一种基于python语言的自动爬取网页数据的方法
本发明涉及数据爬取领域,特别涉及一种基于python语言的自动爬取网页数据的方法。
背景技术:
1、互联网信息技术的高速发展促使人类社会的数据种类和规模以前所未有的速度增长,海量的数据背后隐藏着巨大价值。随着政务系统数据的逐步公开,我国水雨情信息网站上公布的大江大河实时水情(包括日尺度的全国河流水位及流量数据)、大型水库实时水情(包括日尺度的全国水库水位、蓄水量和入库流量数据)、重要站点实时雨情(包括日尺度全国重要站点的降雨量)、珠江水利委员会公布的实时水情和实时咸情(包括珠江流域重要站点的日尺度水位、流量、入库/出库流量、库容和盐度等)、国家地表水水质自动监测实时数据发布系统公布的水质数据(包括小时和月尺度的九项水质监测指标浓度)等不断实时更新,这些数据对于高校研究所的科研人员来说无疑是宝贵的资源。然而这些数据零散地分布在各个网站中,网站上的信息数量庞大且复杂,网站均不具备历史数据的储存功能,如何从多样化数据中准确收集到有效信息,并进一步在海量数据中挖掘蕴藏的重要价值,是当前首要解决的问题。因此,研发一个能自动实时获取网站数据方法显得尤其重要,并保证获取数据的准确性和便捷性,对于节省人力资源和时间成本具有显著效益,对于进一步开展后续科研工作也具有重要意义。
技术实现思路
1、为了克服现有技术的上述缺点与不足,本发明的目的在于提供一种基于python语言的自动爬取网页数据的方法,用以实现准确、快速、实时自动获取互联网上的海量数据,将使得科研工作便捷化、高效化。
2、本发明的目的通过以下技术方案实现:
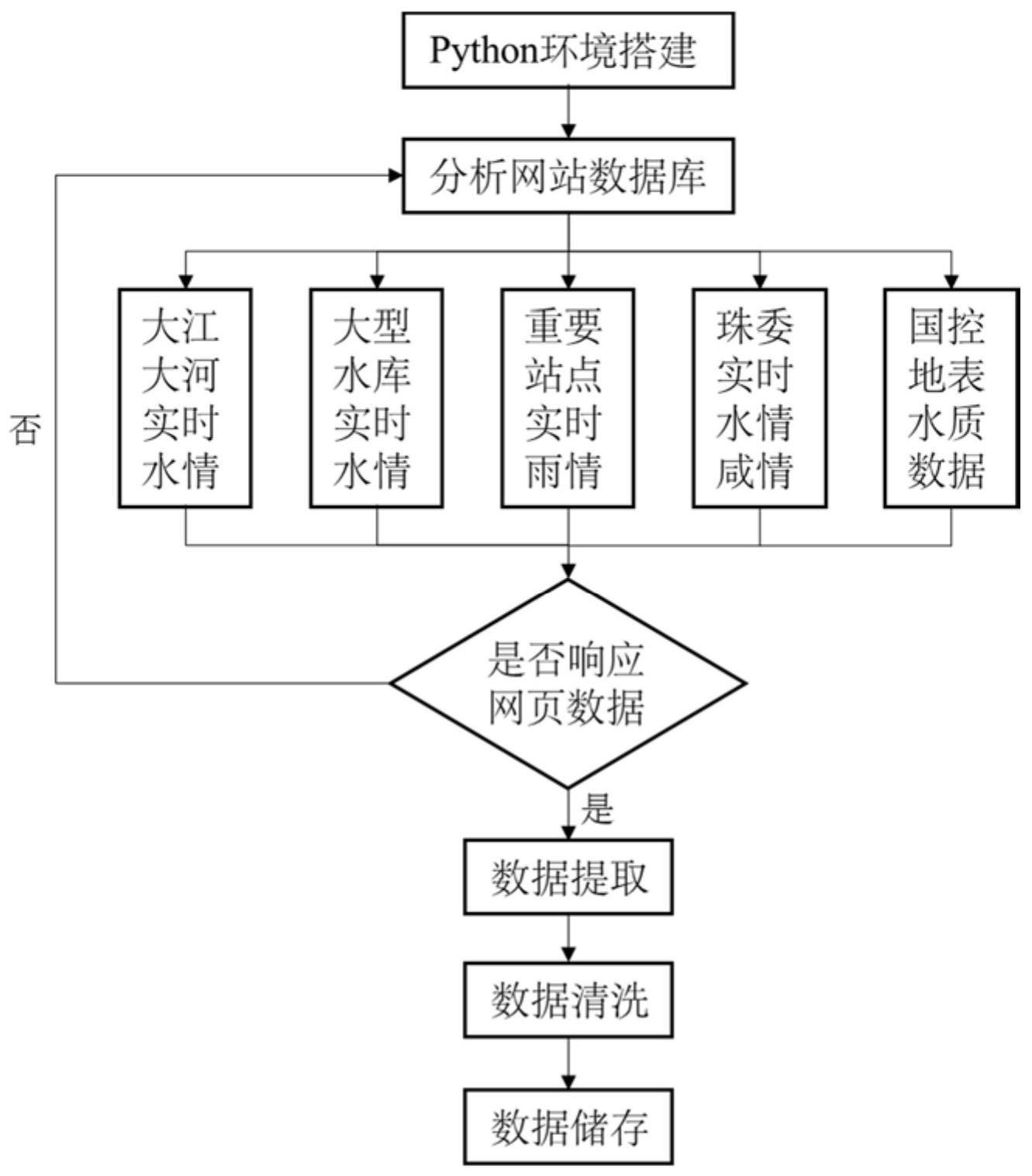
3、一种基于python语言的自动爬取网页数据的方法,包括如下步骤:
4、s1搭建python语言环境;
5、s2选取目标网址,根据数据结果,确定目标网站的数据库储存格式,并获取目标网站的headers和response;
6、s3确定目标网站的存储指定数据库,构建爬取目标网站的模型;
7、s4在运行环境处于正常联网状态,运行该模型,进行数据爬取;
8、s5根据数据响应状态,调整目标网站数据;
9、s6对成功响应的网页数据进行清洗整理,删除或替代无效值和缺失值;,输出数据结果并保存。
10、进一步,对于网页数据的无效值进行删除,对于缺失值和异常值,用0或者空值代替。
11、进一步,所述数据响应状态包括如下:
12、200ok:表示请求成功,并且服务器已经成功返回请求的数据;
13、301moved permanently:表示请求的网页已永久移动到新位置,会伴随一个新的url返回,爬虫根据这个url进行重定向;
