基于人工智能的数据处理系统、方法及存储介质与流程
本发明涉及计算机,具体涉及基于人工智能的数据处理系统、方法及存储介质。
背景技术:
1、人工智能缩写为ai,亦称智械、机器智能,指由人制造出来的可以表现出智能的机器。通常人工智能是指通过普通计算机程序来呈现人类智能的技术。该词也指出研究这样的智能系统是否能够实现,以及如何实现。人工智能的研究是高度技术性和专业的,各分支领域都是深入且各不相通的,因而涉及范围极广。
2、当前人工智能自学习模式可以在大型计算机和计算机集群中实现,但是算法极为复杂,而且需要前期建立众多的数据模型和大量原始数据的输入。人工智能与互联网当前的结合,都是由终端设备采集使用者的输入数据与云端人工智能数据处理中心进行交互,由云端人工智能数据处理中心给出响应,再回传给终端设备,做出响应的反馈。或者是将部分简单的人工智能算法嵌入终端设备,实现部分简单的人工智能应用功能。
3、当前人工智能与对于数据信息进行理解存在较为严重的误区,由于各个词汇的组合方式不同,理解的释义也有较大的区别,就会导致在检索过程中错在这检索误区。
技术实现思路
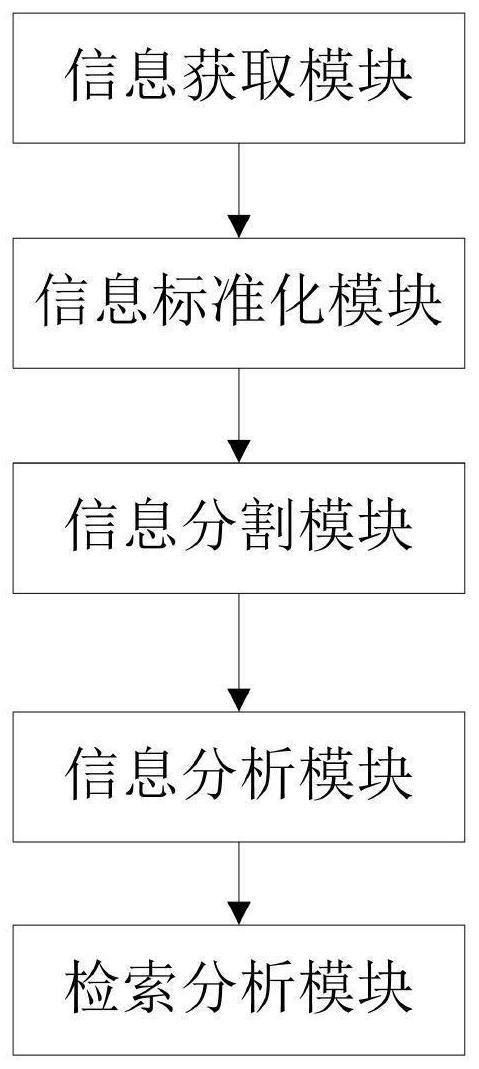
1、为解决上述技术问题,本发明提供一种基于人工智能的数据处理系统,所述的基于人工智能的数据处理系统包括:
2、信息获取模块,其用于获取数据信息;
3、信息标准化模块,其用于对数据信息进入读取,并将数据信息进行转化成一种预先设置类型的数据信息文本;
4、信息分割模块,其用于接收数据信息文本并对数据信息文本进行分割获得短文本,将短文本集合获得短文本集{ai},其中i为各个短文本的编号;
5、信息分析模块,其用于通过各个短文本集的干扰权重wij,其中,j为第j个短文本对短文本i的选用权重干扰,计算获得短文本的选用值j≠i,|j-i|干扰距离,获得max{si}记入信息文本集,并以max{si}为中心进行前后扩展,以非交叉方式提取短文本,并计算短文本的选用值,并选用值的最大值记入信息文本集,直至完成整个数据信息文本。
6、优选的:所述的信息获取模块通过对大数据解读或通过各个采集终端采集获得。
7、优选的:对信息文本集中的短文本进行信息释义融合获得释义文本,释义文本组合获得信息集。
8、优选的:数据信息包括图片信息、语音信息、文字信息、位置信息、外界信息中的一种或多种组合。
9、优选的:所述的数据信息文本的分割方法包括将数据信息文本按照一个预先设置文本词汇集进行对比,对数据信息文本按照文本词汇集进行切词获得各个短文本ai,并将这些短文本汇集在一起获得短文本集{ai}。
10、优选的:所述基于人工智能的数据处理系统还包括检索分析模块,检索分析模块用于获取各个数据信息,并进行处理获得各个信息集tt中的各个释义文本或者短文本,其中,t为各个数据信息的排序,对信息集tt进行重合项分析,并标定出非重合项,并将各个非重合项定义为近义项,并计算各个近义项与检索项的近似值at,并按照近似值at从大到小进行推送。
11、优选的:所述的近似值的计算方法为对近义项进行切词,获得具有短文本的近义项文本集{mm},其中,m为近义项中各个短文本的排序;然后对检索项进行切词,获得具有短文本的检索项文本集{nn},其中,n为检索项中各个短文本的排序,则计算近义项与检索项各个短文本之间的近似值cmn为检索项中第n项短文本和近义项中第m项短文本的近似度。
12、优选的:所述的近似度判定为各个短文本的意义近似程度,通过两个短文本查找一个预先设置的文本-相似度信息表获得。
13、本发明还提供一种基于人工智能的数据处理方法,应用于上述所述的基于人工智能的数据处理系统,所述的基于人工智能的数据处理方法包括如下步骤:
14、s1、获取数据信息;
15、s2、对数据信息进入读取,并将数据信息进行转化成一种预先设置类型的数据信息文本;
16、s3、接收数据信息文本并对数据信息文本进行分割获得短文本,将短文本集合获得短文本集{ai},其中,i为各个短文本的编号;
17、s4、通过各个短文本集的干扰权重wij,其中,j为第j个短文本对短文本i的选用权重干扰,计算获得短文本的选用值j≠i,|j-i|干扰距离;
