基于标签计算的数据存储方法、系统、设备及介质与流程
本发明涉及数据存储,特别涉及一种基于标签计算的数据存储方法、基于标签计算的数据存储系统、电子设备及存储介质。
背景技术:
1、从hadoop(一种分布式系统基础架构)诞生到现在,数据的存储格式经历了几代的发展,从最初的txt file(一种存储格式),到后来的sequence file(另一种存储格式)和rcfile(另一种存储格式),再到现在的orc(一种列式存储格式)和parquet(另一种列式存储格式)等列式存储文件,数据的存储格式发生了翻天覆地的变化,更好的性能、更高的压缩比。然而数据组织方式的发展却相当缓慢。
2、hive(一个数据仓库工具)提出了分区的概念,利用某几个column(数据表中的列)作为分区值来组织数据,能够有效地过滤掉无需读取的数据,这种分区在物理存储上反映出来的就是按照文件夹进行分区(组织)数据。利用文件夹来组织与hdfs(hadoopdistributed file system,分布式文件系统)的文件系统结构有天然的亲和性,因此这一方式也一直被沿用下来。
3、然而,随着大数据和云计算的结合,越来越多的底层存储系统从分布式文件系统转向云上的存储系统。而这种利用文件夹来组织数据的方式遇到了极大的挑战,随着数据量的不断增长,传统的文件系统和关系型数据库无法满足高容量、高性能和高可扩展性的要求,如容易受到数据库表字段的限制影响,无法频繁新增和删除标签。
技术实现思路
1、本发明要解决的技术问题是为了克服现有技术中上述的缺陷,提供一种基于标签计算的数据存储方法、基于标签计算的数据存储系统、电子设备及存储介质。
2、本发明是通过下述技术方案来解决上述技术问题:
3、本发明是通过下述技术方案来解决上述技术问题:
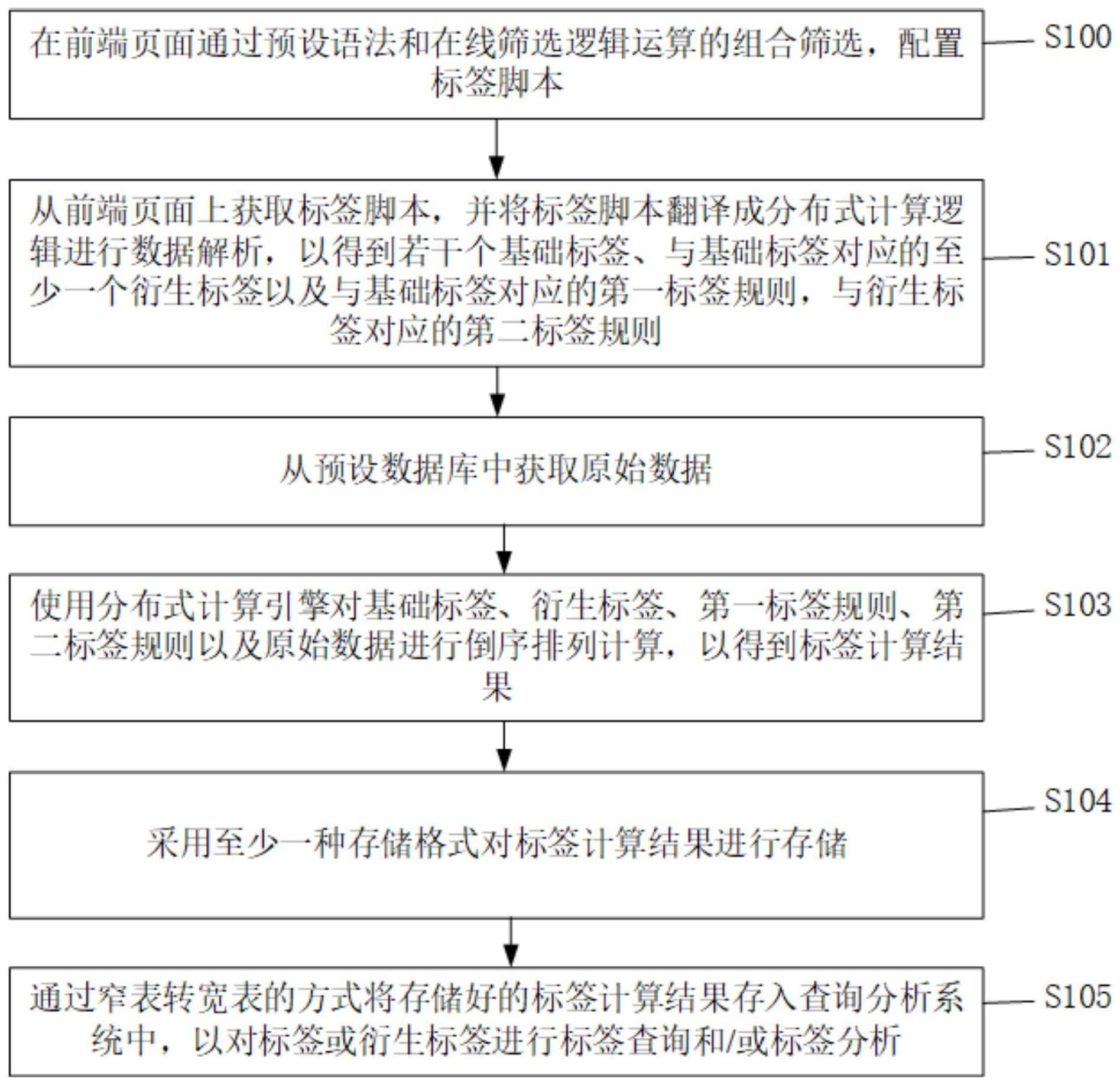
4、本发明提供一种基于标签计算的数据存储方法,所述方法包括:
5、从前端页面上获取标签脚本,并将所述标签脚本翻译成分布式计算逻辑进行数据解析,以得到若干个基础标签、与所述基础标签对应的至少一个衍生标签以及与所述基础标签对应的第一标签规则,与所述衍生标签对应的第二标签规则;
6、从预设数据库中获取原始数据;
7、使用分布式计算引擎对所述基础标签、所述衍生标签、所述第一标签规则、所述第二标签规则以及所述原始数据进行倒序排列计算,以得到标签计算结果;
8、采用至少一种存储格式对所述标签计算结果进行存储。
9、较佳的,所述采用至少一种存储格式对所述标签计算结果进行存储,包括:
10、获取所述标签的数量,并判断所述数量是否大于预设数量阈值;
11、若否,则采用第一存储格式对所述标签计算结果进行存储;
12、若是,则采用第二存储格式对所述标签计算结果进行存储。
13、较佳地,所述方法还包括:
14、通过窄表转宽表的方式将存储好的所述标签计算结果存入查询分析系统中,以对所述标签或所述衍生标签进行标签查询和/或标签分析。
15、较佳的,在从所述从前端页面上获取标签脚本之前,所述方法还包括:
16、在所述前端页面通过预设语法和在线筛选逻辑运算的组合筛选,配置所述标签脚本。
17、本发明还提供一种基于标签计算的数据存储系统,所述系统包括:
18、标签解析模块,从前端页面上获取标签脚本,并将所述标签脚本翻译成分布式计算逻辑进行数据解析,以得到若干个基础标签、与所述基础标签对应的至少一个衍生标签以及与所述基础标签对应的第一标签规则,与所述衍生标签对应的第二标签规则;
19、获取模块,从预设数据库中获取原始数据;
20、计算模块,使用分布式计算引擎对所述基础标签、所述衍生标签、所述第一标签规则、所述第二标签规则以及所述原始数据进行倒序排列计算,以得到标签计算结果;
