多跳推理方法包括:
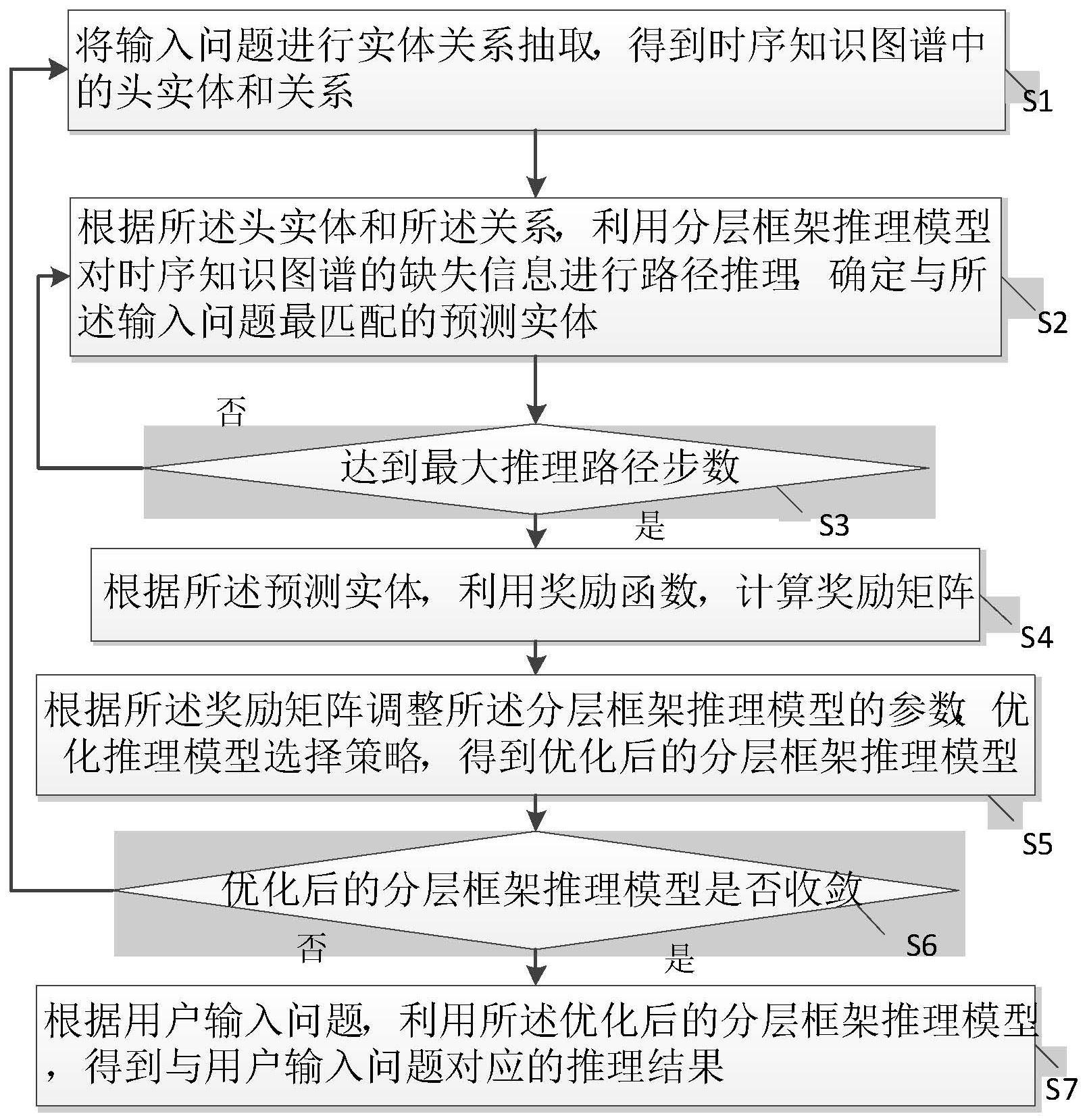
4、s1:将输入问题进行实体关系抽取,得到时序知识图谱中的头实体和关系;
5、s2:根据所述头实体和所述关系,利用分层框架推理模型对时序知识图谱的缺失信息进行路径推理,确定与所述输入问题最匹配的预测实体;
6、s3:判断是否达到最大推理路径步数,若是,进入s4;否则,返回s2;
7、s4:根据所述预测实体,利用奖励函数,计算奖励矩阵;
8、s5:根据所述奖励矩阵调整所述分层框架推理模型的参数,优化推理模型选择策略,得到优化后的分层框架推理模型;
9、s6:判断所述优化后的分层框架推理模型是否收敛,若是,进入s7,否则,返回s1;
10、s7:根据用户输入问题,利用所述优化后的分层框架推理模型,得到与用户输入问题对应的推理结果。
11、可选择地,所述s2包括:
12、s21:根据所述关系,确定与所述头实体相关的初始历史信息;
13、s22:根据所述头实体和当前推理步的历史信息,利用分层框架推理模型对时序知识图谱的缺失信息进行关系推理,得到关系推理结果;
14、s23:根据所述头实体、所述当前推理步的历史信息和所述关系推理结果,确定与所述输入问题最匹配的预测实体。
15、可选择地,所述s22包括:
16、s221:根据所述当前推理步的历史信息,利用lstm网络,生成历史路径编码;
17、s222:根据所述关系和所述历史路径编码,生成关系推理状态;
18、s223:根据所述关系推理状态,利用策略网络,生成当前推理步的预测关系;
19、s224:将所述头实体的所有出边关系组成的集合作为关系动作空间;
20、s225:计算所述预测关系和所述关系动作空间中每个候选关系的相似度;
21、s226:根据所有相似度,确定与所述预测关系最匹配的候选关系,并将其作为关系推理结果输出。
22、可选择地,所述s223中,
23、所述策略网络包括mlp网络,所述mlp网络包括两个全连接层和位于两个所述全连接层之间的relu激活函数层。
24、可选择地,所述s23包括:
25、s231:将所述当前推理步的历史信息和当前出发实体作为lstm网络的输入,生成尾实体预测过程的历史路径编码;
26、s232:根据所述头实体和所述尾实体预测过程中的历史路径编码,生成实体推理状态;
27、s233:根据所述实体推理状态预测尾实体;
28、s234:将所述当前出发实体经过所述关系推理结果能够到达尾实体所组成的集合作为尾实体动作空间;
29、s235:计算所述预测尾实体和所述尾实体动作空间中每个候选实体的相似度;
30、s236:根据所有相似度,确定与所述预测尾实体最匹配的候选尾实体;
31、s237:将所述最匹配的候选尾实体作为与所述输入问题关系最匹配的预测实体输出。
32、可选择地,所述s4中,所述奖励函数为:
33、
34、其中,r表示奖励函数,ep表示预测出的尾实体,eqo表示输入问题中的尾实体,rc表示奖励因子,表示实体e和时间戳t的聚类对比结果的交集且k表示聚类操作,ep表示推理路径的最终结果,就是终点实体,eqo是目标终点实体,k(ep)表示对推理路径的最终结果进行聚类,其输出为聚类标签,k(eqo)表示对目标终点实体进行聚类,k(ep)==k(eqo)表示对终点实体和目标终点实体的聚类标签进行比对,i表示二值化,返回的结果如果在同一聚类,经过二值化后表示为1,不在同一聚类的表示为0,tp表示推理结果中的时间戳,tq是目标时间戳,k(tp)表示对推理结果中的时间戳进行聚类,k(tq)表示对目标时间戳进行聚类,k(tp)==k(tq)表示对推理结果中的时间戳和目标时间戳的聚类标签进行比对,表示实体e和时间戳t的聚类对比结果的交集。
