基于跨模态学习的文本和行人视频检索方法
本发明属于计算机视觉,尤其是一种基于跨模态学习的文本和行人视频检索方法。
背景技术:
1、行人视频检索的目的是能够根据目击者所提供的语言描述,在视频监控数据库中搜索并定位到目标行人。
2、如今,对于图文检索已经发展出了很成熟的技术,检索的速度和精度都得到了很好的提高,但是对于视频层面的检索技术还处于新生阶段,并且相较于图像检索更难,但是却是必要的。视频相对于图像多了时序特征,通过一段视频可以读取当前行人在某一段时间内的连续性的行为,相较于一张图像而言,富含了更多的动作特征以及图像所没有的连续的动作变化。
3、在视频检索过程中,对视频中行人特征的提取,常常会受到如背景和颜色依赖问题等因素的干扰,从而丢失一些细粒度特征而达不到较好的检索效果。
4、如果将视频中的干扰信息筛除,并且屏蔽掉颜色信息依赖对检索效果的干扰,是亟待解决的问题。
技术实现思路
1、本发明的目的是针对于背景干扰以及颜色依赖导致行人视频检索中精度下降的问题,提出一种基于跨模态学习的文本和行人视频检索方法。
2、本发明的技术方案是:
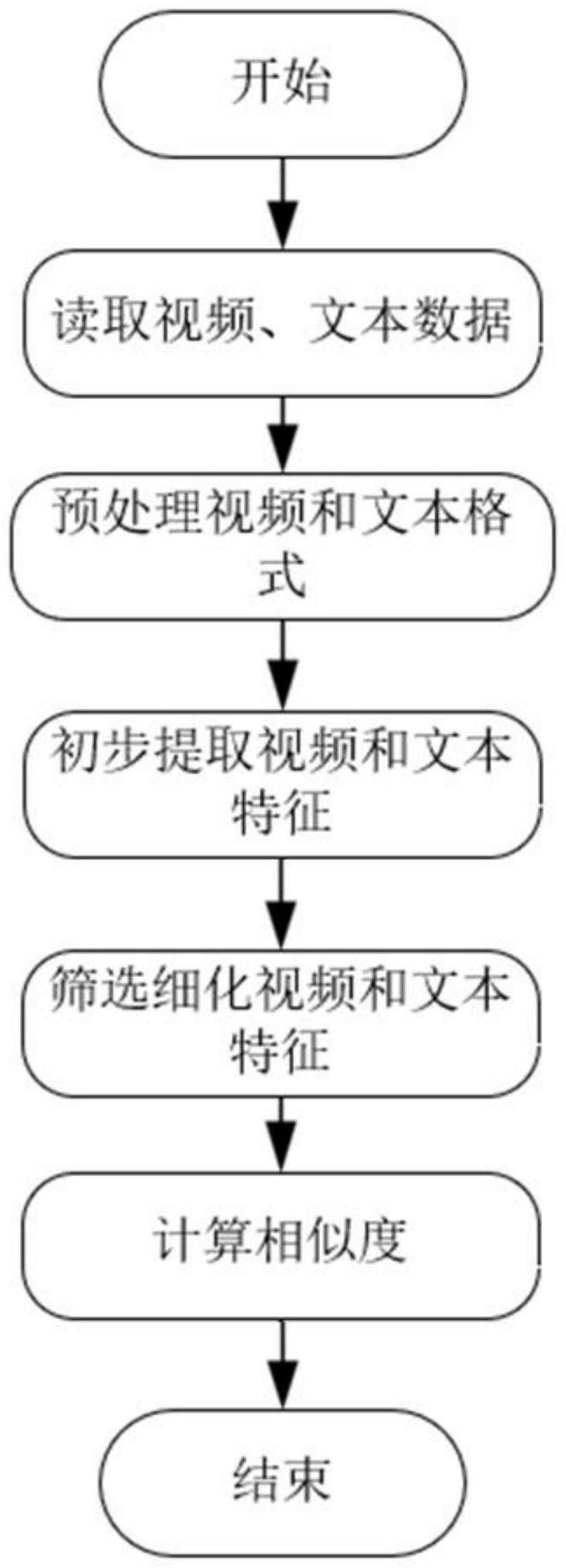
3、本发明提供一种基于跨模态学习的文本和行人视频检索方法,所述方法包括以下步骤:
4、步骤1、对多个待识别的视频分别进行灰度化处理和掩码处理得到灰度视频帧序列和掩码视频帧序列,对文本进行灰度化的过滤处理得到灰度化文本;
5、步骤2、通过视觉特征提取网络对步骤1处理后的各视频进行处理,获取各视频的三组视频全局特征,包括:原视频全局特征、灰度视频全局特征和掩码视频全局特征;通过文本编码器对步骤1处理后的文本进行训练,获取两组文本全局特征,包括原文本全局特征和灰度化文本全局特征;
6、步骤3、采用完成训练的视频检索模型捕获各视频对应的灰度视频、掩码视频和原文本中的细粒度信息,处理后得到原文本细粒度特征,各灰度视频、掩码视频的细粒度特征;基于全局特征和细粒度特征获取各视频与文本的相似度;对各视频与文本的相似度进行排序,获取相似度最高的视频作为检索结果。
7、进一步地,步骤1中对视频进行灰度化处理包括:
8、首先将视频进行抽帧处理,获得视频帧序列vo={v1,…,vn};
9、利用opencv中的灰度化函数vg对视频帧进行转换,得到灰度视频帧序列vg={vg1,…,vgn}。
10、进一步地,步骤1中对视频进行掩码处理采用视觉编码器,所述视觉编码器采用vision transformer模型,包括:
11、将视频帧序列vo={v1,…,vn}输入视觉编码器中,获取视频帧的自注意力图a,按照预设的掩码率遮掩部分图像块,获得掩码视频帧序列vm={vm1,…,vmn}。
12、进一步地,步骤1中对文本进行过滤处理包括:
13、利用nltk中的词汇标注器过滤出文本中的形容词,并对代表颜色的形容词进行筛选,用占位符[mask]替换所述代表颜色的形容词的位置,获取过滤后的文本。
