一种散货码头装船流程的优化方法及装置与流程
本发明涉及人工智能,尤其涉及一种散货码头装船流程的优化方法及装置。
背景技术:
1、海运作为贸易运输的主要方式,以其运量大及运费低的特点占据主导地位。现有的散货煤炭码头的装船作业虽然已有近50年的研究历史,但仍然存在局限性,如寻优结果不具备全局特性、计算规模有限、需因此,要大量专业知识等。此外,优化模型固定,无法适应生产过程特性的变化。因此,需要寻求新的解决方案。针对码头排产问题,传统的人工制定计划通常以当下空闲设备为依据,缺乏长期最优性。而码头排产计划安排受到多种约束限制,如装船机、取料机、堆料的占用情况、设备的突发故障、煤种短缺等不确定因素,使得港口的排产问题成为一个复杂的优化问题。
2、为了解决这一问题,研究者们尝试利用深度强化学习算法,通过设置合理的奖励函数,不断地进行探索训练,找到排产方法的优化方法,以减少人力资源的投入,并提高码头长期的运输效率。然而,现有的强化学习算法仍存在缺陷,如利用的是理想的车间调度模型,与实际工程中的情况还有着很大的差距,且尚无面向机器学习算法的装船过程建模方法出现。因此,需要进一步研究和改进强化学习算法,以更好地解决码头排产问题。
技术实现思路
1、本发明提供了一种散货码头装船流程的优化方法及装置,基于港口排产调度模型,利用double-dqn算法进行训练,得到排产效率明显提高的调度最优解。
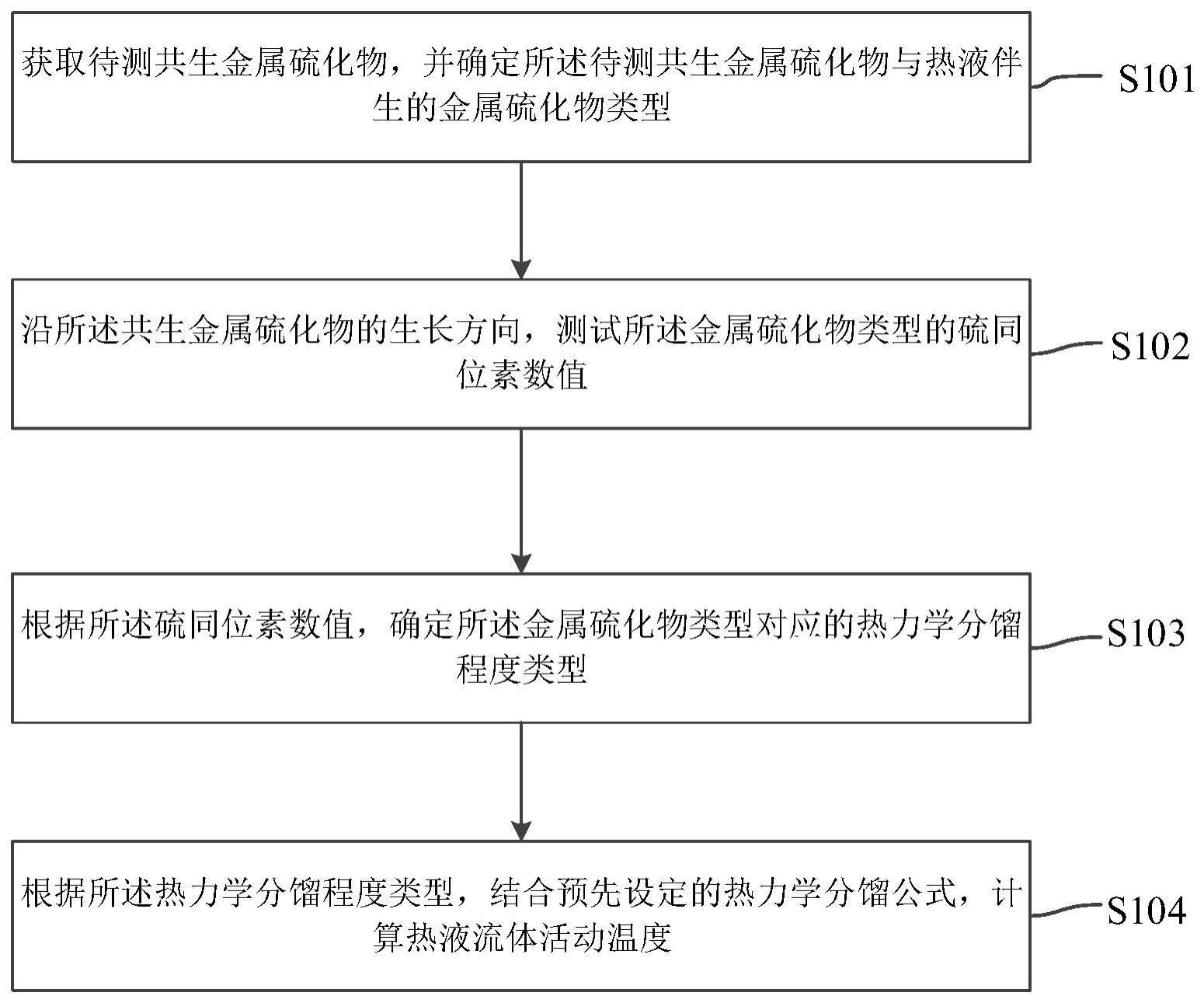
2、第一方面,本发明提供了一种散货码头装船流程的优化方法,包括:
3、获取港口排产调度模型;
4、根据double-dqn算法,构建所述港口排产调度模型对应的港口排产调度强化学习模型;
5、根据所述double-dqn算法,从所述港口排产调度强化学习模型中确定当前状态、下一时刻状态、当前动作,以及由状态和动作构建系统的奖励;
6、基于所述当前状态、所述下一时刻状态、所述当前动作,以及所述由状态和动作构建系统的奖励,利用经验回放进行double-dqn算法的学习,得到所述港口排产调度强化学习模型的调度最优解。
7、可选地,根据double-dqn算法,构建所述散货码头调度模型对应的散货码头强化学习模型,包括:
8、设定所述散货码头调度模型中的调度分配控制器为强化学习的智能体;
9、创建相同结构的训练q神经网络和目标q神经网络;
10、基于所述智能体、所述训练q神经网络和所述目标q神经网络,构建所述散货码头强化学习模型。
11、可选地,基于所述当前状态、所述下一时刻状态、所述当前动作,以及所述由状态和动作构建系统的奖励,利用经验回放进行double-dqn算法的学习,得到所述散货码头强化学习模型的调度最优解,包括:
12、为所述智能体创建经验回放池,在每一个迭代过程中,基于ε-greedy策略,将所述当前状态、所述当前动作、所述下一时刻状态和当前时刻奖励组成一个元组作为经验数据,放在经验回放池;
