一种语料数据增强方法及设备与流程
本申请涉及自然语言处理,尤其涉及一种语料数据增强方法及设备。
背景技术:
1、在自然语言处理方面的语料数据增强中,有着传统的文本分类任务的简易数据扩充(easy data augmentation for text classification tasks,eda)方法,例如同义词替换、随机替换、随机插入、随机删除;也有着根据基于transformer构建的双向语义编码表征模型(bidirectional encoder representations from transformers,bert)等基于深度学习的语料数据增强方法。
2、然而传统eda方法在进行同义词替换、随机替换等替换时,容易对输入的文本中的重要内容进行替换,导致生成的文本不连贯,或失去了句子原本的意思。而在使用bert进行语料数据增强时,可以产生大量的文本,但是同样也无法保证输入的文本中的重要内容仍然保留在生成的文本中。也就是说,现有的语料数据增强方法难以保证增强后的文本与输入的文本的一致性。
技术实现思路
1、本申请提供了一种语料数据增强方法及设备,用以解决现有技术的语料数据增强方法难以保证增强后的文本与输入的文本的一致性的问题。
2、第一方面,本申请实施例提供了一种语料数据增强方法,所述方法包括:
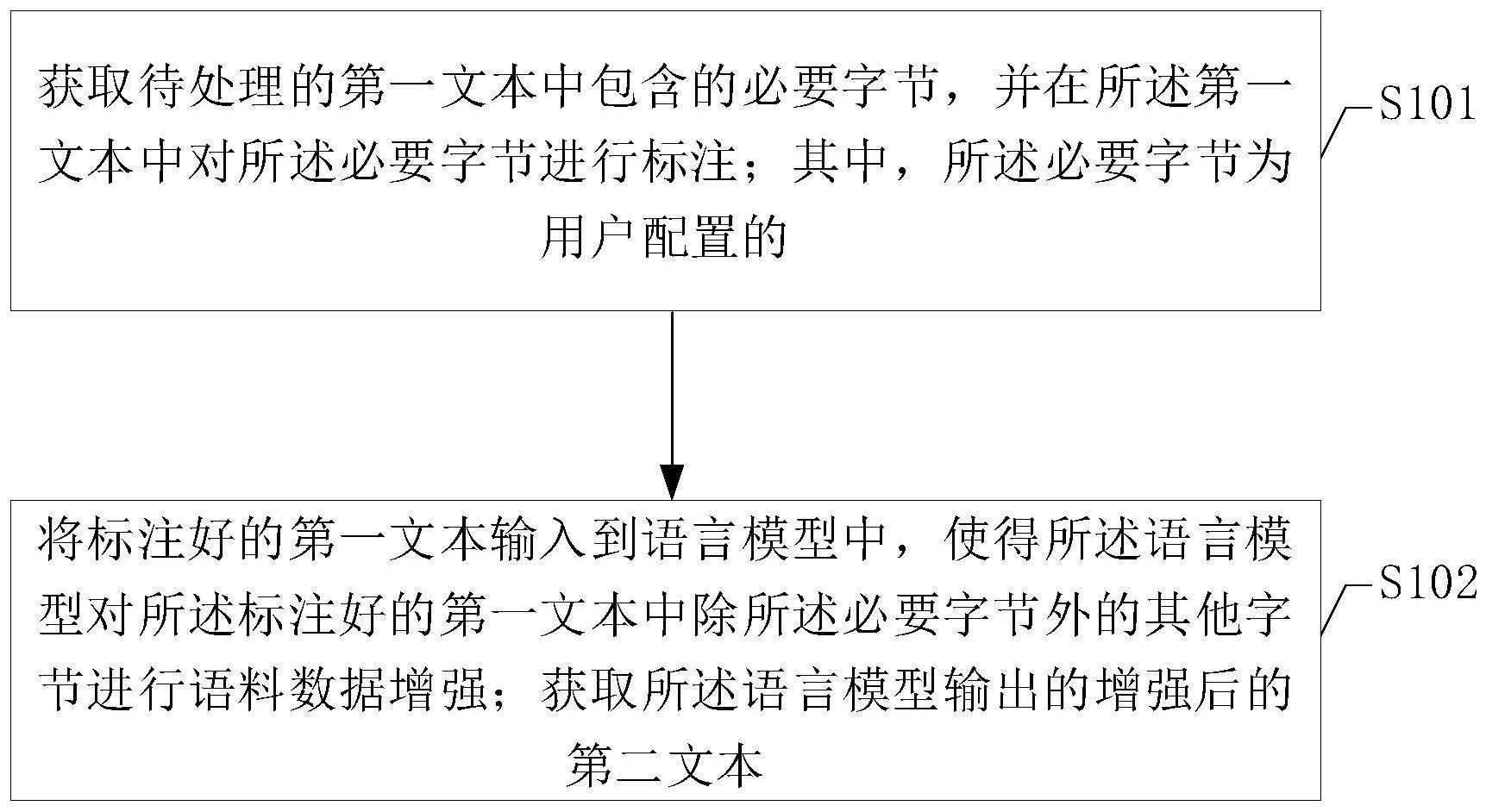
3、获取待处理的第一文本中包含的必要字节,并在所述第一文本中对所述必要字节进行标注;其中,所述必要字节为用户配置的;
4、将标注好的第一文本输入到语言模型中,使得所述语言模型对所述标注好的第一文本中除所述必要字节外的其他字节进行语料数据增强;
5、获取所述语言模型输出的增强后的第二文本。
6、第二方面,本申请实施例还提供了一种电子设备,所述电子设备包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现如上述所述语料数据增强方法的步骤。
