基于HTrie树的中文敏感词变形体识别方法及系统
本发明涉及网络安全和信息安全领域,具体涉及一种基于htrie树的中文敏感词变形体识别方法及系统。
背景技术:
1、如今,互联网的各大社交平台用户数量激增,平台内容更新不断,用户随时随地发布的文本信息可能涉及政治、军事、娱乐、经济、道德等多个领域,越来越多的信息夹杂各种涉嫌各种不良信息,而这些信息的共同点是包含大量敏感词。一般情况下,网络不良信息使用的是准确无误的中文汉字,没有任何变形处理,这样只需简单的字符串匹配方法就能解决。除此以外考虑结合文本内容进行分析,如敏感词的过滤识别技术包括基于内容的单模式匹配如bf算法、rk算法、sunday算法、bm算法、horspool算法和典型的kmp算法等,或多模式匹配如wu-manber算法、trie树以及aho 和 corasick提出的aho-corasick算法等,或使用文本分类技术对文本中的敏感信息进行识别和过滤等,这类研究很好的解决了识别文本内容包含敏感信息的问题,但不能实现隐蔽敏感词的发现。
2、为避免以往简单的基于敏感词表等方法的识别和过滤,网络上出现越来越多的敏感词变形体以干扰识别系统的监测,而现有的算法如st-dfa算法和swdt-ifa算法等几乎难以识别多种变形敏感词或识别效率不高,这给社交平台过滤识别敏感信息带来巨大的难题,更影响着越来越多的网络用户尤其是未成年用户。
3、trie树又称前缀树或单词查找树,是哈希树的变种但效率高于哈希树,利用其字符串的公共前缀来减少查询时间,尽可能减少不必要的字符串比较。前缀搜索的优点在于查询速度快且可以查询以某一字符串为起始的所有结果而非完全匹配结果,因此,相对于其他的模式匹配算法,trie树用于识别敏感词变形体的效果更好。
4、综上所述,当前传统的敏感词识别算法无法处理变形体,而现有中文敏感词识别算法可处理的敏感词变形体类型有限且识别准确率不高。因此,如何提高敏感词识别的准确率成为一个亟待解决的问题。
技术实现思路
1、为了解决上述技术问题,本发明提供一种基于htrie树的中文敏感词变形体识别方法及系统。
2、本发明技术解决方案为:一种基于htrie树的中文敏感词变形体识别方法,包括:
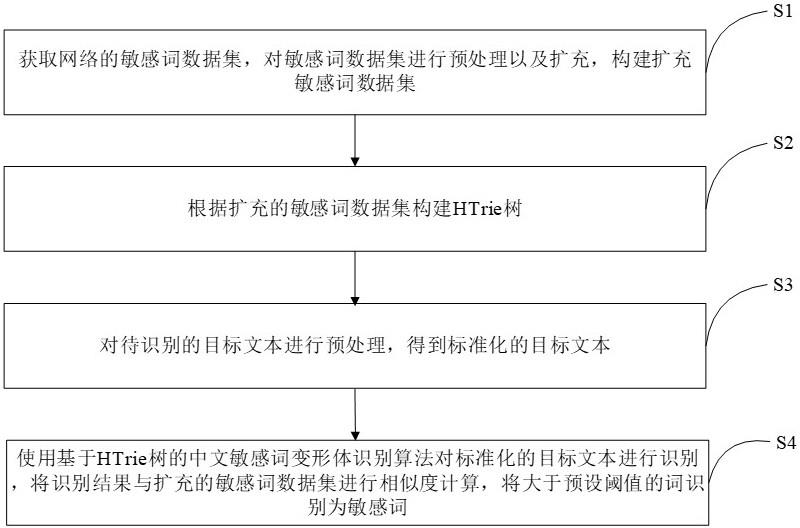
3、步骤s1:获取网络的敏感词数据集,对所述敏感词数据集进行预处理以及扩充,构建扩充敏感词数据集;
4、步骤s2:根据所述扩充的敏感词数据集构建htrie树;
5、步骤s3:对待识别的目标文本进行预处理,得到标准化的目标文本;
6、步骤s4:使用基于htrie树的中文敏感词变形体识别算法对所述标准化的目标文本进行识别,将识别结果与所述扩充的敏感词数据集进行相似度计算,将大于预设阈值的词识别为敏感词。
7、本发明与现有技术相比,具有以下优点:
8、1、本发明公开了一种基于htrie树的中文敏感词变形体识别方法,构建扩充敏感词数据集,增加了可处理敏感词变形体的类型数量,从而解决了现有方法文敏感词识别算法存在可处理的敏感词变形体类型有限和识别准确率不高的问题,以及网络信息严重人工干扰问题。
9、2、本发明构建htrie树用于存储敏感词的中文、英文和拼音形式,并在识别近音字等隐蔽词汇时将结果与数据集进行验证计算,添加了相似度比对,提高了识别敏感词的查全率和查准率,其中查全率的提升尤为显著。
技术特征:
1.一种基于htrie树的中文敏感词变形体识别方法,其特征在于,包括:
2.根据权利要求1所述的基于htrie树的中文敏感词变形体识别方法,其特征在于,所述步骤s1:获取网络的敏感词数据集,对所述敏感词数据集进行预处理以及扩充,构建扩充敏感词数据集,具体包括:
3.根据权利要求2所述的基于htrie树的中文敏感词变形体识别方法,其特征在于,所述步骤s2:根据所述扩充的敏感词数据集构建htrie树,具体包括:
4.根据权利要求3所述的基于htrie树的中文敏感词变形体识别方法,其特征在于,所述步骤s4:使用基于htrie树的中文敏感词变形体识别算法对所述标准化的目标文本进行识别,将识别结果与所述扩充的敏感词数据集进行相似度计算,将大于预设阈值的词识别为敏感词,具体包括:
5.根据权利要求4所述的基于htrie树的中文敏感词变形体识别方法,其特征在于,所述步骤s42中所述基于htrie树的中文敏感词变形体识别算法,具体包括:
6.一种基于htrie树的中文敏感词变形体识别系统,其特征在于,包括下述模块:
技术总结
本发明涉及一种基于HTrie树的中文敏感词变形体识别方法及系统,其方法包括:步骤S1:获取网络的敏感词数据集,对敏感词数据集进行预处理以及扩充,构建扩充敏感词数据集;步骤S2:根据扩充的敏感词数据集构建HTrie树;步骤S3:对待识别的目标文本进行预处理,得到标准化的目标文本;步骤S4:使用基于HTrie树的中文敏感词变形体识别算法对标准化的目标文本进行识别,将识别结果与扩充的敏感词数据集进行相似度计算,将大于预设阈值的词识别为敏感词。本发明提供的方法可提高敏感词识别的查全率和查准率。
技术研发人员:张克君,金禹含,王文彬,王钧,邹兵
受保护的技术使用者:北京电子科技学院
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!