21、存储模块,采用至少一种存储格式对所述标签计算结果进行存储。
22、较佳地,所述存储模块,获取所述标签的数量,并判断所述数量是否大于预设数量阈值;
23、若否,则采用第一存储格式对所述标签计算结果进行存储;
24、若是,则采用第二存储格式对所述标签计算结果进行存储。
25、较佳的,所述系统还包括:
26、转换模块,通过窄表转宽表的方式将存储好的所述标签计算结果存入查询分析系统中,以对所述标签或所述衍生标签进行标签查询和/或标签分析。
27、较佳的,所述系统还包括:
28、配置模块,在所述前端页面通过预设语法和在线筛选逻辑运算的组合筛选,配置所述标签脚本。
29、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行计算机程序时实现如上所述的基于标签计算的数据存储方法。
30、本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的基于标签计算的数据存储方法。
31、本发明的积极进步效果在于:通过在前端页面通过配置标签脚本,并在后续中使用分布式计算引擎对基础标签、衍生标签、第一标签规则、第二标签规则以及原始数据进行倒序排列计算,采用至少一种存储格式对标签计算结果进行存储,实现了在通过页面配置可以无限添加标签,而不影响数据库表的结构和性能,进而满足大量分布式存储的要求。
技术特征:
1.一种基于标签计算的数据存储方法,其特征在于,所述方法包括:
2.如权利要求1所述的基于标签计算的数据存储方法,其特征在于,所述采用至少一种存储格式对所述标签计算结果进行存储,包括:
3.如权利要求1或2所述的基于标签计算的数据存储方法,其特征在于,所述方法还包括:
4.如权利要求1所述的基于标签计算的数据存储方法,其特征在于,在从所述从前端页面上获取标签脚本之前,所述方法还包括:
5.一种基于标签计算的数据存储系统,其特征在于,所述系统包括:
6.如权利要求5所述的基于标签计算的数据存储系统,其特征在于,所述存储模块,获取所述标签的数量,并判断所述数量是否大于预设数量阈值;
7.如权利要求5或6所述的基于标签计算的数据存储系统,其特征在于,所述系统还包括:
8.如权利要求5所述的基于标签计算的数据存储系统,其特征在于,所述系统还包括:
9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行计算机程序时实现如权利要求1-4中任一项所述的基于标签计算的数据存储方法。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-4中任一项所述的基于标签计算的数据存储方法。
技术总结
本发明公开了一种基于标签计算的数据存储方法、系统、设备及介质。其中,基于标签计算的数据存储方法包括,从前端页面上获取标签脚本,并将标签脚本翻译成分布式计算逻辑进行数据解析,以得到若干个基础标签、衍生标签、第一标签规则、第二标签规则;从预设数据库中获取原始数据;并在后续中使用分布式计算引擎对基础标签、衍生标签、第一标签规则、第二标签规则以及原始数据进行倒序排列计算,并采用至少一种存储格式对标签计算结果进行存储,实现了在通过页面配置可以无限添加标签,而不影响数据库表的结构和性能,进而满足大量分布式存储的要求。
技术研发人员:刘志阳,曹凯周,李阳,刘家俊
受保护的技术使用者:上海吉贝克信息技术有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!