一种连续动作控制强化学习框架及学习方法
本发明涉及人工智能,具体而言,涉及一种连续动作控制强化学习框架及学习方法。
背景技术:
1、目前,一些有效的深度强化学习算法被提出用于优化连续控制。最具代表性的是ddpg,它是基于演员评论家方法工作的。定义ρt是t时刻的状态,αt是t时刻的动作,同时定义确定性策略如下:
2、αt=πθ(ρt)
3、现有的演员-评论家框架通过循环更新累计回报的估计函数和最大化这个函数的策略来训练智能体。对累计回报的估计可通过最小化如下目标函数得到。
4、
5、其中b是采样到的状态转移,回报以及动作的集合。
6、
7、在更新策略的时候需要最大化的目标函数如下:
8、
9、基于演员-评论家框架,ddpg主要是通过全连接的神经网络来学习单步的状态转移然后通过单步的累计回报来估计累计回报函数的期望。td3和sac是两个基于ddpg的改进算法,td3通过双评论家网络,时序差分估计和高斯噪声改进了ddpg中的过估计,策略更新和探索。sac主要通过改进目标函数提升了ddpg中的探索,它也使用了双评论家网络和时序差分估计。
10、但是现有技术存在如下缺点:
11、1.只考虑单步的状态转移会导致学习效率不够高。
12、2.只考虑单步的回报来估计累计回报的期望会导致估计不够准确。
13、3.使用随机采样的状态转移更新神经网络,容易使得样本利用不够充分。
技术实现思路
1、为了克服上述问题或者至少部分地解决上述问题,本发明提供一种连续动作控制强化学习框架及学习方法,结合了卷积神经网络、多步时序差分估计和状态转移聚类,有效提高了学习效率以及准确度,并使样本利用更充分。
2、为解决上述技术问题,本发明采用的技术方案为:
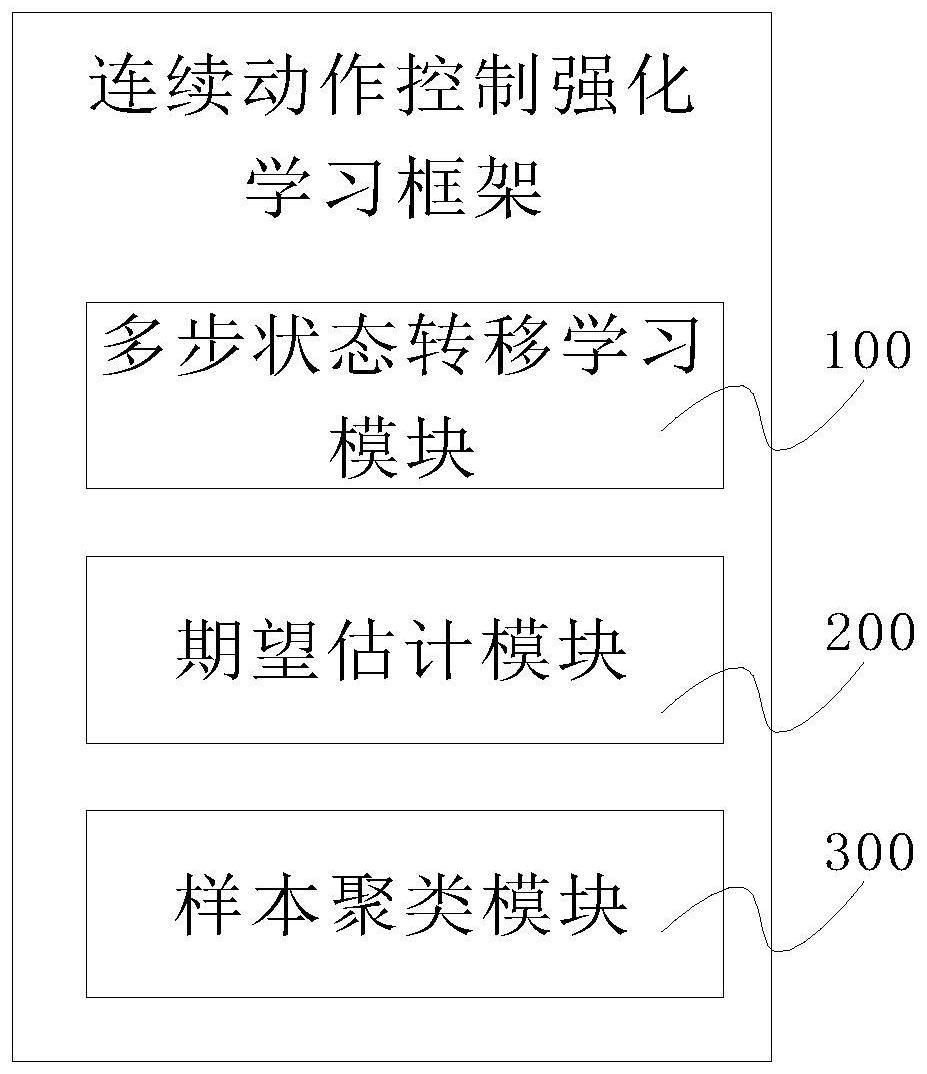
3、第一方面,本发明提供一种连续动作控制强化学习框架,包括多步状态转移学习模块、期望估计模块以及样本聚类模块,其中:
4、多步状态转移学习模块,用于采用卷积神经网络学习多步状态转移,更新策略;
5、期望估计模块,用于采用多步时序差分算法估计多步累计回报的期望;
6、样本聚类模块,用于对不同类型的状态转移样本进行聚类,使每种样本被均匀采样。
7、本框架首次结合了卷积神经网络、多步时序差分估计和状态转移聚类,它具有如下特点:使用卷积神经网络考虑多步状态转移来更新策略;使用多步时序差分算法来估计多步累计回报的期望;通过聚类现有状态转移样本,使得每种样本都被充分采样。本发明在针对连续控制的强化学习中通过卷积神经网络来学习多步状态转移,提高了学习效率;在上一步的基础上通过多步回报来估计累计回报的期望,让估计更准确;本发明还通过聚类使得不同类型的状态转移样本被均匀的采样,从而使得样本利用更充分。
8、基于第一方面,进一步地,上述策略为其中,α是动作、ρ指的状态、π是策略,θc是卷积神经网络的参数、t为当前时刻以及np为状态转移步数。
