基于语义流图挖掘的系统日志异常检测方法
本发明属于信息安全,进一步涉及异常检测方法,具体为一种基于日志语义信息提取的系统异常检测方法,可用于主流计算机系统的异常检测和识别。
背景技术:
1、系统日志记录了系统的状态信息和运行情况,包含系统的异常信息,通常由静态文本和变量组成,是了解系统状态的宝贵资源,通过分析系统日志包含的信息,能够分析系统的异常、定位系统故障点,进而提高系统的安全性和可靠性。日志文件与自然语言编写的文档并不相同,一是日志中相似的消息不断重复,这是由于程序通常以循环的方式执行,导致事件重复发生,并且大多数日志都由一组数量有限的日志打印语句生成,即代码中预定义的函数将格式化字符串写入输出并生成日志消息;二是日志中的一些消息具有高度的相关性,这是因为系统程序的执行遵循某些控制流,生成日志的组件之间彼此链接。目前绝大多数系统产生的日志都是半结构化或者非结构化的,不同系统之间的日志格式和类型都有所不同,因此,即使日志包含了系统重要事件的信息,要想对日志进行高效解析,提取日志中的事件信息进行异常检测也成为了一个难点。除了半结构化日志格式复杂难以解析和提取有效信息外,针对系统日志进行异常检测还面临着日志数据量庞大,日志中的垃圾数据和噪声的影响。
2、目前主流的针对系统日志进行异常检测方法主要包括以下步骤:1)对系统日志进行解析,提取日志中的模板;2)将日志模板构建为日志序列,提取日志模板序列中的特征向量;3)利用机器学习或深度学习的方法进行异常检测。但是面对海量非结构化和半结构化的系统日志,进行日志解析提取日志模板对日志解析器提出了挑战,此外,日志解析在异常检测系统中具有较大的时空消耗,导致异常检测任务效率低下。更重要的是,存在于系统日志中的噪声数据难以进行去除,这将直接影响异常检测的准确率。因此针对系统日志进行异常检测时如何克服日志解析带来的效率低下以及日志噪声对异常检测准确率的影响成为了亟待解决的难题。
技术实现思路
1、本发明目的在于针对上述现有技术的不足,提出一种基于语义流图的系统日志异常检测方法,解决现有技术针对海量非结构化日志在异常检测任务中日志噪声去除难、系统变更导致日志语句变更等问题。在进行基于日志的异常检测任务过程中,日志噪声的产生主要有以下几个原因:1)在收集和传输日志的过程中,由于传输延迟或数据丢失导致的日志数据混乱缺失;2)系统或应用程序重复记录事件信息;3)日志解析过程中,由于解析器的不稳定性导致日志模板的错误识别。此外,计算机系统在交付过程中的升级导致代码中的日志打印语句随之改变,由此产生的日志模板更新也会导致异常检测的误报率提高。本发明能够通过提取日志语句的语义向量将其作为语义流图的节点特征,通过图卷积神经网络模型对语义流图进行训练,能有效解决日志噪声对异常检测的影响并进一步利用日志语句之间的空间结构信息提高异常检测的准确性。
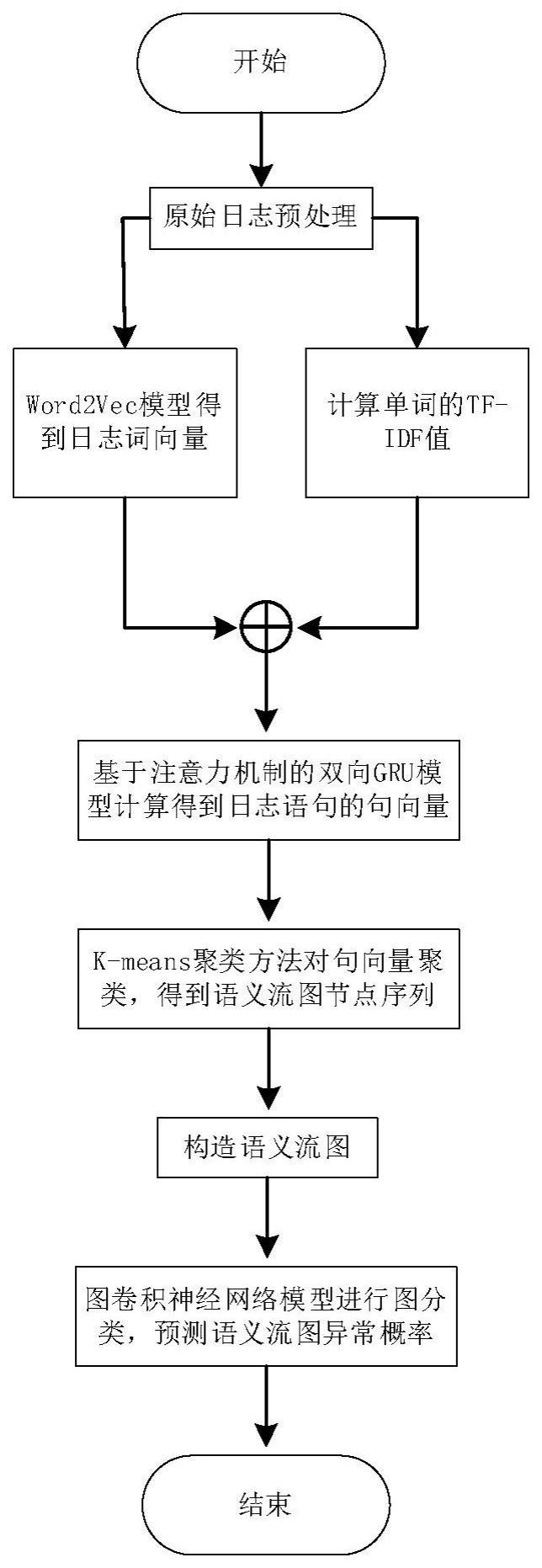
2、实现本发明方案的思路是:首先对日志原始语句进行简单的预处理,去除无意义符号和进行分词;其次利用word2vec结合日志语句中单词的重要度进行计算,得到日志语句的词向量,再利用基于注意力机制的双向门控循环单元(gated recurrent unit,gru)网络进行计算得到日志语句的句向量表示;然后采用k-means聚类的方法对日志句向量进行聚类,相似度较高的日志语句划分为同一类,将其视为语义流图的同一节点,将日志序列转换为非去重的节点序列之后,将节点按照序列顺序构造出有向无环图,本发明称为语义流图。最后通过图卷积神经网络对语义流图进行特征提取和训练,实现基于语义流图的系统异常检测。
3、本发明实现上述目的的具体步骤如下:
4、(1)将对原始系统日志进行日志语句分割,去除无意义的符号,保留具有特殊含义的组合单词,得到初始预处理后的系统日志;
5、(2)将初始预处理后的系统日志按照会话或窗口机制划分日志序列,利用word2vec模型将该日志序列中的单词或词组转换为词向量,令第m条日志的第n个单词的词向量为vnm;