35、可选择地,所述s5中,根据所述奖励矩阵调整所述分层框架推理模型的参数包括:
36、所述分层框架推理模型的学习率、分层的集束搜索大小,dropout层的衰减率和所述奖励函数中k-means的聚类数量。
37、可选择地,所述s5中,所述推理模型选择策略包括mlp网络,所述mlp网络包括两个全连接层和位于两个所述全连接层之间的relu激活函数层。
38、本发明还提供一种基于上述的基于分层强化学习的时序知识图谱多跳推理方法的问答系统,所述问答系统包括:
39、问题输入模块,所述问题输入模块用于接收用户输入问题;
40、推理模块,所述推理模块用于根据所述用户输入问题,利用所述优化后的分层框架推理模型,得到与用户输入问题对应的推理结果;
41、结果展示模块,所述结果展示模块用于对所述推理结果向用户进行展示。
42、本发明具有以下有益效果:
43、本发明将分层强化学习技术与时序知识图谱多跳推理任务融合后产生的分层框架推理模型将有效缓解动作空间爆炸的问题,同时由于将原本一体的动作预测分解成关系预测和尾实体预测,增强了路径推理的可解释性,既提升了模型的预测精度,又节省了模型为存储冗余的动作空间消耗的内存。
技术特征:
1.一种基于分层强化学习的时序知识图谱多跳推理方法,其特征在于,所述基于分层强化学习的时序知识图谱多跳推理方法包括:
2.根据权利要求1所述的基于分层强化学习的时序知识图谱多跳推理方法,其特征在于,所述s2包括:
3.根据权利要求2所述的基于分层强化学习的时序知识图谱多跳推理方法,其特征在于,所述s22包括:
4.根据权利要求3所述的基于分层强化学习的时序知识图谱多跳推理方法,其特征在于,所述s223中,
5.根据权利要求2所述的基于分层强化学习的时序知识图谱多跳推理方法,其特征在于,所述s23包括:
6.根据权利要求1所述的基于分层强化学习的时序知识图谱多跳推理方法,其特征在于,所述s4中,所述奖励函数为:
7.根据权利要求1所述的基于分层强化学习的时序知识图谱多跳推理方法,其特征在于,所述s5中,根据所述奖励矩阵调整所述分层框架推理模型的参数包括:
8.根据权利要求1所述的基于分层强化学习的时序知识图谱多跳推理方法,其特征在于,所述s5中,所述推理模型选择策略包括mlp网络,所述mlp网络包括两个全连接层和位于两个所述全连接层之间的relu激活函数层。
9.一种基于权利要求1-8中任意一项所述的基于分层强化学习的时序知识图谱多跳推理方法的问答系统,其特征在于,所述问答系统包括:
技术总结
本发明公开了一种基于分层强化学习的时序知识图谱多跳推理方法,包括:S1:将输入问题进行实体关系抽取,得到时序知识图谱中的头实体和关系;S2:根据头实体和关系,对时序知识图谱的缺失信息进行路径推理,确定与输入问题最匹配的预测实体;S3:判断是否达到最大推理路径步数,若是,进入S4;否则,返回S2;S4:根据预测实体,计算奖励矩阵;S5:根据奖励矩阵调整分层框架推理模型的参数,优化推理模型选择策略,得到优化后的分层框架推理模型;S6:判断优化后的分层框架推理模型是否收敛,若是,进入S7,否则,返回S1;S7:根据用户输入问题,利用优化后的分层框架推理模型,得到与用户输入问题对应的推理结果。
技术研发人员:邵杰,罗雪薇,王萌,朱安婕,张嘉昇
受保护的技术使用者:电子科技大学(深圳)高等研究院
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!