依赖识别模型的训练方法、概念的推送方法、装置及设备
本发明属于模型训练,尤其涉及一种依赖识别模型的训练方法、概念的推送方法、装置及设备。
背景技术:
1、学习资源中的知识概念间的依赖关系决定了每个资源在整个课程中学习顺序。当前主流的概念依赖关系挖掘方法是利用概念自身的特征进行依赖关系的识别。talukdar和cohen,提出了建模维基百科概念的先决结构的早期尝试。对于一对概念,作者使用超链接、编辑和页面内容来定义特征,然后使用maxent分类器来推断概念之间的先决条件关系。liang等人提出了一种基于超链接的方法来推断维基百科概念之间的先决条件关系。他们根据参考距离(refd)计算先决条件,其中维基百科的超链接作为概念之间的“参考关系”。zhou和xiao创建了四组可进行先决条件发现的特征,包括基于链接的特征、基于类别的特征、基于内容的特征和基于时间的特征。
2、上述方法都是基于维基百科概念本身的特征进行概念依赖关系预测。sayyadiharikandeh等人首次利用用户交互行为预测概念对间的依赖关系,但是,此方法的主要问题在于,用户日志所覆盖的维基百科概念对的比例过于偏低,我们无法利用它来预测大多数维基百科概念对间的依赖关系。所以,概念对之间依赖关系的识别准确率低是亟待解决的技术问题。
技术实现思路
1、本发明实施例提供了一种依赖识别模型的训练方法、概念的推送方法、装置及设备,解决了概念对之间依赖关系的识别准确率低的技术问题。
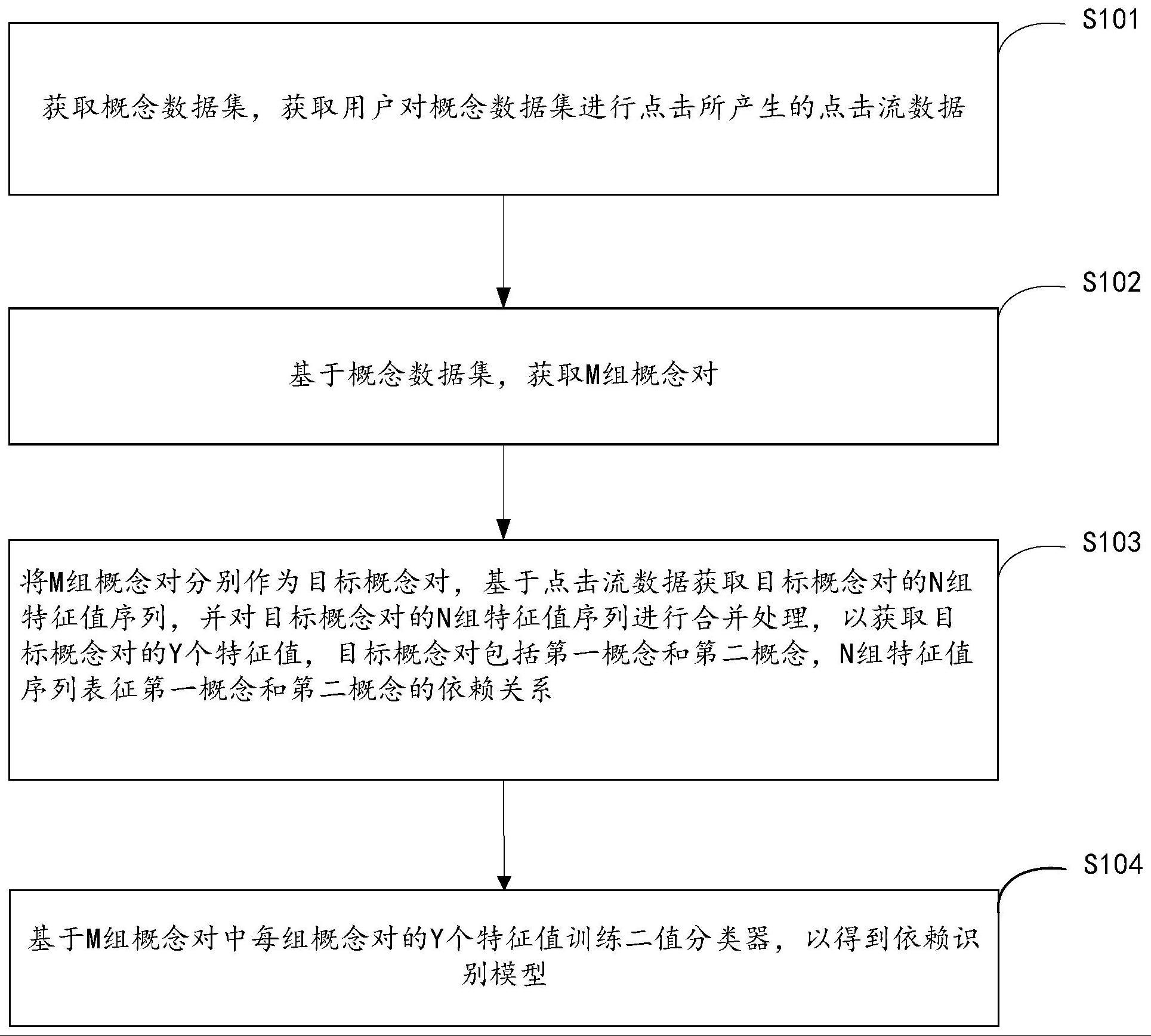
2、第一方面,本发明实施例提供了一种依赖识别模型的训练方法,包括:获取概念数据集,获取用户对所述概念数据集进行点击所产生的点击流数据;基于所述概念数据集,获取m组概念对;将所述m组概念对分别作为目标概念对,基于所述点击流数据获取所述目标概念对的n组特征值序列,并对所述目标概念对的n组特征值序列进行合并处理,以获取所述目标概念对的y个特征值,所述目标概念对包括第一概念和第二概念,所述n组特征值序列表征所述第一概念和所述第二概念的依赖关系;基于所述m组概念对中每组概念对的y个特征值训练二值分类器,以得到依赖识别模型。
3、结合本发明的第一方面,在一些实施方式下,所述基于所述点击流数据获取所述目标概念对的n组特征值序列,包括:通过分析所述点击流数据,获取所述目标概念对的第一组特征值序列,所述第一组特征值序列表征所述第一概念与所述第二概念的直接依赖关系;通过分析所述点击流数据,获取所述目标概念对的第二组特征值序列,所述第二组特征值序列表征所述第一概念的相关概念数据集与所述第二概念的依赖关系;通过分析所述点击流数据,获取所述目标概念对的第三组特征值序列,所述第三组特征值序列表征所述第二概念的相关概念数据集与所述第一概念的依赖关系;通过分析所述点击流数据,获取所述目标概念对的第四组特征值序列,所述第四组特征值序列表征所述第一概念的相关概念数据集与所述第二概念的相关概念数据集的依赖关系。
