客户异议挖掘方法和装置、电子设备及存储介质与流程
本申请涉及人工智能,尤其涉及一种客户异议挖掘方法和装置、电子设备及存储介质。
背景技术:
1、保险电话销售在进行客户经营、产品销售等业务过程中,会面临不同类型的客户异议(比如:我不需要保险、已经买过保险了)。现有的电销助手会对客户异议进行识别,并推荐给坐席相应的应答话术,以辅助坐席进行答复。但随着新产品上市、经济社会发展、居民生活改善等内外部环境变化,客户异议也会发生改变,不断有新的异议产生。目前对于新增的客户异议,主要采用人工挖掘的方式,由业务人员人工筛选出未覆盖的异议。该方案主要存在3个缺点:
2、(1)人力成本高:每日坐席通话量很大(千万级通话文本数),需要大量人力。且人员培训和管理也存在难点,如:新人培训、人员离职等;
3、(2)覆盖面较小:由于坐席通话量很大且人力有限,目前只覆盖了成交件(占比小于5%),大量坐席的通话没有覆盖;
4、(3)实时性低:新异议的挖掘周期较长,一般超过1个月,无法适应产品迭代速度。
技术实现思路
1、本申请实施例的主要目的在于提出一种客户异议挖掘方法和装置、电子设备及存储介质,能够自动挖掘新增的客户异议,解决目前人工挖掘中存在人力成本高、覆盖面较小和实时性低的问题。
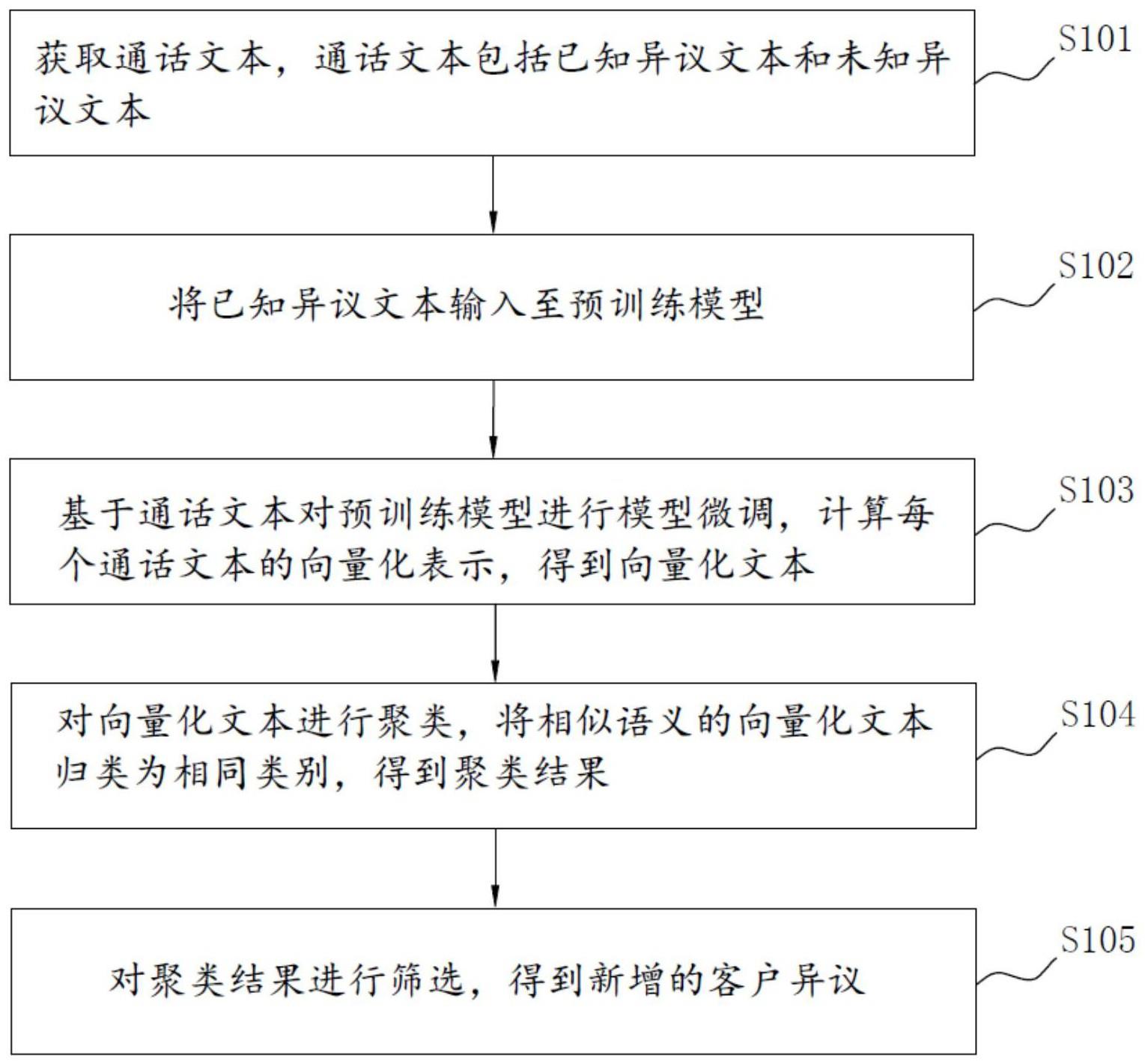
2、为实现上述目的,本申请实施例的第一方面提出了一种客户异议挖掘方法,所述方法包括:
3、获取通话文本,所述通话文本包括已知异议文本和未知异议文本;
4、将所述已知异议文本输入至预训练模型;
5、基于所述通话文本对所述预训练模型进行模型微调,计算每个所述通话文本的向量化表示,得到向量化文本;
6、对向量化文本进行聚类,将相似语义的所述向量化文本归类为相同类别,得到聚类结果;
7、对所述聚类结果进行筛选,得到新增的客户异议。
8、在一些实施例,所述预训练模型包括基于bert的文本编码器、线性层和softmax层,所述将所述已知异议文本输入至预训练模型,包括:
9、将所述已知异议文本中输入至基于bert的文本编码器,计算得到所述已知异议文本中每个字符的向量化表示;
10、选择每个字符中的首字符对应的所述向量化表示作为所述已知异议文本的句向量表示;
11、将所述句向量表示输入至线性层和softmax层,得到所述已知异议文本属于第i类异议的概率,其中,i为大于1的正整数。
12、在一些实施例,所述基于所述通话文本对所述预训练模型进行模型微调,计算每个所述通话文本的向量化表示,得到向量化文本,包括:
13、对所述通话文本的数据进行数据增强,得到已知异议的增强数据和未知异议的增强数据;
14、根据所述已知异议的增强数据和所述未知异议的增强数据确定半监督对比损失、监督损失和正则项;
15、根据所述半监督对比损失、所述监督损失和所述正则项确定模型微调的训练目标;