14、进一步地,步骤2中视频处理具体为:采用resnet-50视觉特征提取网络分别对原视频帧序列vo、灰度视频帧序列vg和掩码视频帧序列vm进行处理,得到三组特征以及对应的自注意力图,包括原视频全局特征灰度视频全局特征掩码视频全局特征原视频自注意力图灰度视频自注意力图掩码视频自注意力图avm:
15、
16、
17、
18、进一步地,步骤2中文本编码器包括1个bert模型和1个bi-lstm,分别对原文本和灰度化文本进行编码处理,得到两组文本全局特征向量以及对应的自注意力图,包括原文本全局特征灰度化文本全局特征原文本自注意力图灰度化文本自注意力图
19、
20、
21、其中,to和tg分别为原文本和灰度化文本描述。
22、进一步地,步骤3中,细粒度特征的获取步骤为:
23、步骤31、采用下述公式对灰度视频全局特征掩码视频全局特征以及原文本全局特征进行处理,得到灰度视频、掩码视频,原文本的包含细粒度信息的自注意力图
24、
25、
26、
27、其中:表示特征维度调节系数,用于调整特征维度与一致;ω1、ω2、ω3为加权和的权重比例,分别为灰度视频自注意力图、掩码视频自注意力图和原文本自注意力图;
28、步骤32、采用softmax函数对包含细粒度信息的自注意力图进行处理,得到各自注意力图中每个令牌token所包含的信息量的排序,按照预设的百分比获取信息量高的token作为对应的灰度视频细粒度特征掩码视频细粒度特征以及原文本细粒度特征
29、进一步地,步骤3中,视频与文本的相似度获取步骤为:
30、步骤33、对任一视频的三组视频文本特征分别计算余弦相似度:
31、
32、
33、
34、其中:s1为原视频帧全局特征与原文本全局特征之间的余弦相似度,s2为灰度视频细粒度特征与灰度化文本全局特征之间的余弦相似度,s3为掩码视频细粒度特征与原文本细粒度特征的余弦相似度;
35、步骤34、采用softmax函数对三组相似度进行处理,作为各组特征的权重
36、
37、步骤35、基于各组特征的权重对三组视频全局特征进行加权和,得到有效的视频特征fv:
38、
39、步骤36、计算有效的视频特征fv与原文本细粒度特征的余弦相似度,作为该视频与文本的最终相似度s:
40、
41、进一步地,所述视频检索模型训练时采用交叉熵损失lid以及跨模态投影匹配损失cmpm、跨模态投影分类损失cmpc进行训练,最终损失采用下述公式获取:
42、loss=lid+(lcmpm+lcmpc)。
43、进一步地,所述交叉熵损失lid采用下述公式获取:
44、
45、其中,m为样本总数,i表示样本编号,一个样本包括一个视频和对应的文本,id表示视频编号,y i表示编号为i的样本所对应的真实视频编号;表示编号为i的样本所对应的预测视频编号。
46、本发明的有益效果:
47、本发明基于全局特征与局部的细粒度特征相结合的方法,将灰度与色彩相结合,从多个角度提取视频与文本的特征,解决了颜色依赖,以及视频背景信息对行人特征的干扰问题,增强了模型对于细粒度特征提取的能力。
48、本发明在提取各个特征之前,首先对视频和文本进行处理,获得包含不同特征信息的视频和文本版本,充分利用了视频和文本不同层次方面对的信息,从而提高了检索结果的准确率。
