一种基于元学习算法的稀缺资源领域英汉机器翻译方法与流程
本发明涉及一种机器翻译方法,特别是一种基于元学习算法的稀缺资源领域英汉机器翻译方法。
背景技术:
1、随着全球化的发展,各国交流沟通愈发繁多,在大语种上的机器翻译的研究早已如日中天,基于稀缺资源领域的翻译也相继展开。主流方法包括基于中间语言桥接的方法、仅基于单语数据的方法、基于半监督联合训练的方法和基于元学习的方法等。
2、元学习(meta learning)也叫“学会学习”(learning to learn),它是要“学会如何学习”,即利用以往的知识经验来指导新任务的学习,具有学会学习的能力。当前的深度学习大部分情况下只能从头开始训练。使用finetune来学习新任务,效果往往不好,而元学习就是研究让机器学会如何去学习,从不同任务中学习一个通用的学习方法论,来实现对未知新任务的泛化。
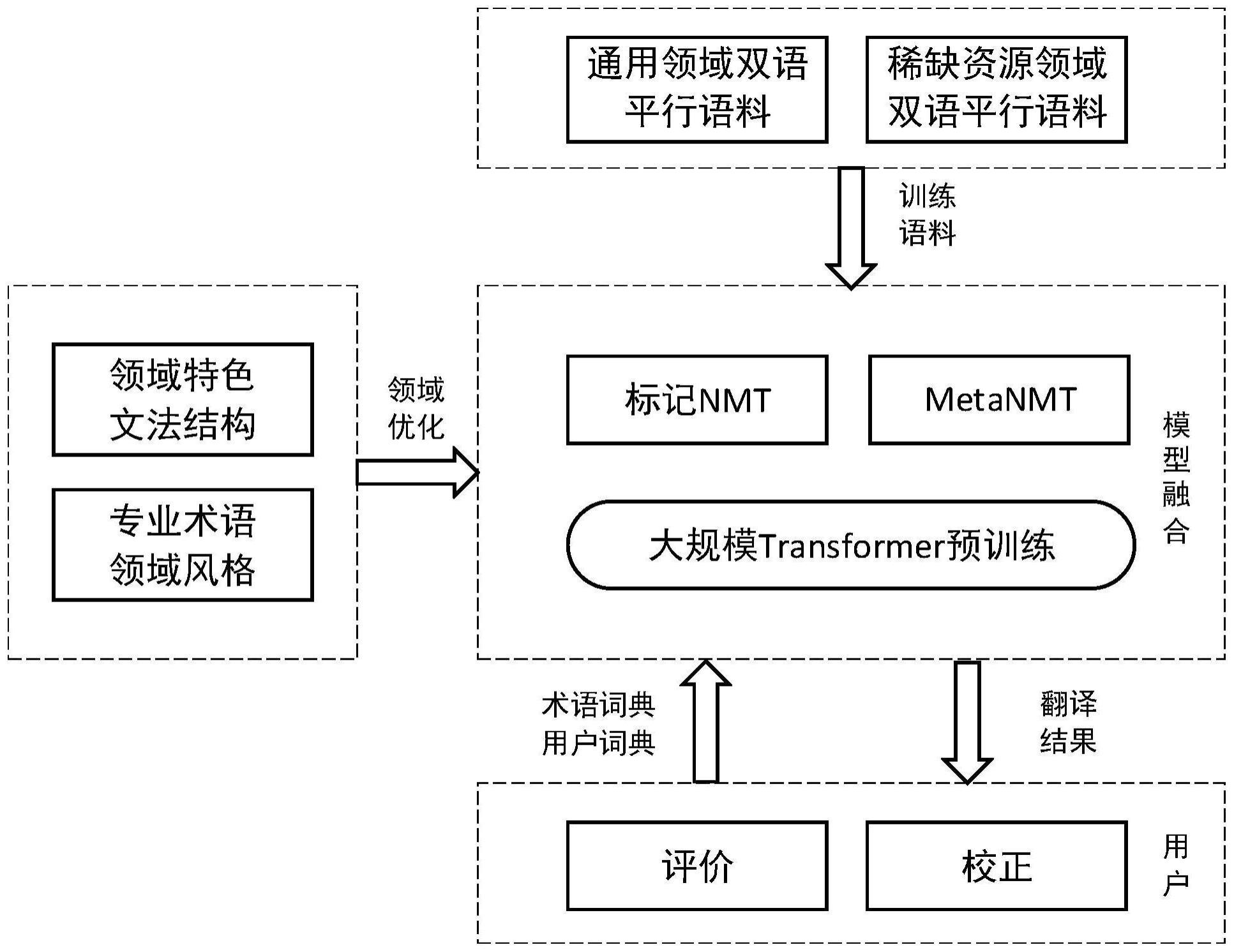
3、当前机器翻译模型大部分情况下只能从头开始训练,使用模型微调(finetune)来学习新任务,在稀缺资源领域效果往往不好。本发明通过泛化策略对特定稀缺资源领域语料进行泛化并标记,充分利用稀缺资源领域的语法结构、术语词典等。同时将翻译问题建构为元学习问题,先使通用领域下千万级别双语平行语料库训练出了好的初始参数。再以初始参数、通用策略模型为基础,训练特定稀缺资源领域的翻译。在此基础上进行进一步优化元学习初始参数模型,最终得到的模型可以很好地提升稀缺资源语种的翻译模型的性能。
技术实现思路
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于元学习算法的稀缺资源领域英汉机器翻译方法。
2、为了解决上述技术问题,本发明公开了一种基于元学习算法的稀缺资源领域英汉机器翻译方法,包括如下步骤:
3、步骤1、建设语料库;将所述语料库划分为测试集和训练集;
4、所述的语料库包括:收录不同主题的通用领域下双语平行语料库以及特定稀缺资源领域下的语料库。
5、步骤2、使用语料库中的通用领域下双语平行语料库,训练基于序列到序列框架的神经机器翻译模型,得到通用策略模型;
6、所述的基于序列到序列框架的神经机器翻译模型,包括编码器和解码器,编码器将输入内容映射到一个连续向量表示,解码器将向量表示映射到输出翻译内容。
7、步骤3、通过泛化标记策略优化调整通用策略模型的参数:采用关键词及关键短语的特定修正方法、特殊结构的泛化方法以及命名实体识别方法三种泛化标记策略对特定稀缺资源领域下的语料库中的语料进行泛化和语言学标记,得到标记词典;
8、使用通用策略模型对测试集进行翻译,并结合翻译结果和标记词典对所述通用策略模型进行优化调整;
9、所述的通过泛化标记策略优化调整通用策略模型的参数,即采用泛化标记策略对特定稀缺资源领域下的语料库中的语料进行泛化和语言学标记,得到标记词典;
10、使用通用策略模型对测试集进行翻译,并结合翻译结果和标记词典对所述通用策略模型进行优化调整。