16、基于所述模型微调的训练目标对所述预训练模型进行模型微调;
17、计算每个所述未知异议文本的向量化表示,得到向量化文本。
18、在一些实施例,所述对向量化文本进行聚类,将相似语义的所述向量化文本归类为相同类别,得到聚类结果,包括:
19、获取所述未知异议文本的句向量;
20、确定聚类算法的类别数量;
21、对每个数据,计算每个所述数据与多个类别的初始中心的距离,并将所述数据归类到距离最近的类别;
22、对每个类别,计算类别内所有数据的句向量的平均值作为新的类别中心,直到所有数据的类别划分不再发生变化;
23、采用聚类算法将相似文本被划分为相同类别,得到聚类结果。
24、在一些实施例,所述确定聚类算法的类别数量,包括:
25、随机设定多个初始类别数量k’,得到k’个初始类别;
26、计算每个所述初始类别的置信度;
27、从k’个初始类别中选取置信度高于预设置信度阈值的k个类别作为聚类算法的类别数量,其中,k小于等于k’。
28、在一些实施例,所述采用聚类算法将相似文本被划分为相同类别,得到聚类结果,包括:
29、采用kmeans聚类算法将相似文本被划分为相同类别,得到分类类别;
30、对所有所述分类类别进行质量评估,筛除低质类别,得到聚类结果。
31、在一些实施例,所述对所有所述分类类别进行质量评估,筛除低质类别,得到聚类结果,包括:
32、计算每个类别内数据的轮廓系数;
33、对每个类别内的数据按照轮廓系数由高到低排列,生成类别描述;
34、在所述类别的轮廓系数低于预设轮廓系数阈值的情况下,确定所述类别为低质类别;
35、将所述低质类别筛除,得到聚类结果。
36、为实现上述目的,本申请实施例的第二方面提出了一种客户异议挖掘装置,所述装置包括:
37、获取模块,用于获取通话文本,所述通话文本包括已知异议文本和未知异议文本;
38、预训练模块,用于将所述已知异议文本输入至预训练模型;
39、微调模块,用于基于所述通话文本对所述预训练模型进行模型微调,计算每个所述通话文本的向量化表示,得到向量化文本;
40、聚类模块,用于对向量化文本进行聚类,将相似语义的所述向量化文本归类为相同类别,得到聚类结果;
41、筛选模块,用于对所述聚类结果进行筛选,得到新增的客户异议。
42、为实现上述目的,本申请实施例的第三方面提出了一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的方法。
43、为实现上述目的,本申请实施例的第四方面提出了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述的方法。