18、s5、获得max{si}记入信息文本集;
19、s6、以max{si}为中心进行前后扩展,以非交叉方式提取短文本,并计算短文本的选用值;
20、s7、将选用值的最大值记入信息文本集,直至完成整个数据信息文本。
21、本发明还提供一种计算机可读存储介质,其上存储有计算机程序,程序被处理器执行时,实现基于人工智能的数据处理方法的步骤。
22、优选的:
23、本发明的技术效果和优点:通过对数据信息进行统一转换进行处理,提高了处理效率,通过对数据信息文本进行分割获得短文本,然后通过干扰权重计算选用值,然后通过选用值进行理解,选用值的各个短文本之间的相互干扰,可以最准确的对数据信息进行切词,通过切词获得各个短文本集,对各个短文本集进行检索,筛除了大量的非必要数据,减少了数据输出量。通过对各个短文本进行近似度评价,可以进行模糊检索,检索范围宽,避免了近义词检索造成检索错漏,同时减少了检索工作量。
技术特征:
1.基于人工智能的数据处理系统,其特征在于,所述的基于人工智能的数据处理系统包括:
2.根据权利要求1所述的基于人工智能的数据处理系统,其特征在于,对信息文本集中的短文本进行信息释义融合获得释义文本,释义文本组合获得信息集。
3.根据权利要求1所述的基于人工智能的数据处理系统,其特征在于,数据信息包括图片信息、语音信息、文字信息、位置信息、外界信息中的一种或多种组合。
4.根据权利要求1所述的基于人工智能的数据处理系统,其特征在于,所述的数据信息文本的分割方法包括:将数据信息文本按照一个预先设置文本词汇集进行对比,对数据信息文本按照文本词汇集进行切词获得各个短文本ai,并将这些短文本汇集在一起获得短文本集{ai}。
5.根据权利要求2所述的基于人工智能的数据处理系统,其特征在于,所述基于人工智能的数据处理系统还包括检索分析模块,检索分析模块用于获取各个数据信息,并进行处理获得各个信息集tt中的各个释义文本,其中,t为各个数据信息的排序,对信息集tt进行重合项分析,标定出非重合项,将各个非重合项定义为近义项,计算各个近义项与检索项的近似值at,并按照近似值at从大到小进行推送。
6.根据权利要求5所述的基于人工智能的数据处理系统,其特征在于,所述的近似值的计算方法为对近义项进行切词,获得具有短文本的近义项文本集{mm},其中,m为近义项中各个短文本的排序;然后对检索项进行切词,获得具有短文本的检索项文本集{nn},其中,n为检索项中各个短文本的排序,则计算近义项与检索项各个短文本之间的近似值cmn为检索项中第n项短文本和近义项中第m项短文本的近似度。
7.根据权利要求6所述的基于人工智能的数据处理系统,其特征在于,所述的近似度判定为各个短文本的意义近似程度,通过两个短文本查找一个预先设置的文本-相似度信息表获得。
8.一种基于人工智能的数据处理方法,应用于权利要求1-7任一项所述的基于人工智能的数据处理系统,其特征在于,所述的基于人工智能的数据处理方法包括如下步骤:
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,程序被处理器执行时,实现基于人工智能的数据处理方法的步骤。
技术总结
本发明涉及计算机技术领域,具体关于基于人工智能的数据处理系统、方法及存储介质。所述的基于人工智能的数据处理系统的技术方案包括:信息获取模块用于获取数据信息。信息标准化模块用于对数据信息进入读取,并将数据信息进行转化成一种预先设置类型的数据信息文本。信息分割模块进行分割获得短文本,将短文本集合获得短文本集。信息分析模块用于通过各个短文本集的干扰权重并计算获得短文本的选用值,以非交叉方式提取短文本,计算短文本的选用值,并选用值的最大值记入信息文本集,直至完成整个数据信息文本。通过对数据信息文本进行分割获得短文本,然后通过计算选用值,可以筛除了大量的非必要数据信息,减少了数据输出量。
技术研发人员:徐坚,邓启明
受保护的技术使用者:杭州再启信息科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!