一种基于多种microRNA分子特征的肺腺癌机器学习分类模型的制作方法
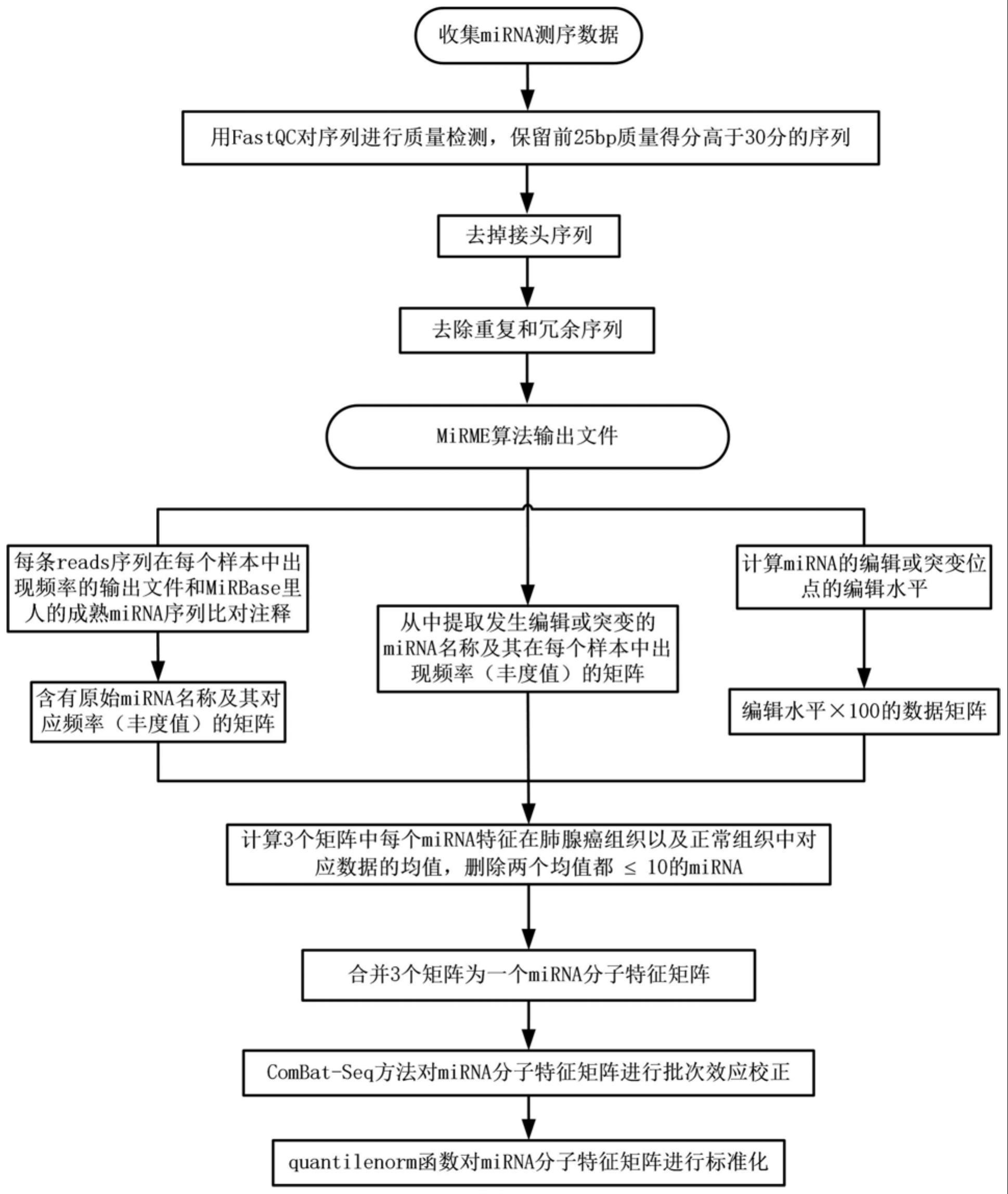
本发明涉及生物信息学、机器学习领域。具体来说,第一,本专利获得了多种microrna(mirna)的分子特征,包括mirna的丰度、mirna编辑位点的编辑水平、编辑后mirna的丰度;第二,本专利使用combat-seq算法对多批次的小rna测序数据进行批次效应校正;第三,本专利找到了3个mirna,即hsa-mir-135b-5p,hsa-mir-210-3p和hsa-mir-182_48u是识别肺腺癌的重要特征,多种机器学习分类算法可以在由以上三个特征构成的数据集中获得100%的预测准确性,并使用dfl算法构建了一种基于上述3种mirna丰度值的肺腺癌机器学习分类模型。
背景技术:
1、已有研究发现,肺腺癌的发生和基因突变有着极大的相关性。
2、microrna(mirna)是一种在动植物体内广泛存在的内源性单链非编码rna,长约21nt~24nt。mirna通常是在核内转录,经过一系列的剪切处理后输送到细胞质中。随后,经核酸酶dicer将其剪切产生约为22个核苷酸长度的成熟mirna。成熟的mirna通过碱基配对结合与其互补的mrna,介导mrna降解或者抑制其翻译,从而起到调控基因表达的作用。有研究发现,mirna的差异表达有可能影响致癌途径的下游靶点,从而参与癌症的发展。也有研究表明mirna的表达在癌症病人与正常人之间存在着显著差异,由此可以作为生物标志物区分癌组织和正常组织,甚至利用其靶标的与癌症相关的基因开发新的治疗方案。
3、随着测序技术的高速发展,大量的mirna高通量测序数据不断累积,再加上,癌症是一种多基因调控的复杂疾病,如何从海量的、复杂的数据中提取重要的信息成为一个难题。机器学习算法利用各种数学原理、统计学原理和计算机科学技术,使得计算机能够从量级庞大、结果复杂、充满噪音的环境中挖掘深层价值的信息数据。癌症的复杂调控因素正好与机器学习的研究特性相符合,已经为辅助医疗技术的发展,为医疗工作者的诊断、分析和治疗提供了极大的帮助,广泛运用于各种癌症的诊断以及预后评估。
技术实现思路
1、本发明的主要
技术实现要素:
是(1)利用discrete function learning(dfl)算法找到三个mirna,即hsa-mir-135b-5p,hsa-mir-210-3p和hsa-mir-182_48u是识别肺腺癌的重要特征,并构建了一种基于这三个mirna的高通量测序丰度及编辑水平用于预测肺腺癌的机器学习分类模型,如表1所示。