4、结合本发明的第一方面,在一些实施方式下,所述对所述目标概念对的n组特征值序列进行合并处理,以获取所述目标概念对的y个特征值,包括:根据所述目标概念对的n组特征值序列的特征值类型,对所述目标概念对的n组特征值序列进行重新分组,得到y组特征值,所述y组特征值中同一组内特征值的类型相同;对所述y组特征值中e组特征值进行合并,得到e个特征值;对所述y组特征值中f组特征值进行合并,得到f个特征值,所述f组特征值为二进制类型的数据,所述e组特征值为除所述f组特征值之外的特征值;基于所述e个特征值和所述f个特征值合成所述目标概念对的y个特征值。
5、结合本发明的第一方面,在一些实施方式下,所述对所述y组特征值中e组特征值进行合并,得到e个特征值,包括:确定多个权重系数;基于所述多个权重系数,对所述e组特征值中每组特征值分别进行合并运算,得到所述e个特征值。
6、结合本发明的第一方面,在一些实施方式下,所述对所述y组特征值中f组特征值进行合并,得到f个特征值,包括:获取所述f组特征值中每组特征值的加和结果;基于所述f组特征值中每组特征值的加和结果,得到所述f个特征值。
7、结合本发明的第一方面,在一些实施方式下,所述基于所述f组特征值中每组特征值的加和结果,得到所述f个特征值,包括:如果所述f组特征值的第一组特征值的加和结果大于预设数值阈值,将所述f个特征值的第一个特征值赋值为1;如果所述f组特征值的第一组特征值的加和结果不大于所述预设数值阈值,将所述f个特征值的第一个特征值赋值为0。
8、第二方面,本发明实施例提供了一种概念的推送方法,包括:获取用户的当前学习概念;基于依赖识别模型处理所述当前学习概念,确定出用户的概念学习路径,所述学习路径包括所述当前学习概念的依赖概念,以及相对于所述依赖概念的依赖概念,所述依赖识别模型是基于第一方面中任一项所述的依赖识别模型的训练方法训练得到的;基于所述概念学习路径,响应于用户完成了所述当前学习概念,向用户推送需要进行学习的下一个概念。
9、结合本发明的第二方面,在一些实施方式下,在所述确定出用户的概念学习路径之后,还包括:基于所述概念学习路径,向用户一次性推送待学习的全部概念,以及所述待学习的全部概念的先后学习顺序的建议。
10、第三方面,本发明实施例提供了一种依赖识别模型的训练装置,包括:数据获取单元,用于获取概念数据集,获取用户对所述概念数据集进行点击所产生的点击流数据;概念对获取单元,用于基于所述概念数据集,获取m组概念对;特征值获取单元,用于将所述m组概念对分别作为目标概念对,基于所述点击流数据获取所述目标概念对的n组特征值序列,并对所述目标概念对的n组特征值序列进行合并处理,以获取所述目标概念对的y个特征值,所述目标概念对包括第一概念和第二概念,所述n组特征值序列表征所述第一概念和所述第二概念的依赖关系;训练单元,用于基于所述m组概念对中每组概念对的y个特征值训练二值分类器,以得到依赖识别模型。