14、302found:表示请求的网页已暂时移动到新位置,未来请求的url可能会发生变化;
15、403forbidden:表示服务器理解请求,但是拒绝执行;
16、404not found:表示请求的网页不存在或无法找到;
17、500internal server error:表示服务器遇到了意外错误,无法完成请求;
18、503service unavailable:表示服务器当前无法处理请求。
19、进一步,还包括,根据不同的响应码和响应状态,调整爬取方式,具体为:
20、处理成功响应:如果响应状态码为200,表示请求成功,处理获取到的数据;
21、处理重定向:如果响应状态码为301或302,表示请求的网页已经被永久或暂时重定向到新的位置。通过解析响应中的location字段获取新的url,并使用新的url进行后续的数据请求和处理;
22、处理页面不存在:如果响应状态码为404,表示请求的页面不存在,根据业务需求采取不同的策略;
23、处理权限问题:如果响应状态码为403,表示服务器理解请求,但拒绝执行,由于权限不足;在这种情况下,需要检查请求头部,确保包含必要的认证信息,或者尝试以合法用户的身份进行访问;
24、处理服务器错误:如果响应状态码为500或503,表示服务器遇到了错误或暂时无法处理请求,在这种情况下,等待一段时间后重新尝试请求,或者根据网站提供的错误信息进行修复;
25、合理处理重试和错误:对于请求过程中遇到的异常情况,设置合理的重试机制,并记录日志以便后续分析和排查;
26、更新爬虫规则:如果目标网站的数据响应状态发生了变化,需要更新爬虫规则,以确保爬虫能够正确地处理新的状态码和异常情况。
27、进一步,构建爬取模型,具体过程为:
28、网站分析:获取目标网站的结构、布局和内容,进一步获得网站的url结构、页面关系、数据呈现方式及反爬虫机制,确定爬取入口点、数据抽取方法和避免反爬虫机制;
29、确定数据源和数据类型:确定目标网站上的目标数据源和数据类型;
30、选择合适爬取工具或库:根据目标网站的需求和技术栈,选择适合的爬取工具或库;
31、编写爬虫代码:根据网站分析的结果和选定的爬取工具,编写爬虫代码。根据目标数据源的不同,需要编写不同的爬取逻辑;
32、处理反爬虫策略。
33、进一步,若反爬虫策略为ip限制、验证码及请求频率限制,则对应采用代理ip、随机延迟及模拟用户策略绕过上述反爬虫策略。
34、进一步,根据headers和api接口识别网站所使用的数据库类型和版本,进一步获得数据库储存格式。
