基于细粒度特征的机翻评估指标的解释方法、解释器模型及计算机可读存储介质与流程
本发明属于机器翻译,具体的说,是涉及一种基于细粒度特征的机翻评估指标的解释方法、解释器模型及计算机可读存储介质。
背景技术:
1、在传统的人工评估手段中,评估者通常从翻译充分度、译文流畅度、译文可阅读性三个方面,来评估机翻译文的质量,为了获得更快速地评估,一些研究者提出了bleu等基于规则的评估指标。bleu指标基于单词或者n-gram的共现率进行评估,蕴含了人工评估中的充分度指标。近年来,为了更好地评估机翻译文的质量,另一部分研究者提出了bertscore、moverscore和comet等基于预训练模型的评估指标,这些指标在评估机翻译文的质量,能兼顾译文的充分度和流畅度,是一种更为先进的评估指标。
2、但在现阶段,bertscore等更为先进的机翻译文评估指标却没有被大规模使用到机翻译文的评估中,其原因在于:这些基于预训练模型的评估指标缺乏可解释性,基于预训练模型的评估指标,却是一个黑盒结构,难以形成合理解释。
3、为了解决这一问题,研究者们尝试使用机器学习中的lime、shap等解释器模型,来对机翻评估模型的结果进行解释。但是,这些方法通常只能从词位置级别给出解释,并没有给出更为符合机翻场景的其他解释类型,比如错误的类型等信息;并且基于简单线性模型的解释器模型,不能表达机翻译文质量评估场景下的细粒度特征。
技术实现思路
1、本发明的目的在于提供一种基于细粒度特征的机翻评估指标的解释方法,以解决现有技术所存在的技术问题。
2、为了实现上述目的,本发明采取的技术方案如下:
3、一种基于细粒度特征的机翻评估指标的解释方法,包括以下步骤:
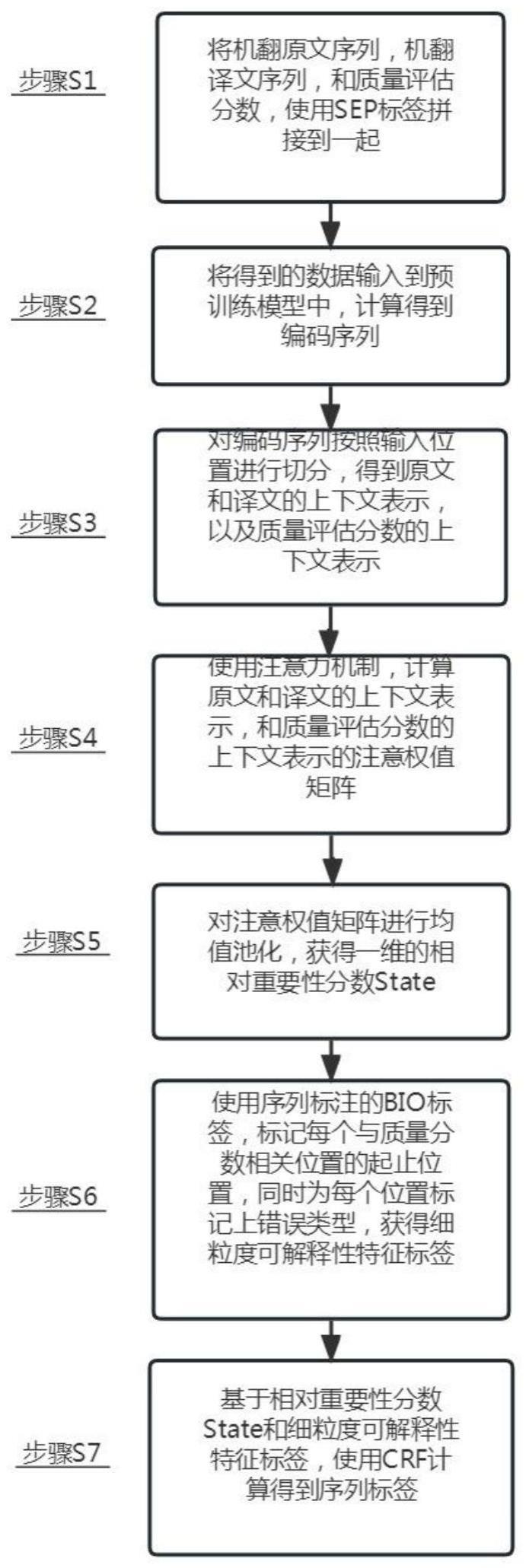
4、步骤s1:将机翻原文序列s=(s1,s2,...,sn),机翻译文序列h=(h1,h2,...,hm),和质量评估分数q,使用标签拼接到一起;
5、步骤s2:将步骤s1得到的数据输入到预训练模型中,计算得到编码序列:
6、t=encoder(s;h;q)
7、其中,encoder为预训练模型,t为通过预训练模型计算得到的上下文标签;
8、步骤s3:对所述编码序列按照输入位置进行切分,得到原文和译文的上下文表示ttext,以及质量评估分数的上下文表示tscore;
9、步骤s4:使用注意力机制,计算原文和译文的上下文表示ttext,和质量评估分数的上下文表示tscore的注意权值矩阵:
10、attention=softrmax(ttext⊙tscore);
11、步骤s5:对注意权值矩阵进行均值池化,获得一维的相对重要性分数state:
12、state=meanpooling(attention).