11、第四方面,本发明实施例提供了一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现第一方面和第二方面中任一项所述方法。
12、本发明实施例提供的一个或者多个技术方案,至少实现了如下技术效果或者优点:
13、本发明实施例通过获取概念数据集,获取用户对概念数据集进行点击所产生的点击流数据;基于概念数据集,获取m组概念对;将m组概念对分别作为目标概念对,基于点击流数据获取目标概念对的n组特征值序列,并对目标概念对的n组特征值序列进行合并处理,以获取目标概念对的y个特征值,目标概念对包括第一概念和第二概念,n组特征值序列表征第一概念和第二概念的依赖关系;基于m组概念对中每组概念对的y个特征值训练二值分类器,以得到依赖识别模型。通过训练后的依赖识别模型可以识别概念对之间的依赖关系,所以,提高了概念对之间依赖关系的识别准确率。
技术特征:
1.一种依赖识别模型的训练方法,其特征在于,包括:
2.根据权利要求1所述的依赖识别模型的训练方法,其特征在于,所述基于所述点击流数据获取所述目标概念对的n组特征值序列,包括:
3.根据权利要求1所述的依赖识别模型的训练方法,其特征在于,所述对所述目标概念对的n组特征值序列进行合并处理,以获取所述目标概念对的y个特征值,包括:
4.根据权利要求3所述的依赖识别模型的训练方法,其特征在于,所述对所述y组特征值中e组特征值进行合并,得到e个特征值,包括:
5.根据权利要求3所述的依赖识别模型的训练方法,其特征在于,所述对所述y组特征值中f组特征值进行合并,得到f个特征值,包括:
6.根据权利要求5所述的依赖识别模型的训练方法,其特征在于,所述基于所述f组特征值中每组特征值的加和结果,得到所述f个特征值,包括:
7.一种概念的推送方法,其特征在于,包括:
8.根据权利要求7所述的概念的推送方法,其特征在于,在所述确定出用户的概念学习路径之后,还包括:
9.一种依赖识别模型的训练装置,其特征在于,包括:
10.一种电子设备,其特征在于,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现权利要求1-8中任一项所述方法。
技术总结
本发明公开了一种依赖识别模型的训练方法、概念的推送方法、装置及设备,该方法包括:获取概念数据集,获取用户对概念数据集进行点击所产生的点击流数据;基于概念数据集,获取M组概念对;将M组概念对分别作为目标概念对,基于点击流数据获取目标概念对的N组特征值序列,并对目标概念对的N组特征值序列进行合并处理,以获取目标概念对的Y个特征值,目标概念对包括第一概念和第二概念,N组特征值序列表征第一概念和第二概念的依赖关系;基于M组概念对中每组概念对的Y个特征值训练二值分类器,以得到依赖识别模型。通过本发明解决了概念对之间依赖关系的识别准确率低的技术问题。
技术研发人员:肖奎,陈昊,左壮,崔海波,胡成
受保护的技术使用者:湖北大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!