35、进一步,所述python版本应高于3.6,并安装所需软件库。
36、本发明旨在高效便捷地获取水文、气象、环境等方面的网络公开数据,利用requests和selenium框架获取网址网页信息,对网页信息进行过滤与筛选,剔除无效数据,保留有用数据,并储存在本地服务器,可为后续科研工作提供基础数据支撑。
37、与现有技术相比,本发明具有以下优点和有益效果:
38、本发明可以实现多种不同网址的数据获取、数据清洗及整理,具有实时高效便捷的特点,助于后续科学研究的开展。基于python语言开发和封装,获取初始网页url,解析url,获取相应信息,并过滤不必要的字符和空值,导出成可供查看与编辑的文件,并存储在对应文件夹中,为科研工作者、决策者、管理者提供实时准确数据源,节省大量人力资源和时间。
技术特征:
1.一种基于python语言的自动爬取网页数据的方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的方法,其特征在于,对于网页数据的无效值进行删除,对于缺失值和异常值,用0或者空值代替。
3.根据权利要求1所述的方法,其特征在于,所述数据响应状态包括如下:
4.根据权利要求1所述的方法,其特征在于,还包括,根据不同的响应码和响应状态,调整爬取方式,具体为:
5.根据权利要求1所述的方法,其特征在于,构建爬取模型,具体过程为:
6.根据权利要求5所述的方法,其特征在于,若反爬虫策略为ip限制、验证码及请求频率限制,则对应采用代理ip、随机延迟及模拟用户策略绕过上述反爬虫策略。
7.根据权利要求1所述的方法,其特征在于,根据headers和api接口识别网站所使用的数据库类型和版本,进一步获得数据库储存格式。
8.根据权利要求1所述的方法,其特征在于,所述python版本应高于3.6,并安装所需软件库。
技术总结
本发明公开了一种基于python语言的自动爬取网页数据的方法,包括如下步骤:搭建python语言环境;选取目标网址,根据数据结果,确定目标网站的数据库储存格式,并获取目标网站的headers和response;确定目标网站的存储指定数据库,构建爬取目标网站的模型;在运行环境处于正常联网状态,运行该模型,进行数据爬取;根据数据响应状态,调整目标网站数据;对成功响应的网页数据进行清洗整理,删除或替代无效值和缺失值;输出数据结果并保存。本发明可以实现准确、快速、实时自动获取互联网上的海量数据。
技术研发人员:王兆礼,蒋杰,赖成光
受保护的技术使用者:华南理工大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!