49、本发明的其它特征和优点将在随后具体实施方式部分予以详细说明。
技术特征:
1.一种基于跨模态学习的文本和行人视频检索方法,其特征在于,所述方法包括以下步骤:
2.根据权利要求1所述的基于跨模态学习的文本和行人视频检索方法,其特征在于,步骤1中对视频进行灰度化处理包括:
3.根据权利要求2所述的基于跨模态学习的文本和行人视频检索方法,其特征在于,步骤1中对视频进行掩码处理采用视觉编码器,所述视觉编码器采用vision transformer模型,包括:
4.根据权利要求1所述的基于跨模态学习的文本和行人视频检索方法,其特征在于,步骤1中对文本进行过滤处理包括:
5.根据权利要求1所述的基于跨模态学习的文本和行人视频检索方法,其特征在于步骤2中视频处理具体为:采用resnet-50视觉特征提取网络分别对原视频帧序列vo、灰度视频帧序列vg和掩码视频帧序列vm进行处理,得到三组特征以及对应的自注意力图,包括原视频全局特征灰度视频全局特征掩码视频全局特征原视频自注意力图灰度视频自注意力图掩码视频自注意力图
6.根据权利要求1所述的基于跨模态学习的文本和行人视频检索方法,其特征在于:步骤2中文本编码器包括1个bert模型和1个bi-lstm,分别对原文本和灰度化文本进行编码处理,得到两组文本全局特征向量以及对应的自注意力图,包括原文本全局特征灰度化文本全局特征原文本自注意力图灰度化文本自注意力图
7.根据权利要求1所述的基于跨模态学习的文本和行人视频检索方法,其特征在于步骤3中细粒度特征的获取步骤为:
8.根据权利要求1所述的基于跨模态学习的文本和行人视频检索方法,其特征在于步骤3中,视频与文本的相似度获取步骤为:
9.根据权利要求1所述的基于跨模态学习的文本和行人视频检索方法,,其特征在于,所述视频检索模型训练时采用交叉熵损失lid以及跨模态投影匹配损失cmpm、跨模态投影分类损失cmpc进行训练,最终损失采用下述公式获取:
10.根据权利要求9所述的基于跨模态学习的文本和行人视频检索方法,,其特征在于,所述交叉熵损失lid采用下述公式获取:
技术总结
本发明提供了一种基于跨模态学习的文本和行人视频检索方法,对多个待识别的视频分别进行灰度化处理和掩码处理,对文本进行灰度化的过滤处理;通过视觉特征提取网络对各视频进行处理获取三组视频全局特征,通过文本编码器对文本进行处理获取两组文本全局特征;采用完成训练的视频检索模型捕获细粒度信息;基于全局特征和细粒度特征获取各视频与文本的相似度;对各视频与文本的相似度进行排序,获取相似度最高的视频作为检索结果。本发明针对目前视频检索方法中对于视频中行人特征的细节不够以及颜色依赖问题导致的干扰进行了改善,选择灰度与彩色视频帧相结合以及全局与局部相结合的方式,细化了行人特征和文本特征,提高模型的检索精度。
技术研发人员:朱艾春,张旭,董冠男,倪帆,胡方强
受保护的技术使用者:南京工业大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!