11、所述泛化标记策略,至少包括:关键词及关键短语的特定修正方法、特殊结构的泛化方法以及命名实体识别方法中的任意一种或任意组合。
12、所述的关键词及关键短语的特定修正方法,包括:使用通用策略模型翻译特定稀缺资源领域下的语料库,将翻译结果和预期翻译结果进行比对,对不一致的关键词及关键短语进一步标签标记和修正。
13、所述的特殊结构的泛化方法,包括:对特定稀缺资源领域下语料库中的特殊结构进行标签标记和泛化。
14、所述的命名实体识别方法,包括:采用命名实体识别技术对特定稀缺资源领域下语料库中的特定实体进行标签标记和泛化。
15、所述的通过泛化标记策略优化调整通用策略模型的参数,具体包括如下步骤;
16、步骤3-1、通过泛化标记策略,使用泛化标签符号对特定稀缺资源领域下的语料库进行标记和泛化,同时将泛化标签符号的顺序记录在标记词典中;
17、步骤3-2、使用通用策略模型翻译特定稀缺资源领域下的语料库,得到包含泛化标签符号的翻译结果,依据标记词典恢复翻译结果中泛化标记符号对应位置,得到通用策略模型翻译结果;
18、步骤3-3、使用相应参考译文对翻译结果进行评测;
19、步骤3-4、根据评测结果优化调整通用策略模型的参数。
20、步骤4、将所述机器翻译过程建构为元学习问题,使用特定稀缺资源领域下的语料库对所述通用策略模型反复训练并优化,得到优化后的通用策略模型;
21、所述的对所述通用策略模型反复训练并优化,包括如下步骤:
22、步骤4-1、将元学习算法用于稀缺资源领域神经机器翻译过程中,把翻译问题建构为元学习问题;
23、步骤4-2、定义元目标函数l(θ),具体如下:
24、
25、其中,k~u{(1,…,k)}指第k个元训练轮次,u表示k次训练的集合,训练集dt,测试集d′t遵循在任务t上数据的均匀分布,θ表示元学习模型中的参数,ek表示第k轮次的期望,表示训练示例子集和测试示例子集的期望,表示特定于语言的学习过程公式化,p(y|x)表示后验分布;
26、步骤4-3、使用步骤1中所述训练集中的通用领域下双语平行语料,通过随机梯度下降方法逼近最大化元目标函数,训练得到通用领域下最优的初始参数θ0;
27、步骤4-4、对稀缺资源领域下语料库进行训练;通过随机梯度下降算法不断优化调整当前参数,得到元学习参数模型的最终参数θ。
28、步骤5、使用优化后的通用策略模型进行稀缺资源领域英汉机器翻译,用户对翻译结果进行人工校正,校正后的内容返回给上述通用策略模型进行自适应优化,得到最终的翻译模型,通过上述最终的翻译模型完成所述基于元学习算法的稀缺资源领域英汉机器翻译。
29、有益效果:
30、本研究构建了基于元学习的稀缺语料机器翻译引擎,探索元学习在机器翻译领域的应用,缓解了语料不足的问题,对于整体翻译效果提高有较大的作用。实际应用后翻译效果在通用翻译和特定稀缺资源领域翻译都有一定提升。
技术特征:
1.一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤1中所述的语料库包括:收录不同主题的通用领域下双语平行语料库以及特定稀缺资源领域下的语料库。