13、步骤s6:使用序列标注的标签,标记每个与质量分数相关位置的起止位置,同时为每个位置标记上错误类型,获得细粒度可解释性特征标签;
14、步骤s7:基于所述相对重要性分数state和所述细粒度可解释性特征标签,使用crf计算得到序列标签y=(y1,y2,...,yn+m):
15、y=crf(state)
16、在一种实施方案中,所述步骤s1中使用sep标签拼接。
17、在一种实施方案中,所述步骤s4中的注意力机制采用点乘注意力机制、连接注意力机制和双线性注意力机制中的一种。
18、在一种实施方案中,所述步骤s6中使用bio标签。
19、在一种实施方案中,所述步骤s6中细粒度可解释性特征标签包括:
20、b-miss漏译开始位置,i-miss漏译中间位置;
21、b-mist错译开始位置,i-mist错译中间位置;
22、b-over过译开始位置,i-over过译中间位置。
23、在一种实施方案中,所述步骤s1中的机翻原文序列s=(s1,s2,...,sn),机翻译文序列h=(h1,h2,...,hm),和质量评估分数q,均通过机翻质量评估模型推理得到。
24、在一种实施方案中,所述错误类型的发掘方法如下:首先,通过注意力机制推断机原文序列s=(s1,s2,…,sn),机制译文序列h=(h1,h2,...,hm),和质量评估分数q的错误片段,并表示为注意力矩阵中的权值高低的信号;然后,将所述权值高低的信号映射为0-n的转移状态信号,其中,n表示错误类型个数。
25、为了实现上述目的,本发明还提供了一种基于细粒度特征的机翻评估指标的解释器模型,包括:
26、拼接模块:将机翻原文序列s=(s1,s2,...,sn),机翻译文序列h=(h1,h2,...,hm),和质量评估分数q,使用标签拼接到一起;
27、编码序列模块:将得到的数据输入到预训练模型中,计算得到编码序列:
28、t=encoder(s;h;q)
29、其中,encoder为预训练模型,t为通过预训练模型计算得到的上下文标签;
30、上下文表示模块:对所述编码序列按照输入位置进行切分,得到原文和译文的上下文表示ttext,以及质量评估分数的上下文表示tscore;
31、注意权值模块:使用注意力机制,计算原文和译文的上下文表示ttext,和质量评估分数的上下文表示tscore的注意权值矩阵:
32、attention=softmax(ttext⊙tscore);
33、相对重要性分数模块:对注意权值矩阵进行均值池化,获得一维的相对重要性分数state:
34、state=meanpooling(attention);
35、细粒度可解释性特征标签模块:使用序列标注的标签,标记每个与质量分数相关位置的起止位置,同时为每个位置标记上错误类型,获得细粒度可解释性特征标签;
36、序列标签模块:基于所述相对重要性分数state和所述细粒度可解释性特征标签,使用crf计算得到序列标签y=(y1,y2,...,yn+m):
37、y=crf(state)。
38、为了实现上述目的,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行,以实现所述的基于细粒度特征的机翻评估指标的解释方法。
39、与现有技术相比,本发明具备以下有益效果:
40、本发明通过细粒度特征的机翻评估指标的解释方法/解释器模型,解决了机翻质量评估模型的可解释性不足的问题,并且为质量评估分数提供了适用于机翻场景下的细粒度可解释性特征,这些特征有望应用于机翻译文的人工pe阶段,并提升人工pe的效率。
技术特征:
1.一种基于细粒度特征的机翻评估指标的解释方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于细粒度特征的机翻评估指标的解释方法,其特征在于:所述步骤s1中使用sep标签拼接。
3.根据权利要求2所述的基于细粒度特征的机翻评估指标的解释方法,其特征在于,所述步骤s4中的注意力机制采用点乘注意力机制、连接注意力机制和双线性注意力机制中的一种。
4.根据权利要求3所述的基于细粒度特征的机翻评估指标的解释方法,其特征在于,所述步骤s6中使用bio标签。
5.根据权利要求4所述的基于细粒度特征的机翻评估指标的解释方法,其特征在于,所述步骤s6中细粒度可解释性特征标签包括:
6.根据权利要求5所述的基于细粒度特征的机翻评估指标的解释方法,其特征在于,所述步骤s1中的机翻原文序列s=(s1,s2,...,sn),机翻译文序列h=(h1,h2,...,hm),和质量评估分数q,均通过机翻质量评估模型推理得到。
7.根据权利要求6所述的基于细粒度特征的机翻评估指标的解释方法,其特征在于,所述错误类型的发掘方法如下;首先,通过注意力机制推断机翻原文序列s=(s1,s2,...,sn),机翻译文序列h=(h1,h2,...,hm),和质量评估分数q的错误片段,并表示为注意力矩阵中的权值高低的信号;然后,将所述权值高低的信号映射为0-n的转移状态信号,其中,n表示错误类型个数。
8.基于细粒度特征的机翻评估指标的解释器模型,其特征在于,包括:
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行,以实现权利要求1至7中任一项所述的基于细粒度特征的机翻评估指标的解释方法。
技术总结
本发明属于机器翻译技术领域,提供了一种基于细粒度特征的机翻评估指标的解释方法、解释器模型及计算机可读存储介质。本发明通过细粒度特征的机翻评估指标的解释方法/解释器模型,解决了机翻质量评估模型的可解释性不足的问题,并且为质量评估分数提供了适用于机翻场景下的细粒度可解释性特征,这些特征有望应用于机翻译文的人工PE阶段,并提升人工PE的效率。
技术研发人员:朱宪超,胡刚
受保护的技术使用者:四川语言桥信息技术有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!