6、(3)计算日志语句中单词的词频-逆文档频率tf-idf,其中,第m条日志的第n个单词的tf-idf表示为tmn;
7、(4)将与tmn相结合,根据下式得到最终日志语句单词的向量表示wmn:
8、
9、其中,α表示权重因子;
10、(5)将wmn作为基于注意力机制的双向gru模型的输入,得到包含l条日志序列的句向量集合s={s1,s2,...,sm,...,sl},其中,sm表示第m条日志语句向量;
11、(6)采用k-means聚类方法对集合s中的日志语句向量进行聚类,将日志序列按照聚类结果进行匹配得到节点序列,按照该节点序列顺序构造出节点的有向无环图,最终得到日志序列的语义流图g=(v,e),其中,v表示节点集合,e表示边的集合;
12、(7)使用图卷积神经网络对语义流图g进行特征提取和训练,通过对语义流图中节点特征进行传播和聚合,将其映射到分类标签,得到系统日志异常检测结果。
13、本发明与现有技术相比具有以下优点:
14、第一、由于本发明通过提取日志原始语句的语义,并将其转化为语义流图的形式进行异常检测,故只需要对原始日志进行简单的预处理,无需对原始日志语句进行难度较大且效率低下的日志解析工作,从而极大地提高了异常检测的效率。
15、第二、本发明采用k-means聚类的方法对日志语句向量进行聚类分析,极大地降低了日志噪声对异常检测的影响,同时也解决了在系统交付过程中,由于系统不断更新迭代所带来的日志语句不稳定性的问题。
16、第三、本发明采用语义流图的形式来进行异常检测,图结构能够包含序列所没有的空间结构信息,因此,利用图卷积神经网络模型能够提取语义流图中的节点和边特征以及空间信息特征,对于隐含在空间结构信息中的异常也能进行检测。
技术特征:
1.一种基于语义流图挖掘的系统日志异常检测方法,其特征在于,包括如下步骤:
2.根据权利要求1所述方法,其特征在于:步骤(3)中计算日志语句中单词的词频-逆文档频率tf-idf,实现步骤如下:
3.根据权利要求1所述方法,其特征在于:步骤(5)中基于注意力机制的双向gru模型,所述双向gru模型由前向方向和后向方向的gru组成,其中前向方向的gru从前向后处理序列,后向方向的gru从后向前处理序列;
4.根据权利要求1所述方法,其特征在于:步骤(6)所述采用k-means聚类方法对集合s中的日志语句向量进行聚类,实现如下:
5.根据权利要求1所述方法,其特征在于:步骤(6)得到日志序列的语义流图g=(v,e),具体是将聚类簇中具有相同日志模板的日志语句认为语义流图中的同一节点,并将节点类型与原始日志序列中的日志条目进行匹配,按照日志序列的结构将不同的节点进行连接,构造出有向无环的语义流图,并将日志语句的句向量作为节点特征嵌入语义流图中;其中,表示g的节点集合,表示g中第p个节点vp指向第q个vq的有向边的集合;为正整数。
6.根据权利要求1所述方法,其特征在于:步骤(7)中使用图卷积神经网络对语义流图g进行特征提取和训练,通过对语义流图中节点特征进行传播和聚合,将其映射到分类标签,得到系统日志异常检测结果,实现如下:
技术总结
本发明公开一种基于语义流图挖掘的系统日志异常检测方法,主要解决了现有技术针对海量非结构化日志在异常检测任务中日志噪声去除难、系统变更导致检测效果不佳的问题。包括:1)对日志原始语句进行预处理,去除无意义符号并进行分词;2)利用Word2Vec结合日志语句中单词的重要度计算日志语句的词向量;3)利用基于注意力机制的双GRU网络,得到日志语句的句向量表示;4)对日志句向量进行聚类,将相似度高的日志语句划分为一类,构造语义流图;5)通过图卷积神经网络对语义流图进行特征提取和训练,实现异常检测。本方法能够有效解决日志噪声对异常检测的影响,并利用日志语句之间的空间结构信息提高异常检测的准确性。
技术研发人员:李腾,魏少博,林炜国,彭春蕾,李思琦,崔金玉,李德彪
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!