13、所述训练q神经网络和所述目标q神经网络利用所述经验回访池中的经验数据进行学习,得到所述散货码头强化学习模型的调度最优解。
14、可选地,基于所述当前状态、所述下一时刻状态、所述当前动作,以及所述由状态和动作构建系统的奖励,利用经验回放进行double-dqn算法的学习,得到所述散货码头强化学习模型的调度最优解之后,包括:
15、校验所述港口排产调度强化学习模型的所述调度最优解和所述港口排产调度强化学习模型的性能。
16、第二方面,本发明提供了一种散货码头装船流程的优化装置,包括:
17、获取模块,用于获取港口排产调度模型;
18、构建模块,用于根据double-dqn算法,构建所述港口排产调度模型对应的港口排产调度强化学习模型;
19、决策模块,用于根据所述double-dqn算法,从所述港口排产调度强化学习模型中确定当前状态、下一时刻状态、当前动作,以及由状态和动作构建系统的奖励;
20、调度分析模块,用于基于所述当前状态、所述下一时刻状态、所述当前动作,以及所述由状态和动作构建系统的奖励,利用经验回放进行double-dqn算法的学习,得到所述港口排产调度强化学习模型的调度最优解。
21、可选地,所述构建模块包括:
22、设定子模块,用于设定所述散货码头调度模型中的调度分配控制器为强化学习的智能体;
23、创建子模块,用于创建相同结构的训练q神经网络和目标q神经网络;
24、构建子模块,用于基于所述智能体、所述训练q神经网络和所述目标q神经网络,构建所述散货码头强化学习模型。
25、可选地,所述调度分析子模块包括:
26、经验回访池创建子模块,用于为所述智能体创建经验回放池,在每一个迭代过程中,基于ε-greedy策略,将所述当前状态、所述当前动作、所述下一时刻状态和当前时刻奖励组成一个元组作为经验数据,放在经验回放池;
27、最优解确定子模块,用于通过所述训练q神经网络和所述目标q神经网络利用所述经验回访池中的经验数据进行学习,得到所述散货码头强化学习模型的调度最优解。
28、可选地,还包括:
29、校验模块,用于校验所述港口排产调度强化学习模型的所述调度最优解和所述港口排产调度强化学习模型的性能。
30、第三方面,本申请提供一种电子设备,包括处理器以及存储器,所述存储器存储有计算机可读取指令,当所述计算机可读取指令由所述处理器执行时,运行如上述第一方面提供的所述方法中的步骤。
31、第四方面,本申请提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时运行如上述第一方面提供的所述方法中的步骤。
32、从以上技术方案可以看出,本发明具有以下优点:
33、本发明提供了一种散货码头装船流程的优化方法及装置,方法包括:获取港口排产调度模型;根据double-dqn算法,构建所述港口排产调度模型对应的港口排产调度强化学习模型;根据所述double-dqn算法,从所述港口排产调度强化学习模型中确定当前状态、下一时刻状态、当前动作,以及由状态和动作构建系统的奖励;基于所述当前状态、所述下一时刻状态、所述当前动作,以及所述由状态和动作构建系统的奖励,利用经验回放进行double-dqn算法的学习,得到所述港口排产调度强化学习模型的调度最优解。基于港口排产调度模型,利用double-dqn算法进行训练,得到调度最优解,对于提高码头的排产效率,减少人力资源的投入有着重要意义。
技术特征:
1.一种散货码头装船流程的优化方法,其特征在于,包括:
2.根据权利要求1所述的散货码头装船流程的优化方法,其特征在于,根据double-dqn算法,构建所述散货码头调度模型对应的散货码头强化学习模型,包括:
3.根据权利要求2所述的散货码头装船流程的优化方法,其特征在于,基于所述当前状态、所述下一时刻状态、所述当前动作,以及所述由状态和动作构建系统的奖励,利用经验回放进行double-dqn算法的学习,得到所述散货码头强化学习模型的调度最优解,包括:
4.根据权利要求2所述的散货码头装船流程的优化方法,其特征在于,基于所述当前状态、所述下一时刻状态、所述当前动作,以及所述由状态和动作构建系统的奖励,利用经验回放进行double-dqn算法的学习,得到所述散货码头强化学习模型的调度最优解之后,包括:
5.一种散货码头装船流程的优化装置,其特征在于,包括:
6.根据权利要求5所述的散货码头装船流程的优化装置,其特征在于,所述构建模块包括:
7.根据权利要求6所述的散货码头装船流程的优化装置,其特征在于,所述调度分析子模块包括:
8.根据权利要求6所述的散货码头装船流程的优化方法,其特征在于,还包括:
9.一种电子设备,其特征在于,包括处理器以及存储器,所述存储器存储有计算机可读取指令,当所述计算机可读取指令由所述处理器执行时,运行如权利要求1-4任一项所述的方法。
10.一种存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时运行如权利要求1-4任一项所述的方法。
技术总结
本申请提供的一种散货码头装船流程的优化方法及装置,方法包括:获取港口排产调度模型;根据Double‑DQN算法,构建所述港口排产调度模型对应的港口排产调度强化学习模型;根据所述Double‑DQN算法,从所述港口排产调度强化学习模型中确定当前状态、下一时刻状态、当前动作,以及由状态和动作构建系统的奖励;基于所述当前状态、所述下一时刻状态、所述当前动作,以及所述由状态和动作构建系统的奖励,利用经验回放进行Double‑DQN算法的学习,得到所述港口排产调度强化学习模型的调度最优解。从而提高码头的排产效率,减少人力资源的投入有着重要意义。
技术研发人员:李长安,庞坤,刘军,张羽霄,吴思锐,宋郁珉,张思京,王宪超,曹卫冲,陈健学,白云广,赵斌,张世昌,赵力平
受保护的技术使用者:国能(天津)港务有限责任公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!