一种基于基层治理的自然语言数据查询方法与流程
本发明涉及一种自然语言数据查询方法,应用于基层社会治理、智慧数字办公、大数据处理等领域。
背景技术:
1、传统的条件查询方式需要技术人员在页面上预先设置支持查询的条件组件,而随着条件的增加,条件组合的难度也随之增大,因此,很难实现精准的组合查询,例如:条件之间的逻辑管理问题,是采用“并且”还是“或者”的方式来处理。为了实现通用条件查询,需要设计一个复杂且操作繁琐的功能,因此对用户使用体验来说增加了学习和操作门槛。例如当基层工作者需要查询每个月公示高龄老人高龄津贴的信息时,他们需要在系统上筛选出年龄满80岁且是上个月首次申领津贴的居民。采用现有的查询方式时,首先,需要在搜索条件中输入年龄为80,然后再选择津贴申领状态为首次申领。如果还需要按性别或辖区分类,还需要对性别和辖区进行搜索。随着搜索条件的增加,操作变得越来越不方便。此外,还需要返回固定的列,如姓名、年龄、性别、身份证、家庭住址、申领状态等。在传统的数据查询系统中,无法灵活地组装条件和返回列。
技术实现思路
1、本发明要解决的技术问题是:多条件组合查询不便利、调取数据困难、耗时长等问题。
2、为了解决上述技术问题,本发明的技术方案是提供了一种基于基层治理的自然语言数据查询方法,其特征在于,包括以下步骤:
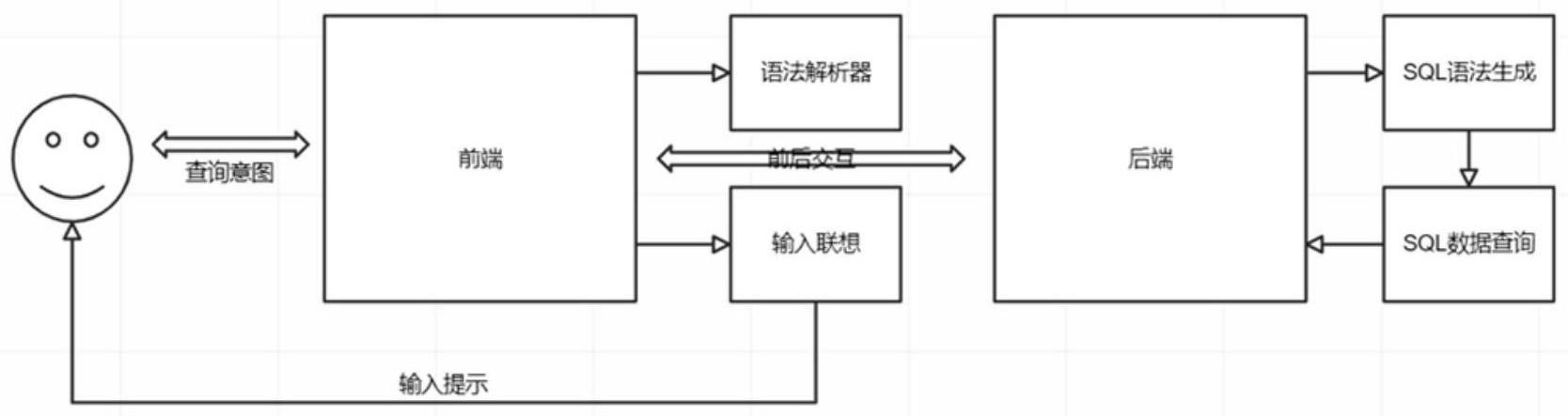
3、步骤1、前端根据不同的查询需求初始化对应的数据字段、数据条件、快捷条件、条件逻辑关系、聚合词、分组词、语气词;
4、步骤2、前端将数据字段与数据条件组合形成词条放入字典树,将数据字段与聚合词组合形成词条放入语义字典树,将数据字段与分组词组合形成词条放入语义字典树,将快捷条件、逻辑关系、语气词直接放入语义字典树中,最终形成语义字典树,语义字典树中的每个叶子节点存储用于表示词条类型的type值以及用于表示词条信息的ext值;
5、步骤3、前端输入框在用户输入文本的同时,使用语义字典树特有的树形结构通过滑动窗口算法实时验证输入文本语义的正确性;用户在输入框输入意图语句后,前端实时地使用语义字典树的特性,将当前匹配到的树节点下所有叶子节点遍历生成联想补全的文本列表,用户按提示的联想文本进行鼠标点击选择或输入,直到用户输入完整表达查询意图的语句;
6、步骤4、前端对用户输入语义检查正确性通过后,将输入文本进行结构化解析,按每个关键词匹配得到的type值和ext值,并通过这两个属性分类,组成结构化表示的查询意图的参数,将此参数做为后端接口入参传递给后端接口;
7、步骤5、后端取得查询意图参数,进行查询sql生成,将按type值和ext值分为查询字段/查询聚合、查询表、查询条件、查询分组这四个数组;
8、步骤6、后端将步骤5获得的四个数组按照sql语法格式进行查询字段拼接、聚合字段拼接、条件拼接、分组拼接,通过sql语法树拼接得到完整的sql语句;
9、步骤7、后端取得mysql连接后,将sql执行,得到resultset结果集,依次循环遍历结果集生成接口输出参数,输出参数结构按行拼装,第一行为字段标题,第二行开始为数据行,列数量按查询意图动态生成;
10、步骤8、前端得到接口输出参数后,动态渲染,将第一行进行列表标题渲染,从第二行开始做为数据内容渲染。
11、优选地,步骤2中,所述词条类型包括数据字段、数据条件、聚合词、条件逻辑、分组词、语气词、快捷条件。
12、优选地,步骤2中,所述词条类型为数据条件、分组词、聚合词的叶子节点结构是:{name:词条名称,field:字段名称,value:词条信息};
13、所述词条类型为数据字段、逻辑关系、语气词、快捷条件的叶子节点的结构是:{name:词条名称,value:词条信息}。
14、优选地,步骤3中,所述滑动窗口算法包括以下步骤:
15、步骤301、创建变量left以及变量right,其中,left默认为0,指向输入文本的索引下标0;right默认为1,指向输入文本的索引下标1;