9、基于第一方面,进一步地,对以下目标函数进行最小化,以得到估计多步累计回报的期望,
10、目标函数为:
11、
12、中,np为状态转移步数,nq为回报步数,bn为采为样到的多步状态转移、多步回报以及动作的集合,e是期望,q是估计累计回报期望的函数,是估计q的参数以及
13、
14、基于第一方面,进一步地,采用函数更新策略。
15、基于第一方面,进一步地,进行聚类时,将训练的总步数平均分配到不同时间段内,对每个时间段内的样本进行聚类;上述聚类的方法采用k-means算法。
16、基于第一方面,进一步地,采样状态转移更新函数时,对每个聚类中的样本均匀采样。
17、本发明至少具有如下优点或有益效果:
18、本发明提供一种连续动作控制强化学习框架及学习方法,结合了卷积神经网络、多步时序差分估计和状态转移聚类,在针对连续控制的强化学习中通过卷积神经网络来学习多步状态转移,提高了学习效率;在上一步的基础上通过多步回报来估计累计回报的期望,让估计更准确;本发明还通过聚类使得不同类型的状态转移样本被均匀的采样,从而使得样本利用更充分。
技术特征:
1.一种连续动作控制强化学习框架,其特征在于,包括多步状态转移学习模块、期望估计模块以及样本聚类模块,其中:
2.根据权利要求1所述的一种连续动作控制强化学习框架,其特征在于,所述策略为其中,α是动作、ρ指的状态、π是策略,θc是卷积神经网络的参数、t为当前时刻以及np为状态转移步数。
3.根据权利要求1所述的一种连续动作控制强化学习框架,其特征在于,对以下目标函数进行最小化,以得到估计多步累计回报的期望,
4.根据权利要求3所述的一种连续动作控制强化学习框架,其特征在于,采用函数更新策略。
5.根据权利要求1所述的一种连续动作控制强化学习框架,其特征在于,进行聚类时,将训练的总步数平均分配到不同时间段内,对每个时间段内的样本进行聚类;所述聚类的方法采用k-means算法。
6.根据权利要求1所述的一种连续动作控制强化学习框架,其特征在于,采样状态转移更新函数时,对每个聚类中的样本均匀采样。
7.一种基于如权利要求1-6中任一项所述的连续动作控制强化学习框架的连续动作控制强化学习方法,其特征在于,包括以下操作
技术总结
本发明公开了一种连续动作控制强化学习框架及学习方法,涉及人工智能技术领域。该学习框架包括:多步状态转移学习模块,用于采用卷积神经网络学习多步状态转移,更新策略;期望估计模块,用于采用多步时序差分算法估计多步累计回报的期望;样本聚类模块,用于对不同类型的状态转移样本进行聚类,使每种样本被均匀采样。本发明结合了卷积神经网络、多步时序差分估计和状态转移聚类,有效提高了学习效率以及准确度,并使样本利用更充分。
技术研发人员:黄天意
受保护的技术使用者:西湖大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!