2、表1dfl机器学习构建的分类器模型
3、
4、随后用五种常见的分类算法k-邻近(knn)、决策树(c4.5)、随机森林(rf)、支持向量机(svm)和dfl,在这三个mirna为特征的数据集(训练集316个样品,测试集79个样品)上构建分类模型,均获得了100%的预测准确性。这些结果提示我们构建的这些机器学习模型可以用于肺腺癌的辅助诊断。
5、(2)发明一种校正和标准化不同批次小rna测序数据的方法,该方法克服了不同批次测序数据的批次效应对构建机器学习模型的影响。用combat-seq算法对经过过滤后的多种mirna分子特征,即原始mirna丰度值、mirna m/e sites的编辑水平、发生编辑后的mirna丰度值,矩阵进行批次效应的校正,并利用quantilenorm算法对批次效应校正后的数据进行标准化。校正和标准化不同批次数据前后的pca分析结果如图2所示。
技术特征:
1.一种基于多种microrna分子特征的肺腺癌机器学习分类模型,其特征在于:
2.根据权利要求1所述,对数据进行处理,批次效应校正以及进行标准化的方法。
3.根据权利要求1所述,本专利采用dfl算法找到的3个识别肺腺癌的mirna特征(即hsa-mir-135b-5p,hsa-mir-210-3p,hsa-mir-182_48u),以及以此构建机器学习分类模型的方法。
技术总结
本发明公开了一种基于多种microRNA(miRNA)分子特征的肺腺癌机器学习分类模型,其方法为:一、分析肺腺癌和癌旁正常组织样本的miRNA高通量测序数据,获取成熟的miRNA在测序文件中的丰度值,得到miRNA的编辑或突变位点编辑水平,获取miRNA编辑后的丰度值;二、对由丰度值和编辑水平构成的矩阵进行批次效应校正和标准化处理;三、用DFL算法对二中得到的数据构建机器学习预测模型,可以准确地区分肺腺癌样品和正常对照,准确率为100%。DFL算法选出了3个miRNA分子特征,分别是hsa‑miR‑135b‑5p、hsa‑miR‑210‑3p、hsa‑miR‑182_48u;四、使用K‑邻近、决策树、随机森林、支持向量机,4种分类算法在DFL算法选出的包含上述3个miRNA数据特征的数据子集构建机器学习预测模型,也可以准确区分肺腺癌样品和正常对照,准确率均为100%。
技术研发人员:郑云,毛淳怡,李宛燃,郭仕勇
受保护的技术使用者:云源智鑫生物科技(昆明)有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!