44、本申请提出的客户异议挖掘方法和装置、电子设备及存储介质,获取通话文本,通话文本包括已知异议文本和未知异议文本;将已知异议文本输入至预训练模型;基于通话文本对预训练模型进行模型微调,计算每个通话文本的向量化表示,得到向量化文本;对向量化文本进行聚类,将相似语义的向量化文本归类为相同类别,得到聚类结果;对聚类结果进行筛选,得到新增的客户异议。基于此,本申请实施例的模型预训练基于已知异议的文本进行训练;模型微调基于已知和未知异议的文本进行模型更新,计算得到每个文本的向量化表示;然后对向量化文本进行聚类,使得相似语义的文本成为相同类别,即新的客户异议;最终对聚类结果进行筛选,选出新增的客户异议,从而能够自动挖掘新增的客户异议,解决目前人工挖掘中存在人力成本高、覆盖面较小和实时性低的问题。
技术特征:
1.一种客户异议挖掘方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述预训练模型包括基于bert的文本编码器、线性层和softmax层,所述将所述已知异议文本输入至预训练模型,包括:
3.根据权利要求1所述的方法,其特征在于,所述基于所述通话文本对所述预训练模型进行模型微调,计算每个所述通话文本的向量化表示,得到向量化文本,包括:
4.根据权利要求1所述的方法,其特征在于,所述对向量化文本进行聚类,将相似语义的所述向量化文本归类为相同类别,得到聚类结果,包括:
5.根据权利要求4所述的方法,其特征在于,所述确定聚类算法的类别数量,包括:
6.根据权利要求4所述的方法,其特征在于,所述采用聚类算法将相似文本被划分为相同类别,得到聚类结果,包括:
7.根据权利要求6所述的方法,其特征在于,所述对所有所述分类类别进行质量评估,筛除低质类别,得到聚类结果,包括:
8.一种客户异议挖掘装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现权利要求1至7任一项所述的客户异议挖掘方法。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7中任一项所述的客户异议挖掘方法。
技术总结
本申请实施例提供了一种客户异议挖掘方法和装置、电子设备及存储介质,属于人工智能技术领域。该方法包括:获取通话文本,通话文本包括已知异议文本和未知异议文本;将已知异议文本输入至预训练模型;基于通话文本对预训练模型进行模型微调,计算每个通话文本的向量化表示,得到向量化文本;对向量化文本进行聚类,将相似语义的向量化文本归类为相同类别,得到聚类结果;对聚类结果进行筛选,得到新增的客户异议。基于此,本申请实施例能够自动挖掘新增的客户异议,解决目前人工挖掘中存在人力成本高、覆盖面较小和实时性低的问题。
技术研发人员:孙泽烨,马龙
受保护的技术使用者:中国平安人寿保险股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!