7、在本申请实施例中,电子设备获取待处理的第一文本中包含的必要字节,并在该第一文本中对该必要字节进行标注;其中,该必要字节为用户配置的;将标注好的第一文本输入到语言模型中,使得该语言模型对该标注好的第一文本中除该必要字节外的其他字节进行语料数据增强;获取该语言模型输出的增强后的第二文本。在本申请实施例中,电子设备通过获取用户配置的待处理的第一文本对应的必要字节,对第一文本进行标注,使得语言模型在进行语料数据增强时可以对第一文本中除必要字节外的其他字节,进行语料数据增强,实现了在语料数据增强的同时,增强后得到的第二文本中仍然会包含第一文本中的必要字节,实现了增强后的文本与输入的文本的一致性,提高了语料数据增强的效果。
技术特征:
1.一种语料数据增强方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述语言模型对所述标注好的第一文本进行语料数据增强包括:
3.根据权利要求2所述的方法,其特征在于,所述语言模型的生成器对所述标注好的第一文本中除所述必要字节外的其他字节进行遮掩mask操作包括:
4.根据权利要求2所述的方法,其特征在于,所述获取所述语言模型输出的增强后的第二文本包括:
5.根据权利要求2所述的方法,其特征在于,所述获取所述语言模型输出的增强后的第二文本包括:
6.根据权利要求5所述的方法,其特征在于,所述方法还包括:
7.根据权利要求5所述的方法,其特征在于,所述判别器确定所述候选文本与所述第一文本的相似度包括:
8.根据权利要求1所述的方法,其特征在于,所述语言模型的训练过程包括:
9.根据权利要求8所述的方法,其特征在于,所述语言模型的判别器为预先训练好的。
10.一种电子设备,其特征在于,所述电子设备包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现如权利要求1-9任一所述语料数据增强方法的步骤。
技术总结
本申请涉及自然语言处理技术领域,尤其涉及一种语料数据增强方法及设备,在本申请实施例中,电子设备通过获取用户配置的待处理的第一文本对应的必要字节,对第一文本进行标注,使得语言模型在进行语料数据增强时可以对第一文本中除必要字节外的其他字节,进行语料数据增强,实现了在语料数据增强的同时,增强后得到的第二文本中仍然会包含第一文本中的必要字节,实现了增强后的文本与输入的文本的一致性,提高了语料数据增强的效果。
技术研发人员:宋骋,陈维强,刘微,孟卫明,杜兆臣,刘敏
受保护的技术使用者:海信集团控股股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!