3.根据权利要求2所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤2中所述的基于序列到序列框架的神经机器翻译模型,包括编码器和解码器,编码器将输入内容映射到一个连续向量表示,解码器将向量表示映射到输出翻译内容。
4.根据权利要求3所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤3中所述的通过泛化标记策略优化调整通用策略模型的参数,即采用泛化标记策略对特定稀缺资源领域下的语料库中的语料进行泛化和语言学标记,得到标记词典;
5.根据权利要求4所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤3中所述泛化标记策略,至少包括:关键词及关键短语的特定修正方法、特殊结构的泛化方法以及命名实体识别方法中的任意一种或任意组合。
6.根据权利要求5所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤3中所述的关键词及关键短语的特定修正方法,包括:使用通用策略模型翻译特定稀缺资源领域下的语料库,将翻译结果和预期翻译结果进行比对,对不一致的关键词及关键短语进一步标签标记和修正。
7.根据权利要求5所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤3中所述的特殊结构的泛化方法,包括:对特定稀缺资源领域下语料库中的特殊结构进行标签标记和泛化。
8.根据权利要求5所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤3中所述的命名实体识别方法,包括:采用命名实体识别技术对特定稀缺资源领域下语料库中的特定实体进行标签标记和泛化。
9.根据权利要求5所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤3中所述的通过泛化标记策略优化调整通用策略模型的参数,具体包括如下步骤;
10.根据权利要求9所述的一种基于元学习算法的稀缺资源领域英汉机器翻译方法,其特征在于,步骤4所述的对所述通用策略模型反复训练并优化,包括如下步骤:
技术总结
本发明提出了一种基于元学习算法的稀缺资源领域英汉机器翻译方法,包括:建设语料库,包括千万级别通用领域双语平行语料、少量稀缺领域数据语料;通过通用领域双语平行语料训练通用策略模型;采用关键词、关键短语的特定修正,特殊结构的泛化,以及命名实体识别等技术对稀缺资源领域术语进行泛化和标记;将翻译问题建构为元学习问题,优化翻译模型在稀缺资源领域的表现;对用户校正后的内容进行自适应优化;本方法解决了稀缺资源领域中翻译数据稀疏问题,实现给定少量训练数据的情况下,快速提高稀缺资源领域英汉机器翻译质量的途径。
技术研发人员:吴帆,陈鹏,王妍妍,黄兆孟,陈文颖
受保护的技术使用者:中电莱斯信息系统有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!