16、步骤302、获取输入文本位于left和right之间的文本字符去语义字典树中匹配:如果匹配不上,则将right指向的文本索引下标加1,继续将输入文本位于left和right之间的文本字符去语义字典树中匹配,直至能在语义字典树中匹配上一条正确的叶子节点;如果匹配上,则将left指向的文本索引下标设置为right指向的文本索引下标,将right指向的文本索引下标加1,返回步骤302,直到遍历语义字典树的叶子节点找到所有能匹配上的叶子节点。
17、优选地,步骤3中,过滑动窗口算法实时验证输入文本语义的正确性时,通过currentnode变量记录每次滑动过程中right变量指向的文本索引下标对应的字符在语义字典树中的节点,该节点即为所述当前匹配到的树节点,则根据当前匹配到的树节点继续往下遍历找到语义字典树中的每个叶子节点,从当前匹配到的树节点到叶子节点中的字符内容就是需要联想提示的语义文本列表。
18、本发明通过人类的语言向机器发出指令,机器理解语义和语义分段识别出意图,并将其转换为sql语言查询数据库,最终完成一次自然语言查询数据的操作。在使用过程中不用关注条件之间的组合,联想方式能带着用户输入一段一段的完成查询的语义编写。采用本发明所公开的技术方案后,可以让基层工作人员使用自然语言进行查询,例如输入“查询首次申领津贴的高龄老人,返回姓名、年龄、性别、身份证、家庭住址、申领状态”这样的语句,即可获得所需的数据,避免了传统系统繁琐的操作。
19、本发明利用字典树、滑动窗口算法和sql查询语法树构建,实现了输入查询意图的识别和转换为查询sql搜索数据。用户可以通过联想式的自然语言输入查询意图,灵活组合各个查询条件逻辑。只需输入所想的查询意图,即可获得所需的数据。相比传统的多条件组合查询方式,本发明无需繁琐的条件组合操作,降低了学习门槛和操作难度,实现了便捷的数据搜索效果。
技术特征:
1.一种基于基层治理的自然语言数据查询方法,其特征在于,包括以下步骤:
2.如权利要求1所述的一种基于基层治理的自然语言数据查询方法,其特征在于,步骤2中,所述词条类型包括数据字段、数据条件、聚合词、条件逻辑、分组词、语气词、快捷条件。
3.如权利要求2所述的一种基于基层治理的自然语言数据查询方法,其特征在于,步骤2中,所述词条类型为数据条件、分组词、聚合词的叶子节点结构是:{name:词条名称,field:字段名称,value:词条信息};
4.如权利要求1所述的一种基于基层治理的自然语言数据查询方法,其特征在于,步骤3中,所述滑动窗口算法包括以下步骤:
5.如权利要求4所述的一种基于基层治理的自然语言数据查询方法,其特征在于,步骤3中,过滑动窗口算法实时验证输入文本语义的正确性时,通过currentnode变量记录每次滑动过程中right变量指向的文本索引下标对应的字符在语义字典树中的节点,该节点即为所述当前匹配到的树节点,则根据当前匹配到的树节点继续往下遍历找到语义字典树中的每个叶子节点,从当前匹配到的树节点到叶子节点中的字符内容就是需要联想提示的语义文本列表。
技术总结
本发明公开了一种基于基层治理的自然语言数据查询方法,通过人类的语言向机器发出指令,机器理解语义和语义分段识别出意图,并将其转换为SQL语言查询数据库,最终完成一次自然语言查询数据的操作。在使用过程中不用关注条件之间的组合,联想方式能带着用户输入一段一段的完成查询的语义编写。本发明利用字典树、滑动窗口算法和SQL查询语法树构建,实现了输入查询意图的识别和转换为查询SQL搜索数据。用户可以通过联想式的自然语言输入查询意图,灵活组合各个查询条件逻辑。只需输入所想的查询意图,即可获得所需的数据。相比传统的多条件组合查询方式,本发明无需繁琐的条件组合操作,降低了学习门槛和操作难度,实现了便捷的数据搜索效果。
技术研发人员:闫沈,胡磊,郭斌,匡鹏,姚建平,郭京洁
受保护的技术使用者:万达信息股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!